 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models as Batteries-Included Zero-Shot ESCO Skills Matchers
Jul 07, 2023

Understanding labour market dynamics requires accurately identifying the skills required for and possessed by the workforce. Automation techniques are increasingly being developed to support this effort. However, automatically extracting skills from job postings is challenging due to the vast number of existing skills. The ESCO (European Skills, Competences, Qualifications and Occupations) framework provides a useful reference, listing over 13,000 individual skills. However, skills extraction remains difficult and accurately matching job posts to the ESCO taxonomy is an open problem. In this work, we propose an end-to-end zero-shot system for skills extraction from job descriptions based on large language models (LLMs). We generate synthetic training data for the entirety of ESCO skills and train a classifier to extract skill mentions from job posts. We also employ a similarity retriever to generate skill candidates which are then re-ranked using a second LLM. Using synthetic data achieves an RP@10 score 10 points higher than previous distant supervision approaches. Adding GPT-4 re-ranking improves RP@10 by over 22 points over previous methods. We also show that Framing the task as mock programming when prompting the LLM can lead to better performance than natural language prompts, especially with weaker LLMs. We demonstrate the potential of integrating large language models at both ends of skills matching pipelines. Our approach requires no human annotations and achieve extremely promising results on skills extraction against ESCO.
Large Language Models in the Workplace: A Case Study on Prompt Engineering for Job Type Classification
Mar 14, 2023This case study investigates the task of job classification in a real-world setting, where the goal is to determine whether an English-language job posting is appropriate for a graduate or entry-level position. We explore multiple approaches to text classification, including supervised approaches such as traditional models like Support Vector Machines (SVMs) and state-of-the-art deep learning methods such as DeBERTa. We compare them with Large Language Models (LLMs) used in both few-shot and zero-shot classification settings. To accomplish this task, we employ prompt engineering, a technique that involves designing prompts to guide the LLMs towards the desired output. Specifically, we evaluate the performance of two commercially available state-of-the-art GPT-3.5-based language models, text-davinci-003 and gpt-3.5-turbo. We also conduct a detailed analysis of the impact of different aspects of prompt engineering on the model's performance. Our results show that, with a well-designed prompt, a zero-shot gpt-3.5-turbo classifier outperforms all other models, achieving a 6% increase in Precision@95% Recall compared to the best supervised approach. Furthermore, we observe that the wording of the prompt is a critical factor in eliciting the appropriate "reasoning" in the model, and that seemingly minor aspects of the prompt significantly affect the model's performance.
Compression of Deep Neural Networks on the Fly
Mar 18, 2016

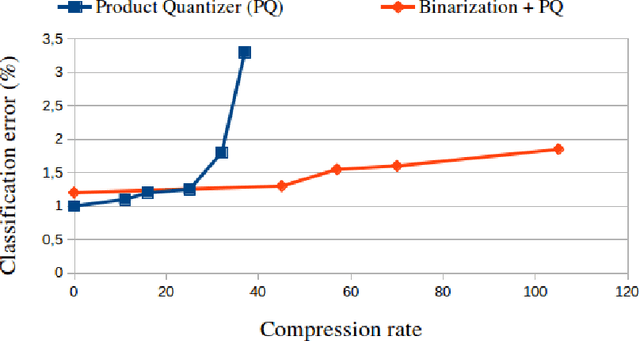

Thanks to their state-of-the-art performance, deep neural networks are increasingly used for object recognition. To achieve these results, they use millions of parameters to be trained. However, when targeting embedded applications the size of these models becomes problematic. As a consequence, their usage on smartphones or other resource limited devices is prohibited. In this paper we introduce a novel compression method for deep neural networks that is performed during the learning phase. It consists in adding an extra regularization term to the cost function of fully-connected layers. We combine this method with Product Quantization (PQ) of the trained weights for higher savings in storage consumption. We evaluate our method on two data sets (MNIST and CIFAR10), on which we achieve significantly larger compression rates than state-of-the-art methods.