 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Terms: Dense Retrievers Contain Trivially Extractable BM25-ready Zipfian Vocabularies
May 28, 2026We propose Latent Terms, a method revealing that models trained for dense retrieval, whether single- or multi-vector, learn representations that can trivially be decomposed into retrieval-ready sparse features. When trained on frozen retrievers, Sparse Autoencoders without any retrieval-specific adjustments extract a latent vocabulary with approximately Zipfian collection statistics, directly suitable for classical sparse retrieval scoring via BM25. This approach enables sparse retrieval while requiring no learned expansion objective or sparse retrieval supervision whatsoever, and can be readily applied to any dense retriever. Latent Terms is able to match or outperform single-vector scoring methods from its own base model as well as comparable SPLADE variants. In addition, it substantially outperforms its base model on LIMIT, a task specifically designed to highlight the failures of single-vector retrieval. Overall, our results highlight that neural retrievers contain more expressive and indexable structure than their default scoring functions expose, but that other methods can nonetheless be leveraged.
IncompeBench: A Permissively Licensed, Fine-Grained Benchmark for Music Information Retrieval
Feb 12, 2026Multimodal Information Retrieval has made significant progress in recent years, leveraging the increasingly strong multimodal abilities of deep pre-trained models to represent information across modalities. Music Information Retrieval (MIR), in particular, has considerably increased in quality, with neural representations of music even making its way into everyday life products. However, there is a lack of high-quality benchmarks for evaluating music retrieval performance. To address this issue, we introduce \textbf{IncompeBench}, a carefully annotated benchmark comprising $1,574$ permissively licensed, high-quality music snippets, $500$ diverse queries, and over $125,000$ individual relevance judgements. These annotations were created through the use of a multi-stage pipeline, resulting in high agreement between human annotators and the generated data. The resulting datasets are publicly available at https://huggingface.co/datasets/mixedbread-ai/incompebench-strict and https://huggingface.co/datasets/mixedbread-ai/incompebench-lenient with the prompts available at https://github.com/mixedbread-ai/incompebench-programs.
Simple Projection Variants Improve ColBERT Performance
Oct 14, 2025



Multi-vector dense retrieval methods like ColBERT systematically use a single-layer linear projection to reduce the dimensionality of individual vectors. In this study, we explore the implications of the MaxSim operator on the gradient flows of the training of multi-vector models and show that such a simple linear projection has inherent, if non-critical, limitations in this setting. We then discuss the theoretical improvements that could result from replacing this single-layer projection with well-studied alternative feedforward linear networks (FFN), such as deeper, non-linear FFN blocks, GLU blocks, and skip-connections, could alleviate these limitations. Through the design and systematic evaluation of alternate projection blocks, we show that better-designed final projections positively impact the downstream performance of ColBERT models. We highlight that many projection variants outperform the original linear projections, with the best-performing variants increasing average performance on a range of retrieval benchmarks across domains by over 2 NDCG@10 points. We then conduct further exploration on the individual parameters of these projections block in order to understand what drives this empirical performance, highlighting the particular importance of upscaled intermediate projections and residual connections. As part of these ablation studies, we show that numerous suboptimal projection variants still outperform the traditional single-layer projection across multiple benchmarks, confirming our hypothesis. Finally, we observe that this effect is consistent across random seeds, further confirming that replacing the linear layer of ColBERT models is a robust, drop-in upgrade.
