 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-Scale AI in Telecom: Charting the Roadmap for Innovation, Scalability, and Enhanced Digital Experiences
Mar 06, 2025



This white paper discusses the role of large-scale AI in the telecommunications industry, with a specific focus on the potential of generative AI to revolutionize network functions and user experiences, especially in the context of 6G systems. It highlights the development and deployment of Large Telecom Models (LTMs), which are tailored AI models designed to address the complex challenges faced by modern telecom networks. The paper covers a wide range of topics, from the architecture and deployment strategies of LTMs to their applications in network management, resource allocation, and optimization. It also explores the regulatory, ethical, and standardization considerations for LTMs, offering insights into their future integration into telecom infrastructure. The goal is to provide a comprehensive roadmap for the adoption of LTMs to enhance scalability, performance, and user-centric innovation in telecom networks.
Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference
Dec 19, 2024



Encoder-only transformer models such as BERT offer a great performance-size tradeoff for retrieval and classification tasks with respect to larger decoder-only models. Despite being the workhorse of numerous production pipelines, there have been limited Pareto improvements to BERT since its release. In this paper, we introduce ModernBERT, bringing modern model optimizations to encoder-only models and representing a major Pareto improvement over older encoders. Trained on 2 trillion tokens with a native 8192 sequence length, ModernBERT models exhibit state-of-the-art results on a large pool of evaluations encompassing diverse classification tasks and both single and multi-vector retrieval on different domains (including code). In addition to strong downstream performance, ModernBERT is also the most speed and memory efficient encoder and is designed for inference on common GPUs.
RITA: a Study on Scaling Up Generative Protein Sequence Models
May 11, 2022
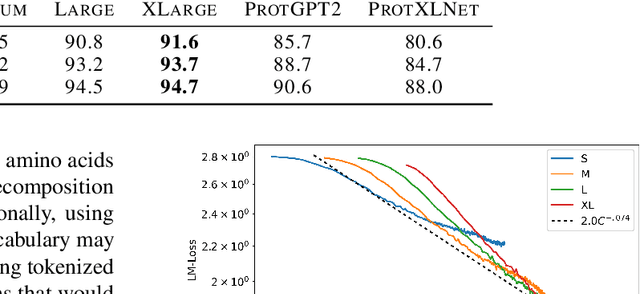


In this work we introduce RITA: a suite of autoregressive generative models for protein sequences, with up to 1.2 billion parameters, trained on over 280 million protein sequences belonging to the UniRef-100 database. Such generative models hold the promise of greatly accelerating protein design. We conduct the first systematic study of how capabilities evolve with model size for autoregressive transformers in the protein domain: we evaluate RITA models in next amino acid prediction, zero-shot fitness, and enzyme function prediction, showing benefits from increased scale. We release the RITA models openly, to the benefit of the research community.
PAGnol: An Extra-Large French Generative Model
Oct 16, 2021
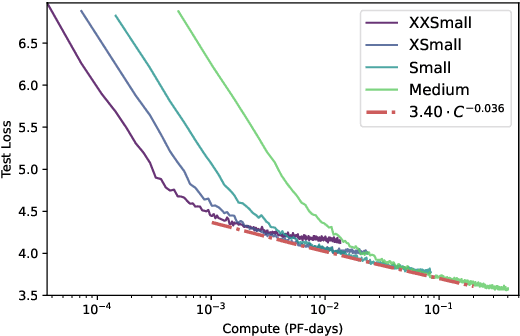

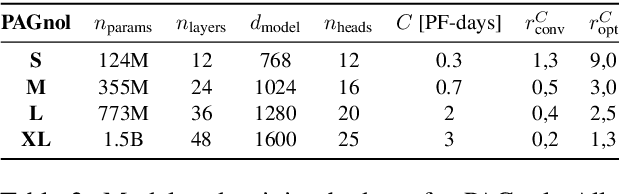
Access to large pre-trained models of varied architectures, in many different languages, is central to the democratization of NLP. We introduce PAGnol, a collection of French GPT models. Using scaling laws, we efficiently train PAGnol-XL (1.5B parameters) with the same computational budget as CamemBERT, a model 13 times smaller. PAGnol-XL is the largest model trained to date for the French language. We plan to train increasingly large and performing versions of PAGnol, exploring the capabilities of French extreme-scale models. For this first release, we focus on the pre-training and scaling calculations underlining PAGnol. We fit a scaling law for compute for the French language, and compare it with its English counterpart. We find the pre-training dataset significantly conditions the quality of the outputs, with common datasets such as OSCAR leading to low-quality offensive text. We evaluate our models on discriminative and generative tasks in French, comparing to other state-of-the-art French and multilingual models, and reaching the state of the art in the abstract summarization task. Our research was conducted on the public GENCI Jean Zay supercomputer, and our models up to the Large are made publicly available.
