 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating AI-generated code for C++, Fortran, Go, Java, Julia, Matlab, Python, R, and Rust
May 21, 2024This study evaluates the capabilities of ChatGPT versions 3.5 and 4 in generating code across a diverse range of programming languages. Our objective is to assess the effectiveness of these AI models for generating scientific programs. To this end, we asked ChatGPT to generate three distinct codes: a simple numerical integration, a conjugate gradient solver, and a parallel 1D stencil-based heat equation solver. The focus of our analysis was on the compilation, runtime performance, and accuracy of the codes. While both versions of ChatGPT successfully created codes that compiled and ran (with some help), some languages were easier for the AI to use than others (possibly because of the size of the training sets used). Parallel codes -- even the simple example we chose to study here -- also difficult for the AI to generate correctly.
Storm Surge Modeling in the AI ERA: Using LSTM-based Machine Learning for Enhancing Forecasting Accuracy
Mar 07, 2024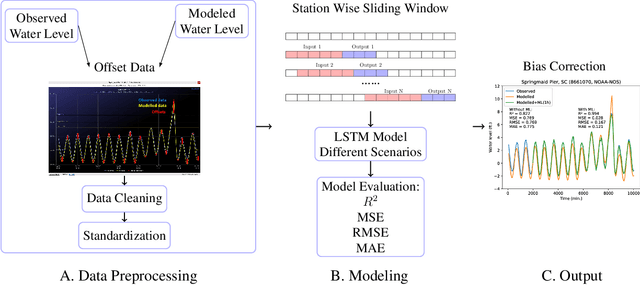
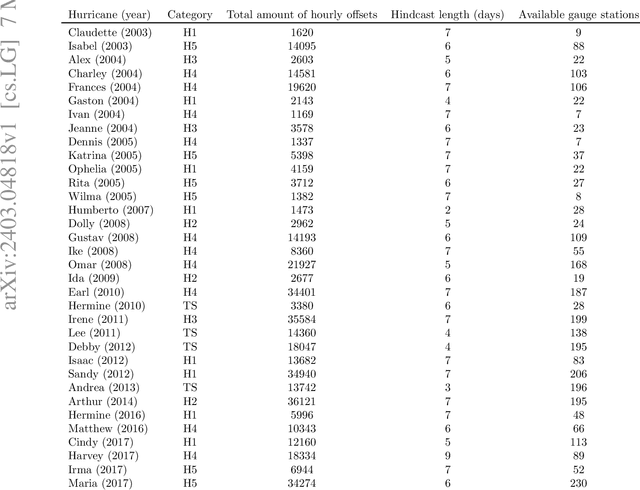
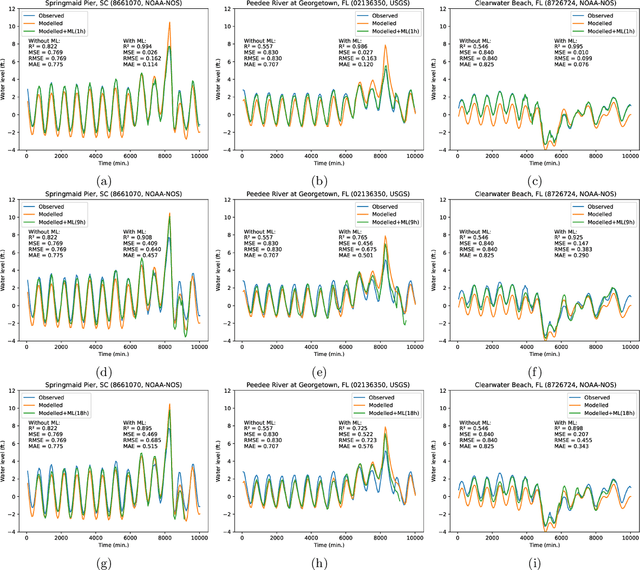
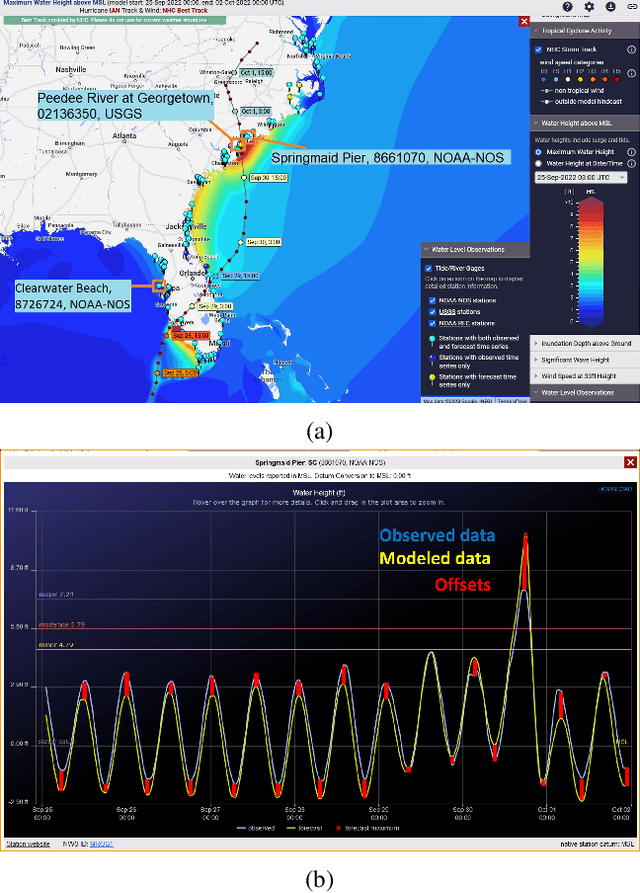
Physics simulation results of natural processes usually do not fully capture the real world. This is caused for instance by limits in what physical processes are simulated and to what accuracy. In this work we propose and analyze the use of an LSTM-based deep learning network machine learning (ML) architecture for capturing and predicting the behavior of the systemic error for storm surge forecast models with respect to real-world water height observations from gauge stations during hurricane events. The overall goal of this work is to predict the systemic error of the physics model and use it to improve the accuracy of the simulation results post factum. We trained our proposed ML model on a dataset of 61 historical storms in the coastal regions of the U.S. and we tested its performance in bias correcting modeled water level data predictions from hurricane Ian (2022). We show that our model can consistently improve the forecasting accuracy for hurricane Ian -- unknown to the ML model -- at all gauge station coordinates used for the initial data. Moreover, by examining the impact of using different subsets of the initial training dataset, containing a number of relatively similar or different hurricanes in terms of hurricane track, we found that we can obtain similar quality of bias correction by only using a subset of six hurricanes. This is an important result that implies the possibility to apply a pre-trained ML model to real-time hurricane forecasting results with the goal of bias correcting and improving the produced simulation accuracy. The presented work is an important first step in creating a bias correction system for real-time storm surge forecasting applicable to the full simulation area. It also presents a highly transferable and operationally applicable methodology for improving the accuracy in a wide range of physics simulation scenarios beyond storm surge forecasting.