ReadBench: Measuring the Dense Text Visual Reading Ability of Vision-Language Models
May 25, 2025
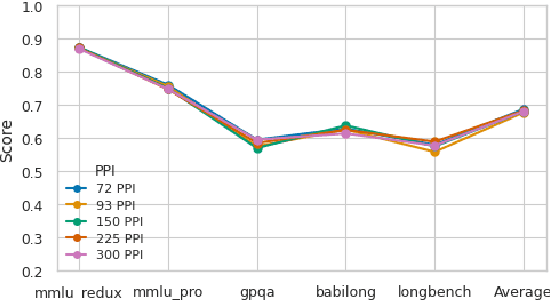
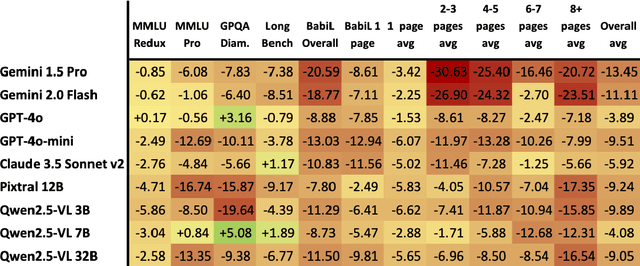
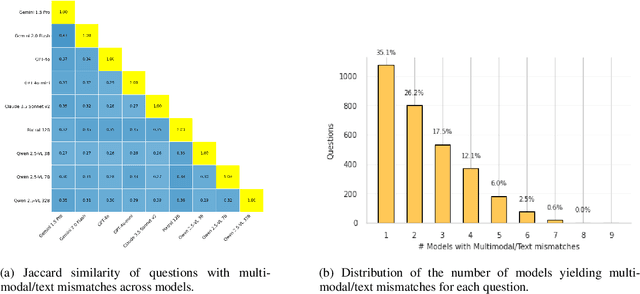
Recent advancements in Large Vision-Language Models (VLMs), have greatly enhanced their capability to jointly process text and images. However, despite extensive benchmarks evaluating visual comprehension (e.g., diagrams, color schemes, OCR tasks...), there is limited assessment of VLMs' ability to read and reason about text-rich images effectively. To fill this gap, we introduce ReadBench, a multimodal benchmark specifically designed to evaluate the reading comprehension capabilities of VLMs. ReadBench transposes contexts from established text-only benchmarks into images of text while keeping textual prompts and questions intact. Evaluating leading VLMs with ReadBench, we find minimal-but-present performance degradation on short, text-image inputs, while performance sharply declines for longer, multi-page contexts. Our experiments further reveal that text resolution has negligible effects on multimodal performance. These findings highlight needed improvements in VLMs, particularly their reasoning over visually presented extensive textual content, a capability critical for practical applications. ReadBench is available at https://github.com/answerdotai/ReadBench .
It's All in The [MASK]: Simple Instruction-Tuning Enables BERT-like Masked Language Models As Generative Classifiers
Feb 06, 2025![Figure 1 for It's All in The [MASK]: Simple Instruction-Tuning Enables BERT-like Masked Language Models As Generative Classifiers](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2F02b955cfb60fb55c9005095a40d631f93cb17fdb%2F2-Figure1-1.png&w=640&q=75)
![Figure 2 for It's All in The [MASK]: Simple Instruction-Tuning Enables BERT-like Masked Language Models As Generative Classifiers](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2F02b955cfb60fb55c9005095a40d631f93cb17fdb%2F4-Table1-1.png&w=640&q=75)
![Figure 3 for It's All in The [MASK]: Simple Instruction-Tuning Enables BERT-like Masked Language Models As Generative Classifiers](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2F02b955cfb60fb55c9005095a40d631f93cb17fdb%2F4-Figure2-1.png&w=640&q=75)
![Figure 4 for It's All in The [MASK]: Simple Instruction-Tuning Enables BERT-like Masked Language Models As Generative Classifiers](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2F02b955cfb60fb55c9005095a40d631f93cb17fdb%2F6-Table2-1.png&w=640&q=75)
While encoder-only models such as BERT and ModernBERT are ubiquitous in real-world NLP applications, their conventional reliance on task-specific classification heads can limit their applicability compared to decoder-based large language models (LLMs). In this work, we introduce ModernBERT-Large-Instruct, a 0.4B-parameter encoder model that leverages its masked language modelling (MLM) head for generative classification. Our approach employs an intentionally simple training loop and inference mechanism that requires no heavy pre-processing, heavily engineered prompting, or architectural modifications. ModernBERT-Large-Instruct exhibits strong zero-shot performance on both classification and knowledge-based tasks, outperforming similarly sized LLMs on MMLU and achieving 93% of Llama3-1B's MMLU performance with 60% less parameters. We also demonstrate that, when fine-tuned, the generative approach using the MLM head matches or even surpasses traditional classification-head methods across diverse NLU tasks.This capability emerges specifically in models trained on contemporary, diverse data mixes, with models trained on lower volume, less-diverse data yielding considerably weaker performance. Although preliminary, these results demonstrate the potential of using the original generative masked language modelling head over traditional task-specific heads for downstream tasks. Our work suggests that further exploration into this area is warranted, highlighting many avenues for future improvements.
Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference
Dec 19, 2024



Encoder-only transformer models such as BERT offer a great performance-size tradeoff for retrieval and classification tasks with respect to larger decoder-only models. Despite being the workhorse of numerous production pipelines, there have been limited Pareto improvements to BERT since its release. In this paper, we introduce ModernBERT, bringing modern model optimizations to encoder-only models and representing a major Pareto improvement over older encoders. Trained on 2 trillion tokens with a native 8192 sequence length, ModernBERT models exhibit state-of-the-art results on a large pool of evaluations encompassing diverse classification tasks and both single and multi-vector retrieval on different domains (including code). In addition to strong downstream performance, ModernBERT is also the most speed and memory efficient encoder and is designed for inference on common GPUs.
rerankers: A Lightweight Python Library to Unify Ranking Methods
Sep 03, 2024This paper presents rerankers, a Python library which provides an easy-to-use interface to the most commonly used re-ranking approaches. Re-ranking is an integral component of many retrieval pipelines; however, there exist numerous approaches to it, relying on different implementation methods. rerankers unifies these methods into a single user-friendly interface, allowing practitioners and researchers alike to explore different methods while only changing a single line of Python code. Moreover ,rerankers ensures that its implementations are done with the fewest dependencies possible, and re-uses the original implementation whenever possible, guaranteeing that our simplified interface results in no performance degradation compared to more complex ones. The full source code and list of supported models are updated regularly and available at https://github.com/answerdotai/rerankers.
JaColBERTv2.5: Optimising Multi-Vector Retrievers to Create State-of-the-Art Japanese Retrievers with Constrained Resources
Jul 30, 2024Neural Information Retrieval has advanced rapidly in high-resource languages, but progress in lower-resource ones such as Japanese has been hindered by data scarcity, among other challenges. Consequently, multilingual models have dominated Japanese retrieval, despite their computational inefficiencies and inability to capture linguistic nuances. While recent multi-vector monolingual models like JaColBERT have narrowed this gap, they still lag behind multilingual methods in large-scale evaluations. This work addresses the suboptimal training methods of multi-vector retrievers in lower-resource settings, focusing on Japanese. We systematically evaluate and improve key aspects of the inference and training settings of JaColBERT, and more broadly, multi-vector models. We further enhance performance through a novel checkpoint merging step, showcasing it to be an effective way of combining the benefits of fine-tuning with the generalization capabilities of the original checkpoint. Building on our analysis, we introduce a novel training recipe, resulting in the JaColBERTv2.5 model. JaColBERTv2.5, with only 110 million parameters and trained in under 15 hours on 4 A100 GPUs, significantly outperforms all existing methods across all common benchmarks, reaching an average score of 0.754, significantly above the previous best of 0.720. To support future research, we make our final models, intermediate checkpoints and all data used publicly available.
JaColBERT and Hard Negatives, Towards Better Japanese-First Embeddings for Retrieval: Early Technical Report
Dec 26, 2023
Document retrieval in many languages has been largely relying on multi-lingual models, and leveraging the vast wealth of English training data. In Japanese, the best performing deep-learning based retrieval approaches rely on multilingual dense embeddings. In this work, we introduce (1) a hard-negative augmented version of the Japanese MMARCO dataset and (2) JaColBERT, a document retrieval model built on the ColBERT model architecture, specifically for Japanese. JaColBERT vastly outperform all previous monolingual retrieval approaches and competes with the best multilingual methods, despite unfavourable evaluation settings (out-of-domain vs. in-domain for the multilingual models). JaColBERT reaches an average Recall@10 of 0.813, noticeably ahead of the previous monolingual best-performing model (0.716) and only slightly behind multilingual-e5-base (0.820), though more noticeably behind multilingual-e5-large (0.856). These results are achieved using only a limited, entirely Japanese, training set, more than two orders of magnitudes smaller than multilingual embedding models. We believe these results show great promise to support retrieval-enhanced application pipelines in a wide variety of domains.
Large Language Models as Batteries-Included Zero-Shot ESCO Skills Matchers
Jul 07, 2023

Understanding labour market dynamics requires accurately identifying the skills required for and possessed by the workforce. Automation techniques are increasingly being developed to support this effort. However, automatically extracting skills from job postings is challenging due to the vast number of existing skills. The ESCO (European Skills, Competences, Qualifications and Occupations) framework provides a useful reference, listing over 13,000 individual skills. However, skills extraction remains difficult and accurately matching job posts to the ESCO taxonomy is an open problem. In this work, we propose an end-to-end zero-shot system for skills extraction from job descriptions based on large language models (LLMs). We generate synthetic training data for the entirety of ESCO skills and train a classifier to extract skill mentions from job posts. We also employ a similarity retriever to generate skill candidates which are then re-ranked using a second LLM. Using synthetic data achieves an RP@10 score 10 points higher than previous distant supervision approaches. Adding GPT-4 re-ranking improves RP@10 by over 22 points over previous methods. We also show that Framing the task as mock programming when prompting the LLM can lead to better performance than natural language prompts, especially with weaker LLMs. We demonstrate the potential of integrating large language models at both ends of skills matching pipelines. Our approach requires no human annotations and achieve extremely promising results on skills extraction against ESCO.