Is the Number of Trainable Parameters All That Actually Matters?
Sep 24, 2021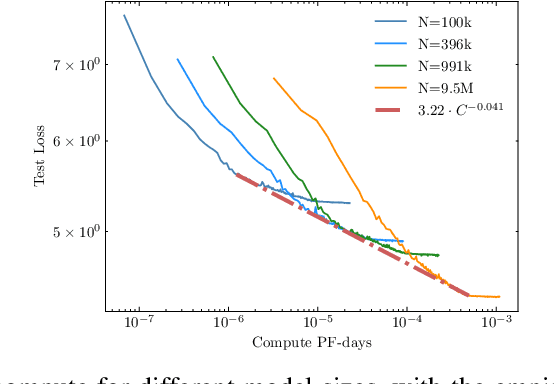
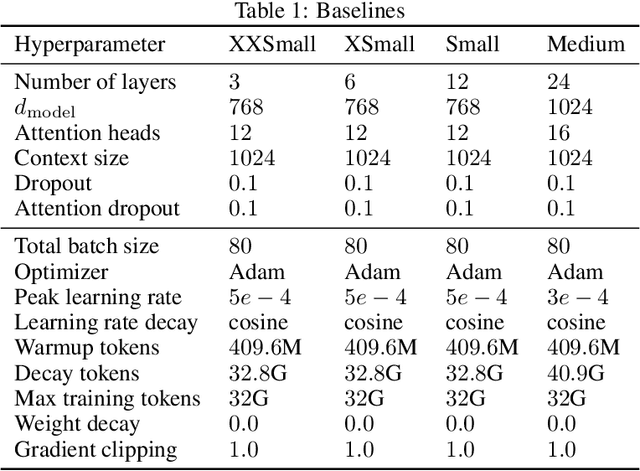
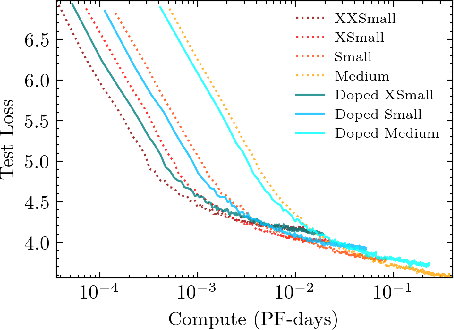
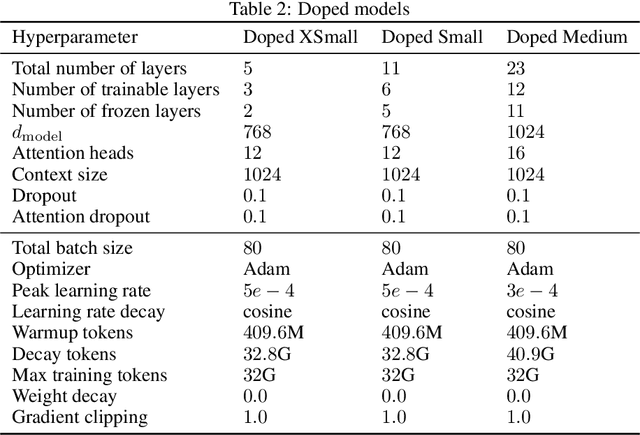
Recent work has identified simple empirical scaling laws for language models, linking compute budget, dataset size, model size, and autoregressive modeling loss. The validity of these simple power laws across orders of magnitude in model scale provides compelling evidence that larger models are also more capable models. However, scaling up models under the constraints of hardware and infrastructure is no easy feat, and rapidly becomes a hard and expensive engineering problem. We investigate ways to tentatively cheat scaling laws, and train larger models for cheaper. We emulate an increase in effective parameters, using efficient approximations: either by doping the models with frozen random parameters, or by using fast structured transforms in place of dense linear layers. We find that the scaling relationship between test loss and compute depends only on the actual number of trainable parameters; scaling laws cannot be deceived by spurious parameters.
