 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvercoming Copyright Barriers in Corpus Distribution Through Non-Reversible Hashing
Apr 25, 2026While annotated corpora are crucial in the field of natural language processing (NLP), those containing copyrighted material are difficult to exchange among researchers. Yet, such corpora are necessary to fully represent the diversity of data found in the wild in the context of NLP tasks. We tackle this issue by proposing a method to lawfully and publicly share the annotations of copyrighted literary texts. The corpus creator shares the annotations in clear, along with a non-reversible hashed version of the source material. The corpus user must own the source material, and apply the same hash function to their own tokens, in order to match them to the shared annotations. Crucially, our method is robust to reasonable divergences in the version of the copyrighted data owned by the user. As an illustration, we present alignment experiments on different editions of novels. Our results show that our method is able to correctly align 98.7 to 99.79% of tokens depending on the novel, provided the user version is sufficiently close to the corpus creator's version. We publicly release novelshare, a Python implementation of our method.
Beyond Known Facts: Generating Unseen Temporal Knowledge to Address Data Contamination in LLM Evaluation
Jan 20, 2026The automatic extraction of information is important for populating large web knowledge bases such as Wikidata. The temporal version of that task, temporal knowledge graph extraction (TKGE), involves extracting temporally grounded facts from text, represented as semantic quadruples (subject, relation, object, timestamp). Many recent systems take advantage of large language models (LLMs), which are becoming a new cornerstone of the web due to their performance on many tasks across the natural language processing (NLP) field. Despite the importance of TKGE, existing datasets for training and evaluation remain scarce, and contamination of evaluation data is an unaddressed issue, potentially inflating LLMs' perceived performance due to overlaps between training and evaluation sets. To mitigate these challenges, we propose a novel synthetic evaluation dataset constructed from predicted future, previously unseen temporal facts, thereby eliminating contamination and enabling robust and unbiased benchmarking. Our dataset creation involves a two-step approach: (1) Temporal Knowledge Graph Forecasting (TKGF) generates plausible future quadruples, which are subsequently filtered to adhere to the original knowledge base schema; (2) LLMs perform quadruple-to-text generation, creating semantically aligned textual descriptions. We benchmark Extract, Define and Canonicalize (EDC), a state-of-the-art LLM-based extraction framework, demonstrating that LLM performance decreases when evaluated on our dataset compared to a dataset of known facts. We publicly release our dataset consisting of 4.2K future quadruples and corresponding textual descriptions, along with the generation methodology, enabling continuous creation of unlimited future temporal datasets to serve as long-term, contamination-free benchmarks for TKGE.
The Role of Natural Language Processing Tasks in Automatic Literary Character Network Construction
Dec 16, 2024



The automatic extraction of character networks from literary texts is generally carried out using natural language processing (NLP) cascading pipelines. While this approach is widespread, no study exists on the impact of low-level NLP tasks on their performance. In this article, we conduct such a study on a literary dataset, focusing on the role of named entity recognition (NER) and coreference resolution when extracting co-occurrence networks. To highlight the impact of these tasks' performance, we start with gold-standard annotations, progressively add uniformly distributed errors, and observe their impact in terms of character network quality. We demonstrate that NER performance depends on the tested novel and strongly affects character detection. We also show that NER-detected mentions alone miss a lot of character co-occurrences, and that coreference resolution is needed to prevent this. Finally, we present comparison points with 2 methods based on large language models (LLMs), including a fully end-to-end one, and show that these models are outperformed by traditional NLP pipelines in terms of recall.
Interconnected Kingdoms: Comparing 'A Song of Ice and Fire' Adaptations Across Media Using Complex Networks
Oct 07, 2024In this article, we propose and apply a method to compare adaptations of the same story across different media. We tackle this task by modelling such adaptations through character networks. We compare them by leveraging two concepts at the core of storytelling: the characters involved, and the dynamics of the story. We propose several methods to match characters between media and compare their position in the networks; and perform narrative matching, i.e. match the sequences of narrative units that constitute the plots. We apply these methods to the novel series \textit{A Song of Ice and Fire}, by G.R.R. Martin, and its comics and TV show adaptations. Our results show that interactions between characters are not sufficient to properly match individual characters between adaptations, but that using some additional information such as character affiliation or gender significantly improves the performance. On the contrary, character interactions convey enough information to perform narrative matching, and allow us to detect the divergence between the original novels and its TV show adaptation.
