 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Scalable and Distributed Infrastructure for Deep Learning Applications
Paper and Code
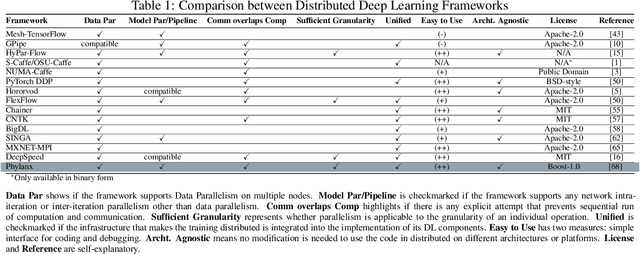
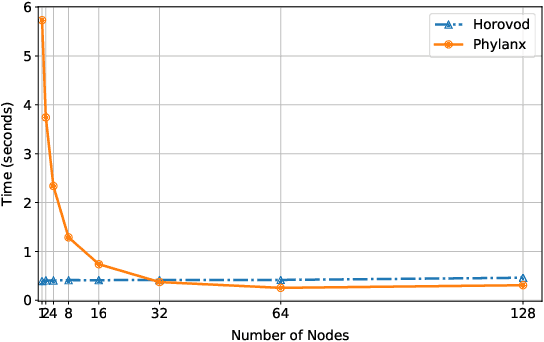
Although recent scaling up approaches to train deep neural networks have proven to be effective, the computational intensity of large and complex models, as well as the availability of large-scale datasets require deep learning frameworks to utilize scaling out techniques. Parallelization approaches and distribution requirements are not considered in the primary designs of most available distributed deep learning frameworks and most of them still are not able to perform effective and efficient fine-grained inter-node communication. We present Phylanx that has the potential to alleviate these shortcomings. Phylanx presents a productivity-oriented frontend where user Python code is translated to a futurized execution tree that can be executed efficiently on multiple nodes using the C++ standard library for parallelism and concurrency (HPX), leveraging fine-grained threading and an active messaging task-based runtime system.