Photonic Differential Privacy with Direct Feedback Alignment
Jun 07, 2021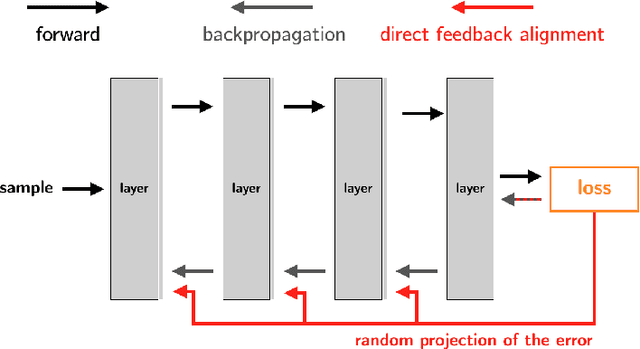
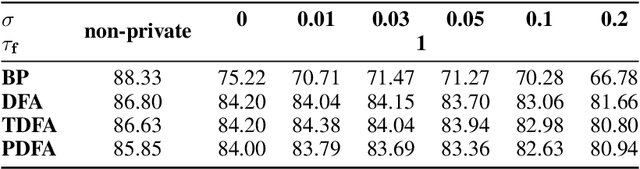
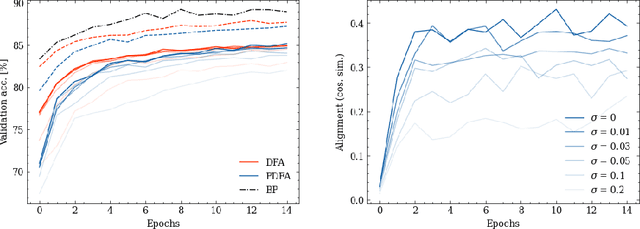
Optical Processing Units (OPUs) -- low-power photonic chips dedicated to large scale random projections -- have been used in previous work to train deep neural networks using Direct Feedback Alignment (DFA), an effective alternative to backpropagation. Here, we demonstrate how to leverage the intrinsic noise of optical random projections to build a differentially private DFA mechanism, making OPUs a solution of choice to provide a private-by-design training. We provide a theoretical analysis of our adaptive privacy mechanism, carefully measuring how the noise of optical random projections propagates in the process and gives rise to provable Differential Privacy. Finally, we conduct experiments demonstrating the ability of our learning procedure to achieve solid end-task performance.
Photonic co-processors in HPC: using LightOn OPUs for Randomized Numerical Linear Algebra
May 07, 2021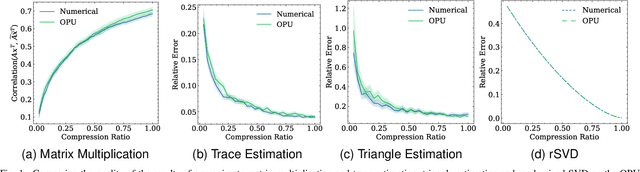
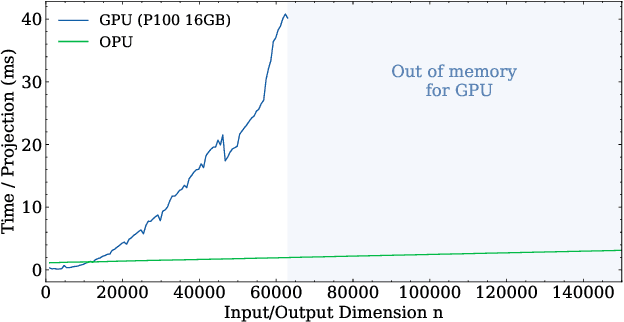
Randomized Numerical Linear Algebra (RandNLA) is a powerful class of methods, widely used in High Performance Computing (HPC). RandNLA provides approximate solutions to linear algebra functions applied to large signals, at reduced computational costs. However, the randomization step for dimensionality reduction may itself become the computational bottleneck on traditional hardware. Leveraging near constant-time linear random projections delivered by LightOn Optical Processing Units we show that randomization can be significantly accelerated, at negligible precision loss, in a wide range of important RandNLA algorithms, such as RandSVD or trace estimators.
