 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaguna M.1/XS.2 Technical Report
May 26, 2026We present Laguna M.1 and Laguna XS.2, two Mixture-of-Experts foundation models built for long-horizon, agentic coding: M.1 has $225.8$B total parameters ($23.4$B activated per token) and XS.2 has $33.4$B total ($3$B activated). Both models were trained from scratch end-to-end inside the same internal system that we refer to as our Model Factory: a tightly-integrated stack of versioned data, training, evaluation, and inference components that turn model development into an industrial process. We describe the principles and design choices of the Model Factory and also detail the end-to-end training process of our models, throughout pre-training data and architecture, post-training stages, evaluation, and quantization. On agentic software engineering and terminal benchmarks (SWE-bench Verified, SWE-bench Multilingual, SWE-Bench Pro, and Terminal-Bench 2.0) M.1 and XS.2 are competitive with state-of-the-art open models in their respective weight classes. Laguna XS.2 weights are released under Apache~2.0 at https://huggingface.co/collections/poolside/laguna-xs2.
Falcon2-11B Technical Report
Jul 20, 2024



We introduce Falcon2-11B, a foundation model trained on over five trillion tokens, and its multimodal counterpart, Falcon2-11B-vlm, which is a vision-to-text model. We report our findings during the training of the Falcon2-11B which follows a multi-stage approach where the early stages are distinguished by their context length and a final stage where we use a curated, high-quality dataset. Additionally, we report the effect of doubling the batch size mid-training and how training loss spikes are affected by the learning rate. The downstream performance of the foundation model is evaluated on established benchmarks, including multilingual and code datasets. The foundation model shows strong generalization across all the tasks which makes it suitable for downstream finetuning use cases. For the vision language model, we report the performance on several benchmarks and show that our model achieves a higher average score compared to open-source models of similar size. The model weights and code of both Falcon2-11B and Falcon2-11B-vlm are made available under a permissive license.
The Falcon Series of Open Language Models
Nov 29, 2023



We introduce the Falcon series: 7B, 40B, and 180B parameters causal decoder-only models trained on a diverse high-quality corpora predominantly assembled from web data. The largest model, Falcon-180B, has been trained on over 3.5 trillion tokens of text--the largest openly documented pretraining run. Falcon-180B significantly outperforms models such as PaLM or Chinchilla, and improves upon concurrently developed models such as LLaMA 2 or Inflection-1. It nears the performance of PaLM-2-Large at a reduced pretraining and inference cost, making it, to our knowledge, one of the three best language models in the world along with GPT-4 and PaLM-2-Large. We report detailed evaluations, as well as a deep dive into the methods and custom tooling employed to pretrain Falcon. Notably, we report on our custom distributed training codebase, allowing us to efficiently pretrain these models on up to 4,096 A100s on cloud AWS infrastructure with limited interconnect. We release a 600B tokens extract of our web dataset, as well as the Falcon-7/40/180B models under a permissive license to foster open-science and accelerate the development of an open ecosystem of large language models.
The RefinedWeb Dataset for Falcon LLM: Outperforming Curated Corpora with Web Data, and Web Data Only
Jun 01, 2023



Large language models are commonly trained on a mixture of filtered web data and curated high-quality corpora, such as social media conversations, books, or technical papers. This curation process is believed to be necessary to produce performant models with broad zero-shot generalization abilities. However, as larger models requiring pretraining on trillions of tokens are considered, it is unclear how scalable is curation and whether we will run out of unique high-quality data soon. At variance with previous beliefs, we show that properly filtered and deduplicated web data alone can lead to powerful models; even significantly outperforming models from the state-of-the-art trained on The Pile. Despite extensive filtering, the high-quality data we extract from the web is still plentiful, and we are able to obtain five trillion tokens from CommonCrawl. We publicly release an extract of 600 billion tokens from our RefinedWeb dataset, and 1.3/7.5B parameters language models trained on it.
State, global and local parameter estimation using local ensemble Kalman filters: applications to online machine learning of chaotic dynamics
Jul 26, 2021
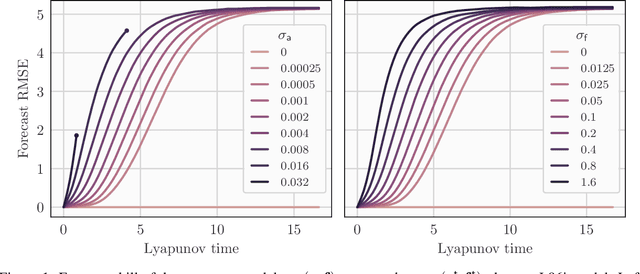

