 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking the Multilingual Reasoning Gap with Layer Swap
May 26, 2026Recent reasoning Large Language Models produce a chain-of-thought (CoT) predominantly in English, even when prompted in non-English languages. Prior work suggests that forcing the CoT to remain in the input language (\emph{native reasoning}) substantially degrades performance relative to allowing the model to reason in English before answering in the input language (\emph{English-pivoted reasoning}). However, most studies of this native reasoning gap rely on inference-time interventions or limited native-language training data. We revisit this comparison at a larger scale and under comparable supervision. We construct long multilingual reasoning datasets across six languages (English, French, German, Spanish, Chinese and Swahili); fine-tune specialists in both native and English-pivoted regimes on top of \texttt{Qwen/Qwen3-8B-Base}, and evaluate across mathematics, science, general knowledge, and code. In this setting, the average native reasoning gap shrinks to 1.9--3.5\% across the five non-English languages, considerably smaller than previously reported. Weight-space analysis of the native specialists reveals aligned fine-tuning updates in the middle layers and divergence in the outer layers. This points to a largely language-agnostic reasoning core surrounded by language-specific layers. Exploiting this structure, we introduce a Layer Swap: transferring the English specialist's stronger reasoning mid-layers into each native specialist, closing most of the native reasoning gap across the five non-English languages while preserving CoT in the target language. We release all models and datasets.
ColBERT-Zero: To Pre-train Or Not To Pre-train ColBERT models
Feb 18, 2026Current state-of-the-art multi-vector models are obtained through a small Knowledge Distillation (KD) training step on top of strong single-vector models, leveraging the large-scale pre-training of these models. In this paper, we study the pre-training of multi-vector models and show that large-scale multi-vector pre-training yields much stronger multi-vector models. Notably, a fully ColBERT-pre-trained model, ColBERT-Zero, trained only on public data, outperforms GTE-ModernColBERT as well as its base model, GTE-ModernBERT, which leverages closed and much stronger data, setting new state-of-the-art for model this size. We also find that, although performing only a small KD step is not enough to achieve results close to full pre-training, adding a supervised step beforehand allows to achieve much closer performance while skipping the most costly unsupervised phase. Finally, we find that aligning the fine-tuning and pre-training setups is crucial when repurposing existing models. To enable exploration of our results, we release various checkpoints as well as code used to train them.
PAGnol: An Extra-Large French Generative Model
Oct 16, 2021
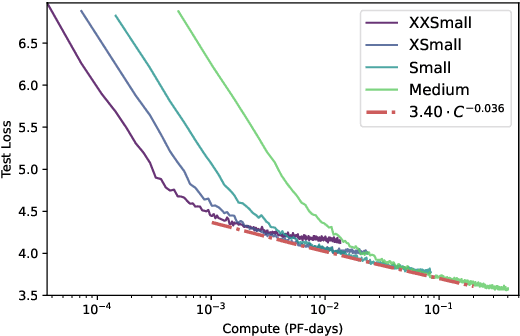

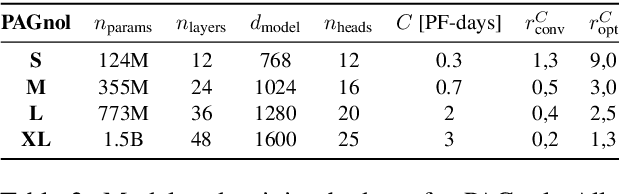
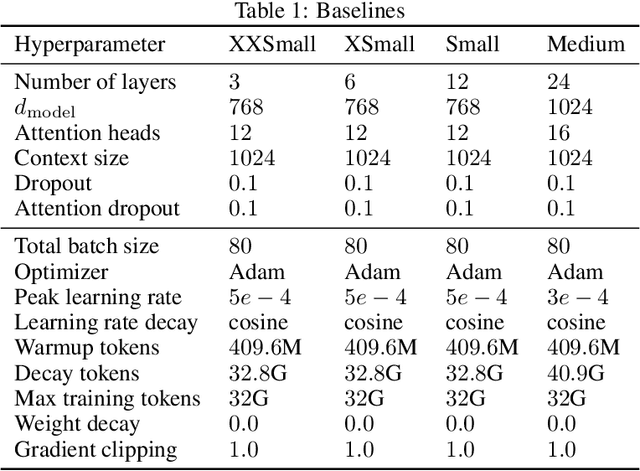
Access to large pre-trained models of varied architectures, in many different languages, is central to the democratization of NLP. We introduce PAGnol, a collection of French GPT models. Using scaling laws, we efficiently train PAGnol-XL (1.5B parameters) with the same computational budget as CamemBERT, a model 13 times smaller. PAGnol-XL is the largest model trained to date for the French language. We plan to train increasingly large and performing versions of PAGnol, exploring the capabilities of French extreme-scale models. For this first release, we focus on the pre-training and scaling calculations underlining PAGnol. We fit a scaling law for compute for the French language, and compare it with its English counterpart. We find the pre-training dataset significantly conditions the quality of the outputs, with common datasets such as OSCAR leading to low-quality offensive text. We evaluate our models on discriminative and generative tasks in French, comparing to other state-of-the-art French and multilingual models, and reaching the state of the art in the abstract summarization task. Our research was conducted on the public GENCI Jean Zay supercomputer, and our models up to the Large are made publicly available.