Contrastive Embeddings for Neural Architectures
Feb 08, 2021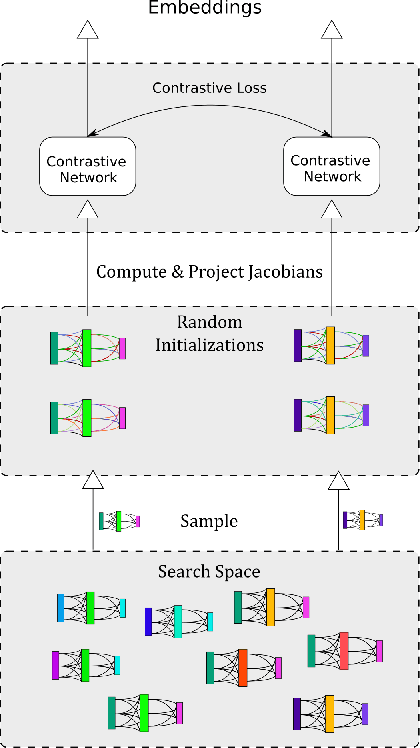

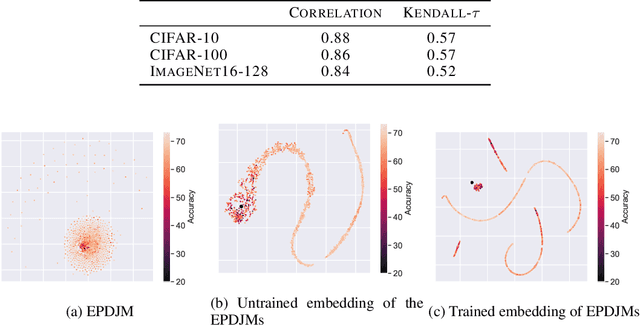
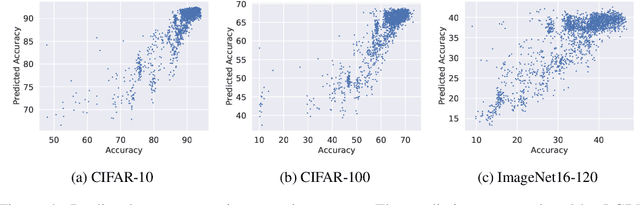
The performance of algorithms for neural architecture search strongly depends on the parametrization of the search space. We use contrastive learning to identify networks across different initializations based on their data Jacobians, and automatically produce the first architecture embeddings independent from the parametrization of the search space. Using our contrastive embeddings, we show that traditional black-box optimization algorithms, without modification, can reach state-of-the-art performance in Neural Architecture Search. As our method provides a unified embedding space, we perform for the first time transfer learning between search spaces. Finally, we show the evolution of embeddings during training, motivating future studies into using embeddings at different training stages to gain a deeper understanding of the networks in a search space.
