Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster and More Accurate Trace-based Policy Evaluation via Overall Target Error Meta-Optimization
Paper and Code

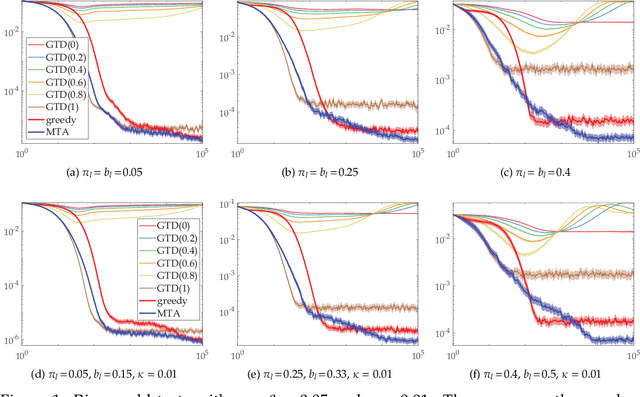
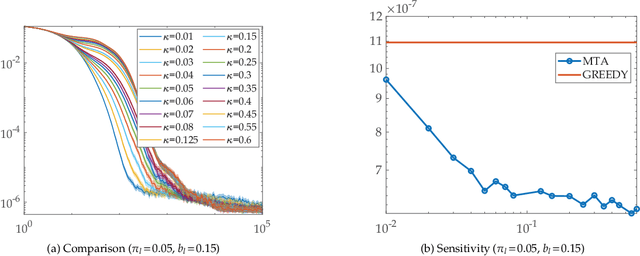
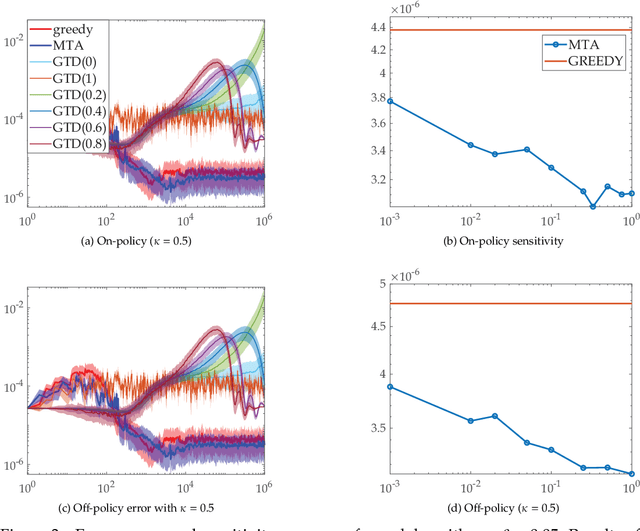
To improve the speed and accuracy of the trace based policy evaluation method TD({\lambda}), under appropriate assumptions, we derive and propose an off-policy compatible method of meta-learning state-based {\lambda}'s online with efficient incremental updates. Furthermore, we prove the derived bias-variance tradeoff minimization method, with slight adjustments, is equivalent to minimizing the overall target error in terms of state based {\lambda}'s. In experiments, the method shows significantly better performance when compared to the existing method and the baselines.
* NIPS2019, Under Review
View paper on