 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Falcon Series of Open Language Models
Nov 29, 2023



We introduce the Falcon series: 7B, 40B, and 180B parameters causal decoder-only models trained on a diverse high-quality corpora predominantly assembled from web data. The largest model, Falcon-180B, has been trained on over 3.5 trillion tokens of text--the largest openly documented pretraining run. Falcon-180B significantly outperforms models such as PaLM or Chinchilla, and improves upon concurrently developed models such as LLaMA 2 or Inflection-1. It nears the performance of PaLM-2-Large at a reduced pretraining and inference cost, making it, to our knowledge, one of the three best language models in the world along with GPT-4 and PaLM-2-Large. We report detailed evaluations, as well as a deep dive into the methods and custom tooling employed to pretrain Falcon. Notably, we report on our custom distributed training codebase, allowing us to efficiently pretrain these models on up to 4,096 A100s on cloud AWS infrastructure with limited interconnect. We release a 600B tokens extract of our web dataset, as well as the Falcon-7/40/180B models under a permissive license to foster open-science and accelerate the development of an open ecosystem of large language models.
The RefinedWeb Dataset for Falcon LLM: Outperforming Curated Corpora with Web Data, and Web Data Only
Jun 01, 2023



Large language models are commonly trained on a mixture of filtered web data and curated high-quality corpora, such as social media conversations, books, or technical papers. This curation process is believed to be necessary to produce performant models with broad zero-shot generalization abilities. However, as larger models requiring pretraining on trillions of tokens are considered, it is unclear how scalable is curation and whether we will run out of unique high-quality data soon. At variance with previous beliefs, we show that properly filtered and deduplicated web data alone can lead to powerful models; even significantly outperforming models from the state-of-the-art trained on The Pile. Despite extensive filtering, the high-quality data we extract from the web is still plentiful, and we are able to obtain five trillion tokens from CommonCrawl. We publicly release an extract of 600 billion tokens from our RefinedWeb dataset, and 1.3/7.5B parameters language models trained on it.
PAGnol: An Extra-Large French Generative Model
Oct 16, 2021
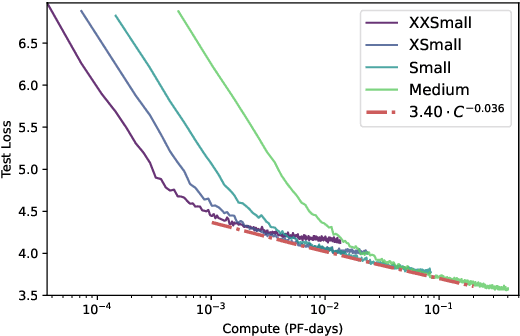

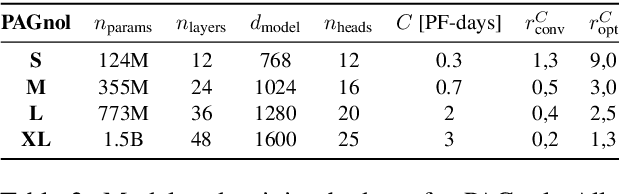
Access to large pre-trained models of varied architectures, in many different languages, is central to the democratization of NLP. We introduce PAGnol, a collection of French GPT models. Using scaling laws, we efficiently train PAGnol-XL (1.5B parameters) with the same computational budget as CamemBERT, a model 13 times smaller. PAGnol-XL is the largest model trained to date for the French language. We plan to train increasingly large and performing versions of PAGnol, exploring the capabilities of French extreme-scale models. For this first release, we focus on the pre-training and scaling calculations underlining PAGnol. We fit a scaling law for compute for the French language, and compare it with its English counterpart. We find the pre-training dataset significantly conditions the quality of the outputs, with common datasets such as OSCAR leading to low-quality offensive text. We evaluate our models on discriminative and generative tasks in French, comparing to other state-of-the-art French and multilingual models, and reaching the state of the art in the abstract summarization task. Our research was conducted on the public GENCI Jean Zay supercomputer, and our models up to the Large are made publicly available.
Pre-training Is All You Need: An Application to Commonsense Reasoning
Apr 29, 2020



Fine-tuning of pre-trained transformer models has become the standard approach for solving common NLP tasks. Most of the existing approaches rely on a randomly initialized classifier on top of such networks. We argue that this fine-tuning procedure is sub-optimal as the pre-trained model has no prior on the specific classifier labels, while it might have already learned an intrinsic textual representation of the task. In this paper, we introduce a new scoring method that casts a plausibility ranking task in a full-text format and leverages the masked language modeling head tuned during the pre-training phase. We study commonsense reasoning tasks where the model must rank a set of hypotheses given a premise, focusing on the COPA, Swag, HellaSwag and CommonsenseQA datasets. By exploiting our scoring method without fine-tuning, we are able to produce strong baselines (e.g. 80% test accuracy on COPA) that are comparable to supervised approaches. Moreover, when fine-tuning directly on the proposed scoring function, we show that our method provides a much more stable training phase across random restarts (e.g $\times 10$ standard deviation reduction on COPA test accuracy) and requires less annotated data than the standard classifier approach to reach equivalent performances.