Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Pre-training Induce Systematic Inference? How Masked Language Models Acquire Commonsense Knowledge
Paper and Code
Dec 16, 2021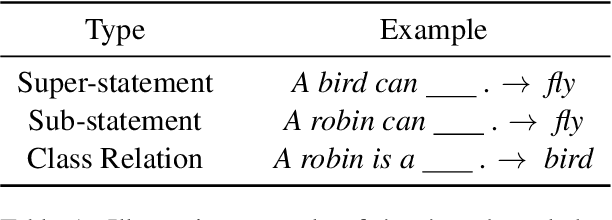
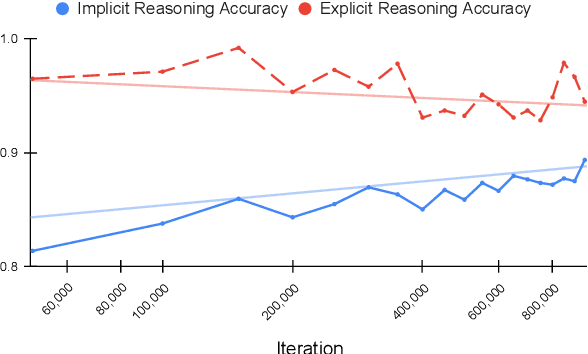
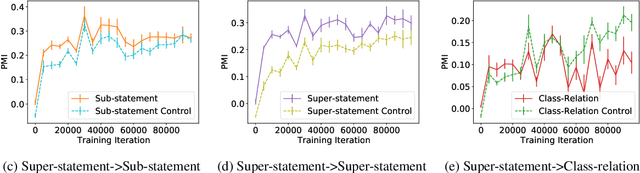
Transformer models pre-trained with a masked-language-modeling objective (e.g., BERT) encode commonsense knowledge as evidenced by behavioral probes; however, the extent to which this knowledge is acquired by systematic inference over the semantics of the pre-training corpora is an open question. To answer this question, we selectively inject verbalized knowledge into the minibatches of a BERT model during pre-training and evaluate how well the model generalizes to supported inferences. We find generalization does not improve over the course of pre-training, suggesting that commonsense knowledge is acquired from surface-level, co-occurrence patterns rather than induced, systematic reasoning.
View paper on