In a recent methodological paper, we have shown how to learn chaotic dynamics along with the state trajectory from sequentially acquired observations, using local ensemble Kalman filters. Here, we more systematically investigate the possibilty to use a local ensemble Kalman filter with either covariance localization or local domains, in order to retrieve the state and a mix of key global and local parameters. Global parameters are meant to represent the surrogate dynamics, for instance through a neural network, which is reminiscent of data-driven machine learning of dynamics, while the local parameters typically stand for the forcings of the model. A family of algorithms for covariance and local domain localization is proposed in this joint state and parameter filter context. In particular, we show how to rigorously update global parameters using a local domain EnKF such as the LETKF, an inherently local method. The approach is tested with success on the 40-variable Lorenz model using several of the local EnKF flavors. A two-dimensional illustration based on a multi-layer Lorenz model is finally provided. It uses radiance-like non-local observations, and both local domains and covariance localization in order to learn the chaotic dynamics, the local forcings, and the couplings between layers. This paper more generally addresses the key question of online estimation of both global and local model parameters.
A comparison of combined data assimilation and machine learning methods for offline and online model error correction
Jul 23, 2021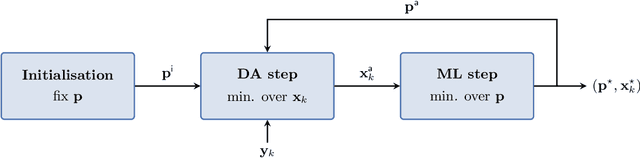

