 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs the Number of Trainable Parameters All That Actually Matters?
Sep 24, 2021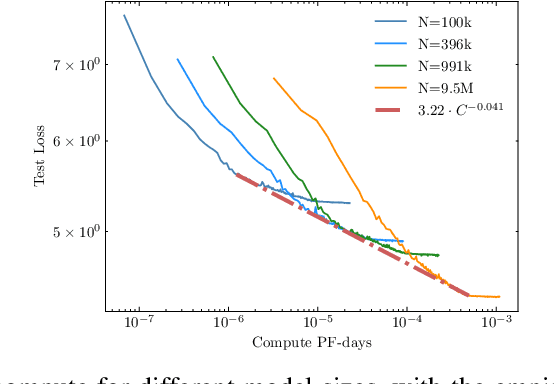
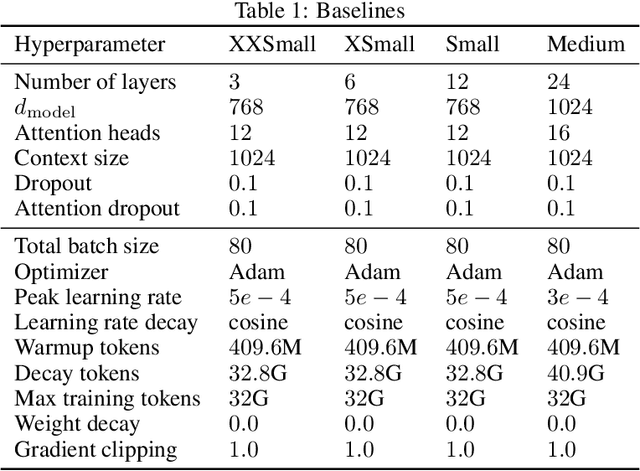
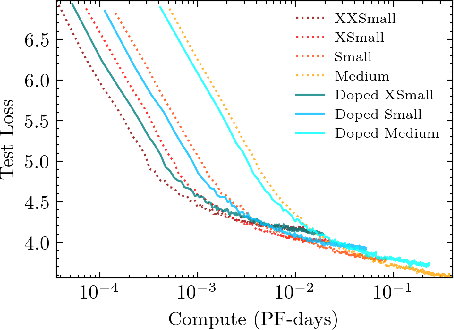
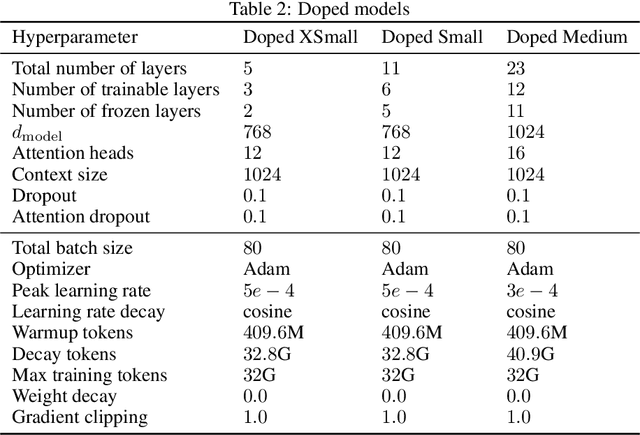
Recent work has identified simple empirical scaling laws for language models, linking compute budget, dataset size, model size, and autoregressive modeling loss. The validity of these simple power laws across orders of magnitude in model scale provides compelling evidence that larger models are also more capable models. However, scaling up models under the constraints of hardware and infrastructure is no easy feat, and rapidly becomes a hard and expensive engineering problem. We investigate ways to tentatively cheat scaling laws, and train larger models for cheaper. We emulate an increase in effective parameters, using efficient approximations: either by doping the models with frozen random parameters, or by using fast structured transforms in place of dense linear layers. We find that the scaling relationship between test loss and compute depends only on the actual number of trainable parameters; scaling laws cannot be deceived by spurious parameters.