Is the Number of Trainable Parameters All That Actually Matters?
Sep 24, 2021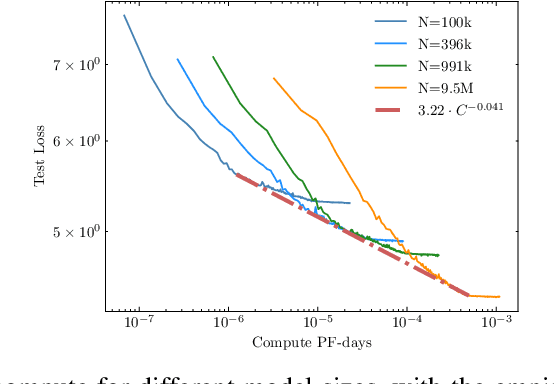
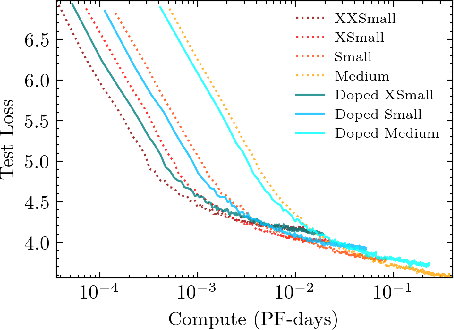
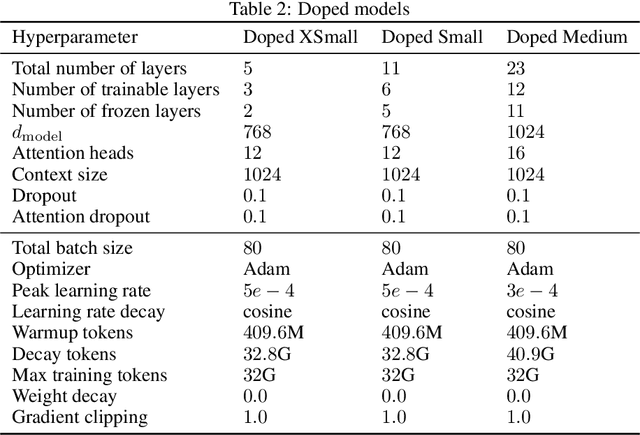
Recent work has identified simple empirical scaling laws for language models, linking compute budget, dataset size, model size, and autoregressive modeling loss. The validity of these simple power laws across orders of magnitude in model scale provides compelling evidence that larger models are also more capable models. However, scaling up models under the constraints of hardware and infrastructure is no easy feat, and rapidly becomes a hard and expensive engineering problem. We investigate ways to tentatively cheat scaling laws, and train larger models for cheaper. We emulate an increase in effective parameters, using efficient approximations: either by doping the models with frozen random parameters, or by using fast structured transforms in place of dense linear layers. We find that the scaling relationship between test loss and compute depends only on the actual number of trainable parameters; scaling laws cannot be deceived by spurious parameters.
Online Change Point Detection in Molecular Dynamics With Optical Random Features
Jun 17, 2020

Proteins are made of atoms constantly fluctuating, but can occasionally undergo large-scale changes. Such transitions are of biological interest, linking the structure of a protein to its function with a cell. Atomic-level simulations, such as Molecular Dynamics (MD), are used to study these events. However, molecular dynamics simulations produce time series with multiple observables, while changes often only affect a few of them. Therefore, detecting conformational changes has proven to be challenging for most change-point detection algorithms. In this work, we focus on the identification of such events given many noisy observables. In particular, we show that the No-prior-Knowledge Exponential Weighted Moving Average (NEWMA) algorithm can be used along optical hardware to successfully identify these changes in real-time. Our method does not need to distinguish between the background of a protein and the protein itself. For larger simulations, it is faster than using traditional silicon hardware and has a lower memory footprint. This technique may enhance the sampling of the conformational space of molecules. It may also be used to detect change-points in other sequential data with a large number of features.