Adversarial Robustness by Design through Analog Computing and Synthetic Gradients
Jan 06, 2021
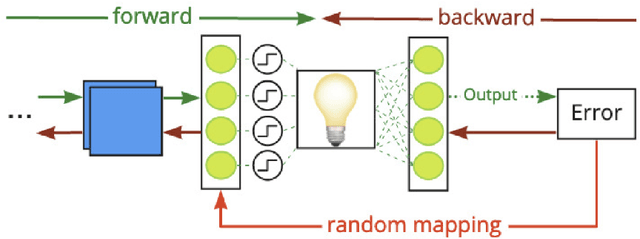
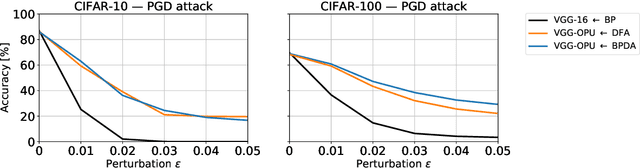
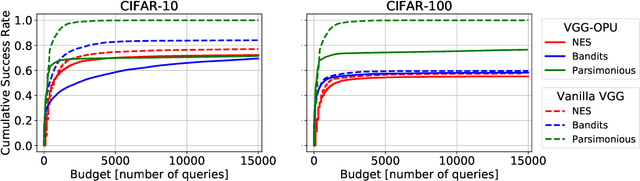
We propose a new defense mechanism against adversarial attacks inspired by an optical co-processor, providing robustness without compromising natural accuracy in both white-box and black-box settings. This hardware co-processor performs a nonlinear fixed random transformation, where the parameters are unknown and impossible to retrieve with sufficient precision for large enough dimensions. In the white-box setting, our defense works by obfuscating the parameters of the random projection. Unlike other defenses relying on obfuscated gradients, we find we are unable to build a reliable backward differentiable approximation for obfuscated parameters. Moreover, while our model reaches a good natural accuracy with a hybrid backpropagation - synthetic gradient method, the same approach is suboptimal if employed to generate adversarial examples. We find the combination of a random projection and binarization in the optical system also improves robustness against various types of black-box attacks. Finally, our hybrid training method builds robust features against transfer attacks. We demonstrate our approach on a VGG-like architecture, placing the defense on top of the convolutional features, on CIFAR-10 and CIFAR-100. Code is available at https://github.com/lightonai/adversarial-robustness-by-design.
Hardware Beyond Backpropagation: a Photonic Co-Processor for Direct Feedback Alignment
Dec 11, 2020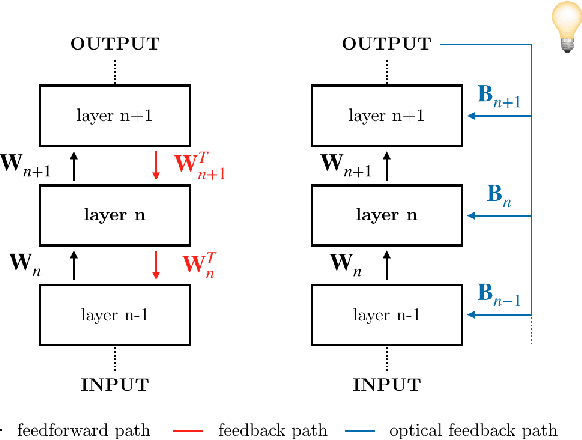


The scaling hypothesis motivates the expansion of models past trillions of parameters as a path towards better performance. Recent significant developments, such as GPT-3, have been driven by this conjecture. However, as models scale-up, training them efficiently with backpropagation becomes difficult. Because model, pipeline, and data parallelism distribute parameters and gradients over compute nodes, communication is challenging to orchestrate: this is a bottleneck to further scaling. In this work, we argue that alternative training methods can mitigate these issues, and can inform the design of extreme-scale training hardware. Indeed, using a synaptically asymmetric method with a parallelizable backward pass, such as Direct Feedback Alignement, communication needs are drastically reduced. We present a photonic accelerator for Direct Feedback Alignment, able to compute random projections with trillions of parameters. We demonstrate our system on benchmark tasks, using both fully-connected and graph convolutional networks. Our hardware is the first architecture-agnostic photonic co-processor for training neural networks. This is a significant step towards building scalable hardware, able to go beyond backpropagation, and opening new avenues for deep learning.