Towards a Scalable and Distributed Infrastructure for Deep Learning Applications
Oct 06, 2020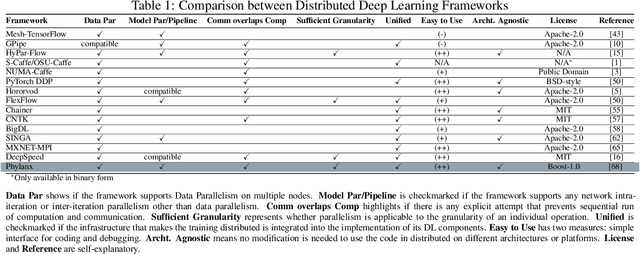
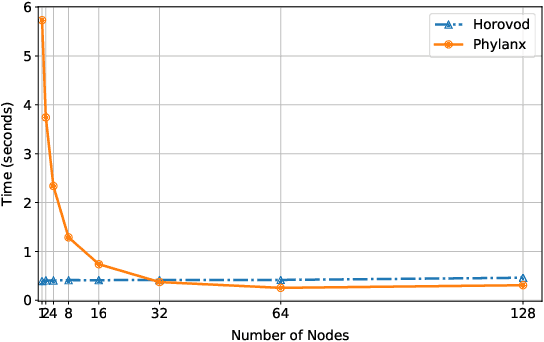
Although recent scaling up approaches to train deep neural networks have proven to be effective, the computational intensity of large and complex models, as well as the availability of large-scale datasets require deep learning frameworks to utilize scaling out techniques. Parallelization approaches and distribution requirements are not considered in the primary designs of most available distributed deep learning frameworks and most of them still are not able to perform effective and efficient fine-grained inter-node communication. We present Phylanx that has the potential to alleviate these shortcomings. Phylanx presents a productivity-oriented frontend where user Python code is translated to a futurized execution tree that can be executed efficiently on multiple nodes using the C++ standard library for parallelism and concurrency (HPX), leveraging fine-grained threading and an active messaging task-based runtime system.
HPX Smart Executors
Nov 05, 2017



The performance of many parallel applications depends on loop-level parallelism. However, manually parallelizing all loops may result in degrading parallel performance, as some of them cannot scale desirably to a large number of threads. In addition, the overheads of manually tuning loop parameters might prevent an application from reaching its maximum parallel performance. We illustrate how machine learning techniques can be applied to address these challenges. In this research, we develop a framework that is able to automatically capture the static and dynamic information of a loop. Moreover, we advocate a novel method by introducing HPX smart executors for determining the execution policy, chunk size, and prefetching distance of an HPX loop to achieve higher possible performance by feeding static information captured during compilation and runtime-based dynamic information to our learning model. Our evaluated execution results show that using these smart executors can speed up the HPX execution process by around 12%-35% for the Matrix Multiplication, Stream and $2D$ Stencil benchmarks compared to setting their HPX loop's execution policy/parameters manually or using HPX auto-parallelization techniques.