 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAGnol: An Extra-Large French Generative Model
Oct 16, 2021
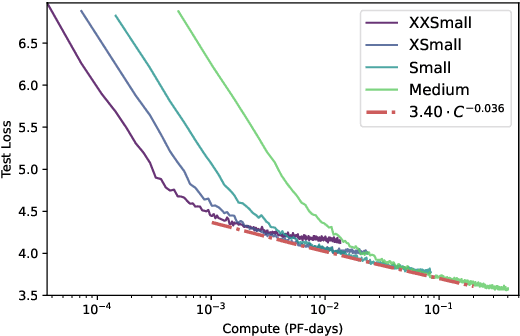

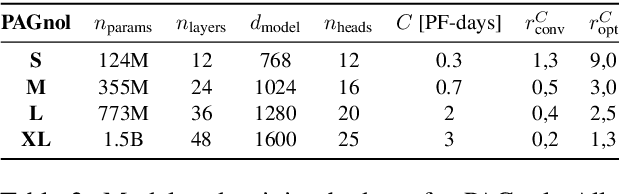
Access to large pre-trained models of varied architectures, in many different languages, is central to the democratization of NLP. We introduce PAGnol, a collection of French GPT models. Using scaling laws, we efficiently train PAGnol-XL (1.5B parameters) with the same computational budget as CamemBERT, a model 13 times smaller. PAGnol-XL is the largest model trained to date for the French language. We plan to train increasingly large and performing versions of PAGnol, exploring the capabilities of French extreme-scale models. For this first release, we focus on the pre-training and scaling calculations underlining PAGnol. We fit a scaling law for compute for the French language, and compare it with its English counterpart. We find the pre-training dataset significantly conditions the quality of the outputs, with common datasets such as OSCAR leading to low-quality offensive text. We evaluate our models on discriminative and generative tasks in French, comparing to other state-of-the-art French and multilingual models, and reaching the state of the art in the abstract summarization task. Our research was conducted on the public GENCI Jean Zay supercomputer, and our models up to the Large are made publicly available.
Direct Feedback Alignment Scales to Modern Deep Learning Tasks and Architectures
Jun 23, 2020
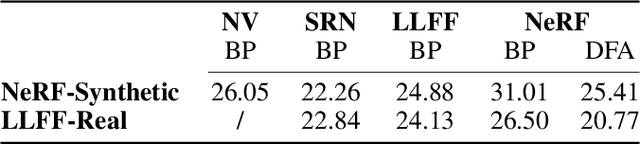


Despite being the workhorse of deep learning, the backpropagation algorithm is no panacea. It enforces sequential layer updates, thus preventing efficient parallelization of the training process. Furthermore, its biological plausibility is being challenged. Alternative schemes have been devised; yet, under the constraint of synaptic asymmetry, none have scaled to modern deep learning tasks and architectures. Here, we challenge this perspective, and study the applicability of Direct Feedback Alignment to neural view synthesis, recommender systems, geometric learning, and natural language processing. In contrast with previous studies limited to computer vision tasks, our findings show that it successfully trains a large range of state-of-the-art deep learning architectures, with performance close to fine-tuned backpropagation. At variance with common beliefs, our work supports that challenging tasks can be tackled in the absence of weight transport.