Annotation Guidelines for Corpus Novelties: Part 2 -- Alias Resolution Version 1.0
Oct 01, 2024The Novelties corpus is a collection of novels (and parts of novels) annotated for Alias Resolution, among other tasks. This document describes the guidelines applied during the annotation process. It contains the instructions used by the annotators, as well as a number of examples retrieved from the annotated novels, and illustrating how canonical names should be defined, and which names should be considered as referring to the same entity.
Renard: A Modular Pipeline for Extracting Character Networks from Narrative Texts
Jul 02, 2024

Renard (Relationships Extraction from NARrative Documents) is a Python library that allows users to define custom natural language processing (NLP) pipelines to extract character networks from narrative texts. Contrary to the few existing tools, Renard can extract dynamic networks, as well as the more common static networks. Renard pipelines are modular: users can choose the implementation of each NLP subtask needed to extract a character network. This allows users to specialize pipelines to particular types of texts and to study the impact of each subtask on the extracted network.
* Accepted at JOSS
Learning to Rank Context for Named Entity Recognition Using a Synthetic Dataset
Nov 06, 2023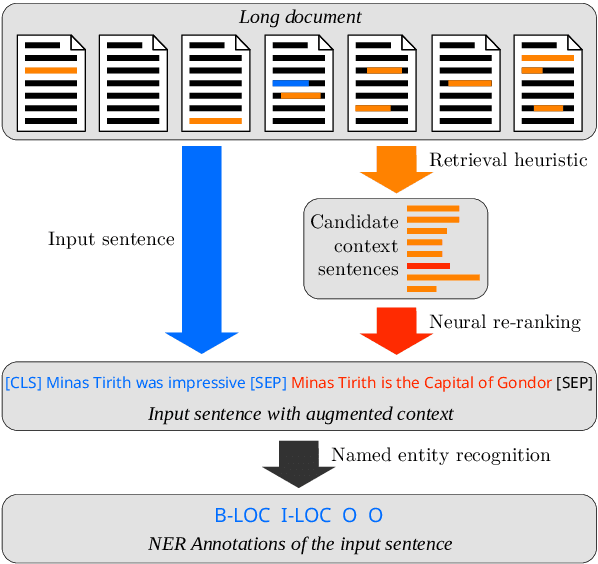
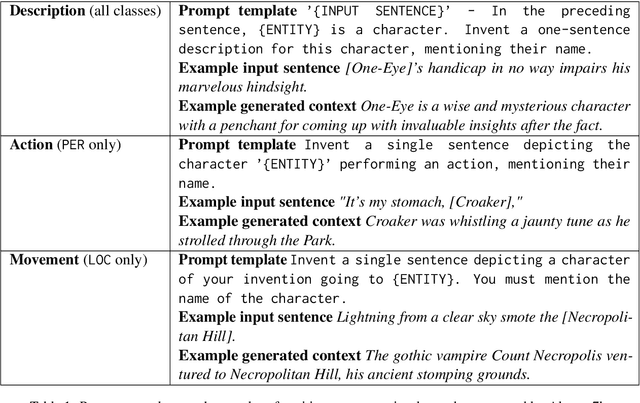

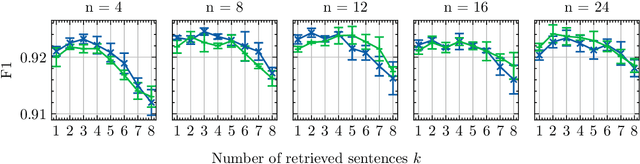
While recent pre-trained transformer-based models can perform named entity recognition (NER) with great accuracy, their limited range remains an issue when applied to long documents such as whole novels. To alleviate this issue, a solution is to retrieve relevant context at the document level. Unfortunately, the lack of supervision for such a task means one has to settle for unsupervised approaches. Instead, we propose to generate a synthetic context retrieval training dataset using Alpaca, an instructiontuned large language model (LLM). Using this dataset, we train a neural context retriever based on a BERT model that is able to find relevant context for NER. We show that our method outperforms several retrieval baselines for the NER task on an English literary dataset composed of the first chapter of 40 books.