Deep Multi-Facial Patches Aggregation Network For Facial Expression Recognition
Feb 20, 2020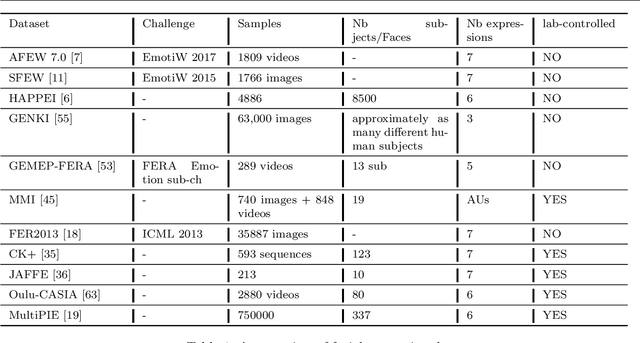
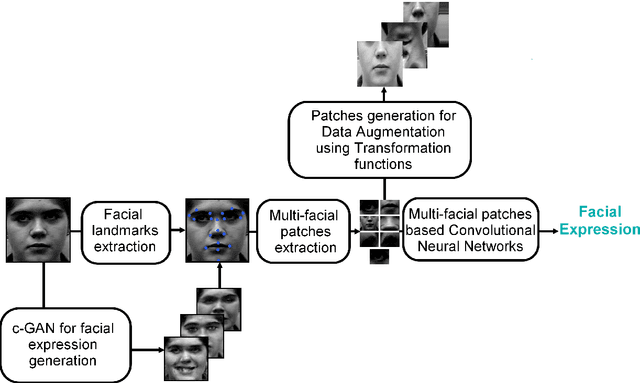
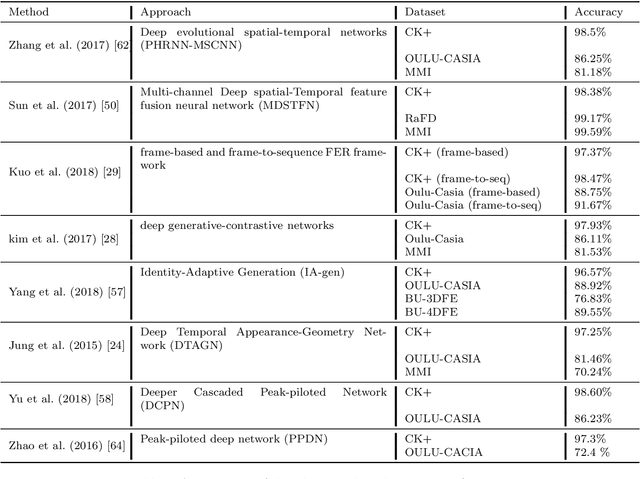
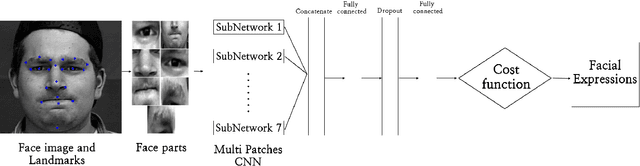
In this paper, we propose an approach for Facial Expressions Recognition (FER) based on a deep multi-facial patches aggregation network. Deep features are learned from facial patches using deep sub-networks and aggregated within one deep architecture for expression classification . Several problems may affect the performance of deep-learning based FER approaches, in particular, the small size of existing FER datasets which might not be sufficient to train large deep learning networks. Moreover, it is extremely time-consuming to collect and annotate a large number of facial images. To account for this, we propose two data augmentation techniques for facial expression generation to expand FER labeled training datasets. We evaluate the proposed framework on three FER datasets. Results show that the proposed approach achieves state-of-art FER deep learning approaches performance when the model is trained and tested on images from the same dataset. Moreover, the proposed data augmentation techniques improve the expression recognition rate, and thus can be a solution for training deep learning FER models using small datasets. The accuracy degrades significantly when testing for dataset bias.