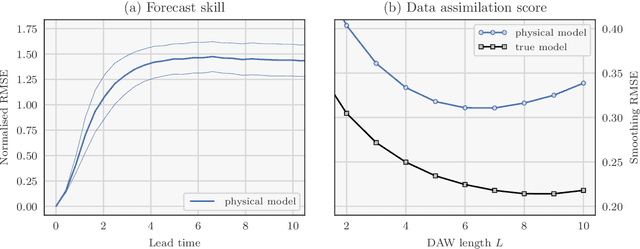

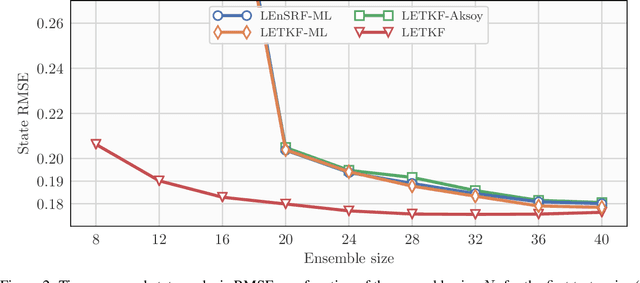
Recent studies have shown that it is possible to combine machine learning methods with data assimilation to reconstruct a dynamical system using only sparse and noisy observations of that system. The same approach can be used to correct the error of a knowledge-based model. The resulting surrogate model is hybrid, with a statistical part supplementing a physical part. In practice, the correction can be added as an integrated term (i.e. in the model resolvent) or directly inside the tendencies of the physical model. The resolvent correction is easy to implement. The tendency correction is more technical, in particular it requires the adjoint of the physical model, but also more flexible. We use the two-scale Lorenz model to compare the two methods. The accuracy in long-range forecast experiments is somewhat similar between the surrogate models using the resolvent correction and the tendency correction. By contrast, the surrogate models using the tendency correction significantly outperform the surrogate models using the resolvent correction in data assimilation experiments. Finally, we show that the tendency correction opens the possibility to make online model error correction, i.e. improving the model progressively as new observations become available. The resulting algorithm can be seen as a new formulation of weak-constraint 4D-Var. We compare online and offline learning using the same framework with the two-scale Lorenz system, and show that with online learning, it is possible to extract all the information from sparse and noisy observations.
Online learning of both state and dynamics using ensemble Kalman filters
Jun 06, 2020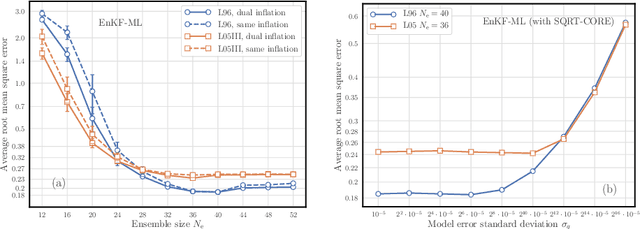
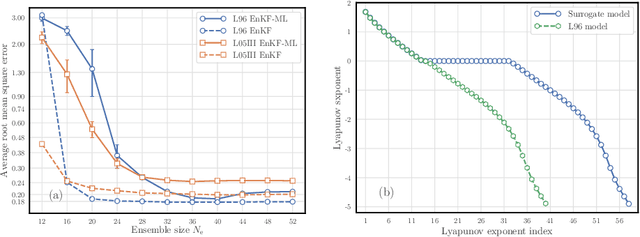
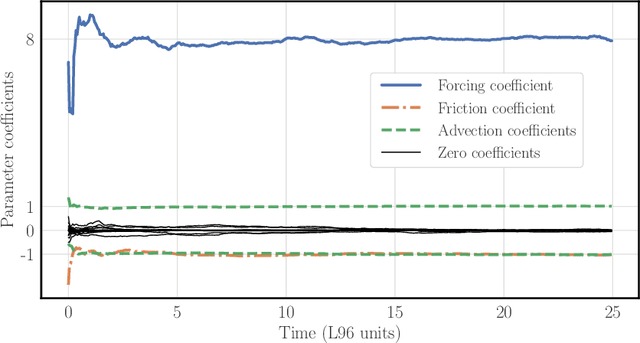
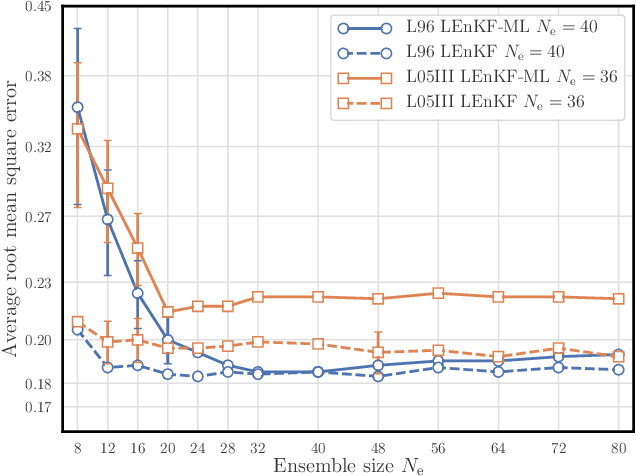
The reconstruction of the dynamics of an observed physical system as a surrogate model has been brought to the fore by recent advances in machine learning. To deal with partial and noisy observations in that endeavor, machine learning representations of the surrogate model can be used within a Bayesian data assimilation framework. However, these approaches require to consider long time series of observational data, meant to be assimilated all together. This paper investigates the possibility to learn both the dynamics and the state online, i.e. to update their estimates at any time, in particular when new observations are acquired. The estimation is based on the ensemble Kalman filter (EnKF) family of algorithms using a rather simple representation for the surrogate model and state augmentation. We consider the implication of learning dynamics online through (i) a global EnKF, (i) a local EnKF and (iii) an iterative EnKF and we discuss in each case issues and algorithmic solutions. We then demonstrate numerically the efficiency and assess the accuracy of these methods using one-dimensional, one-scale and two-scale chaotic Lorenz models.