The Role of Global and Local Context in Named Entity Recognition
May 04, 2023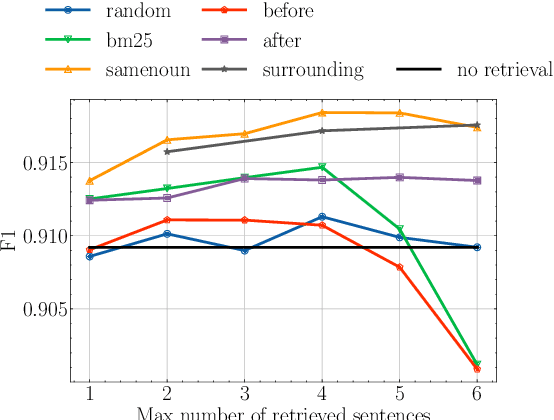
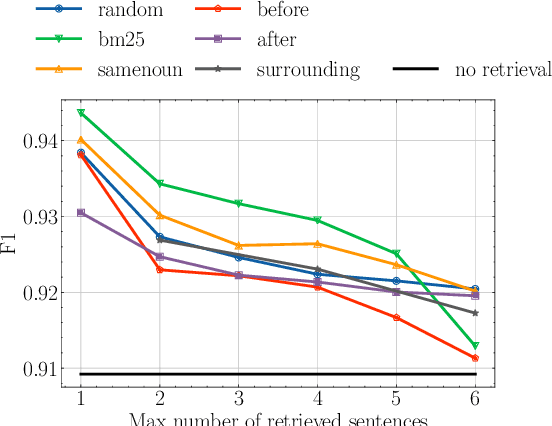
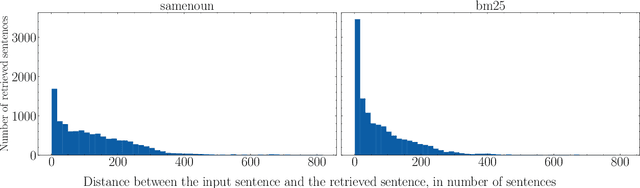
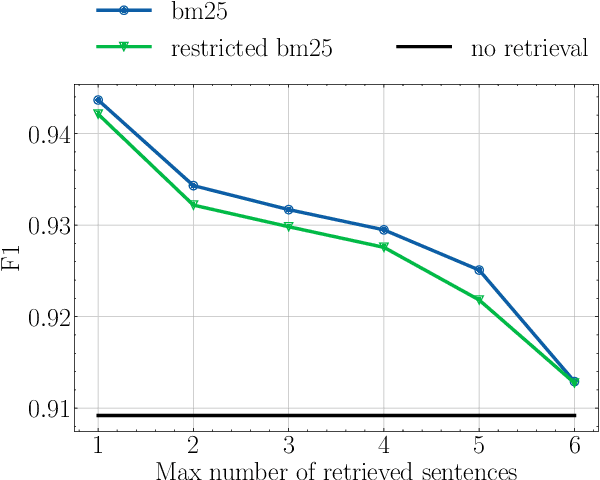
Pre-trained transformer-based models have recently shown great performance when applied to Named Entity Recognition (NER). As the complexity of their self-attention mechanism prevents them from processing long documents at once, these models are usually applied in a sequential fashion. Such an approach unfortunately only incorporates local context and prevents leveraging global document context in long documents such as novels, which might hinder performance. In this article, we explore the impact of global document context, and its relationships with local context. We find that correctly retrieving global document context has a greater impact on performance than only leveraging local context, prompting for further research on how to better retrieve that context.
Data Augmentation for Robust Character Detection in Fantasy Novels
Feb 09, 2023



Named Entity Recognition (NER) is a low-level task often used as a foundation for solving higher level NLP problems. In the context of character detection in novels, NER false negatives can be an issue as they possibly imply missing certain characters or relationships completely. In this article, we demonstrate that applying a straightforward data augmentation technique allows training a model achieving higher recall, at the cost of a certain amount of precision regarding ambiguous entities. We show that this decrease in precision can be mitigated by giving the model more local context, which resolves some of the ambiguities.