 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Evaluation of Common-Sense Reasoning in Natural Language Understanding
Paper and Code


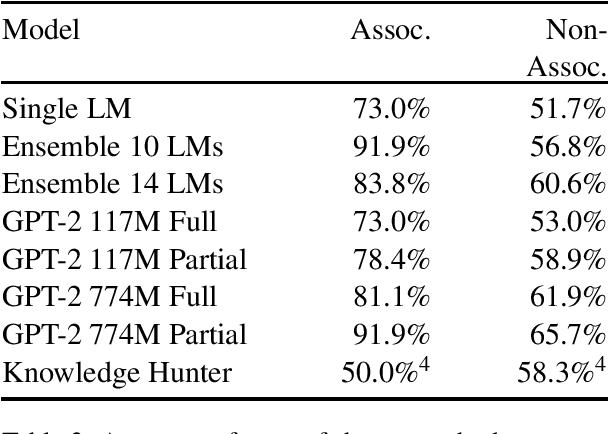
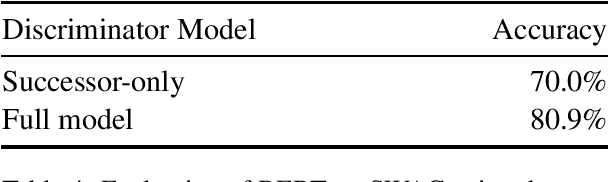
The NLP and ML communities have long been interested in developing models capable of common-sense reasoning, and recent works have significantly improved the state of the art on benchmarks like the Winograd Schema Challenge (WSC). Despite these advances, the complexity of tasks designed to test common-sense reasoning remains under-analyzed. In this paper, we make a case study of the Winograd Schema Challenge and, based on two new measures of instance-level complexity, design a protocol that both clarifies and qualifies the results of previous work. Our protocol accounts for the WSC's limited size and variable instance difficulty, properties common to other common-sense benchmarks. Accounting for these properties when assessing model results may prevent unjustified conclusions.