 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-efficient learning for 3D mirror symmetry detection
Dec 23, 2021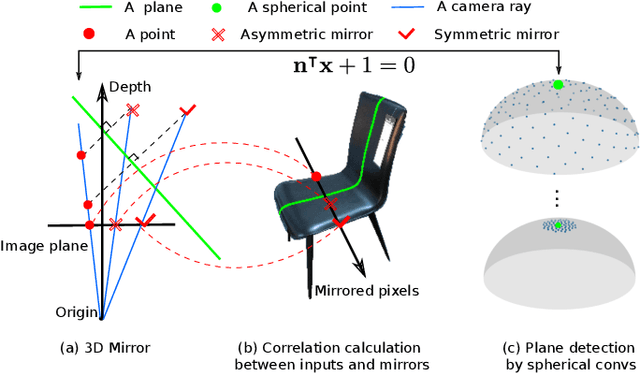
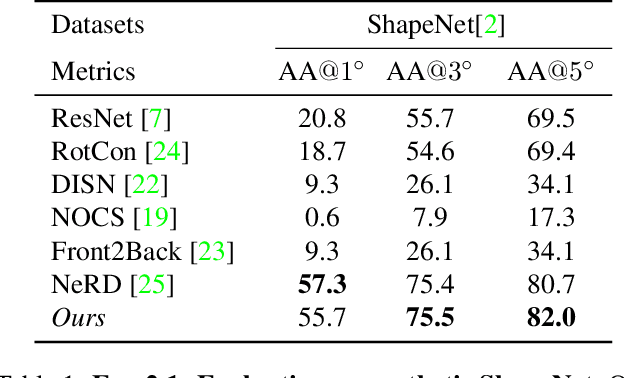
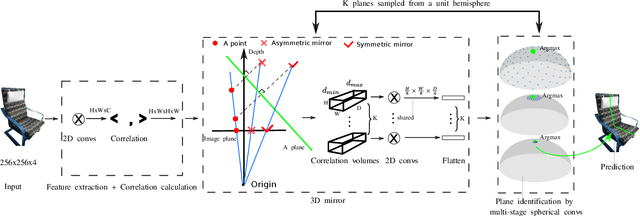
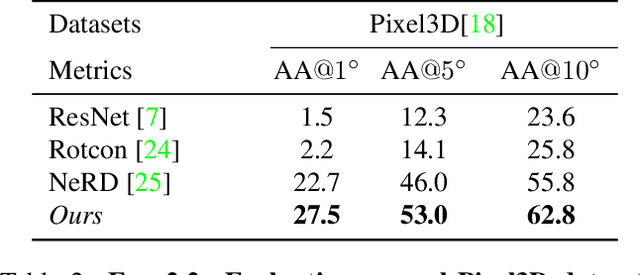
We introduce a geometry-inspired deep learning method for detecting 3D mirror plane from single-view images. We reduce the demand for massive training data by explicitly adding 3D mirror geometry into learning as an inductive prior. We extract semantic features, calculate intra-pixel correlations, and build a 3D correlation volume for each plane. The correlation volume indicates the extent to which the input resembles its mirrors at various depth, allowing us to identify the likelihood of the given plane being a mirror plane. Subsequently, we treat the correlation volumes as feature descriptors for sampled planes and map them to a unit hemisphere where the normal of sampled planes lies. Lastly, we design multi-stage spherical convolutions to identify the optimal mirror plane in a coarse-to-fine manner. Experiments on both synthetic and real-world datasets show the benefit of 3D mirror geometry in improving data efficiency and inference speed (up to 25 FPS).
Semi-supervised lane detection with Deep Hough Transform
Jun 09, 2021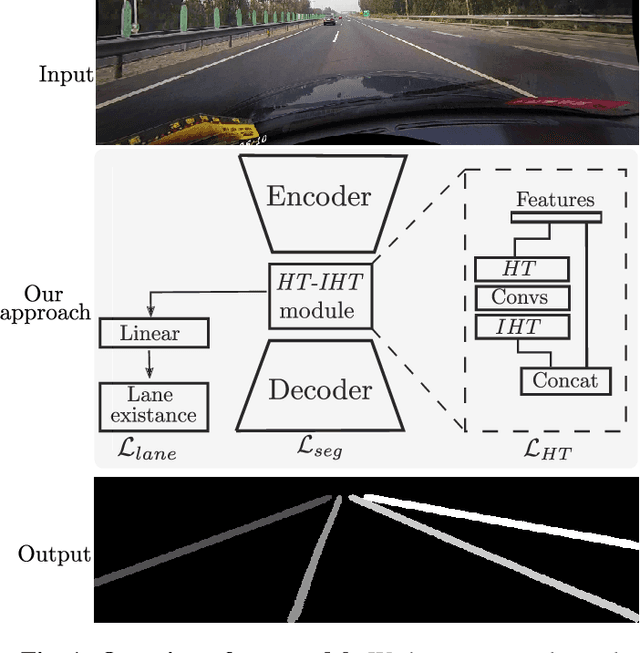
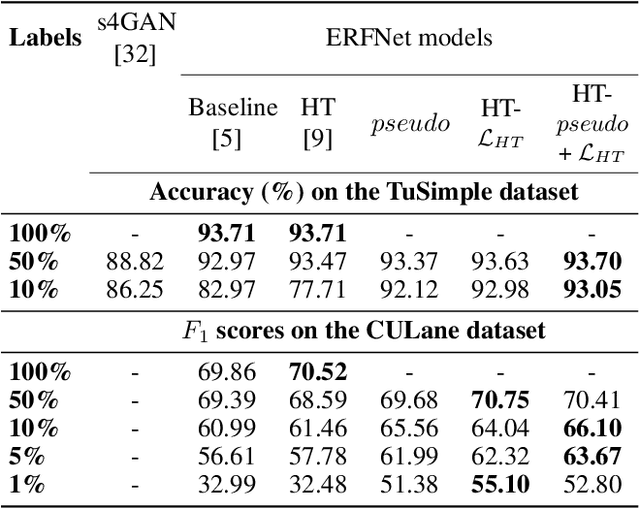

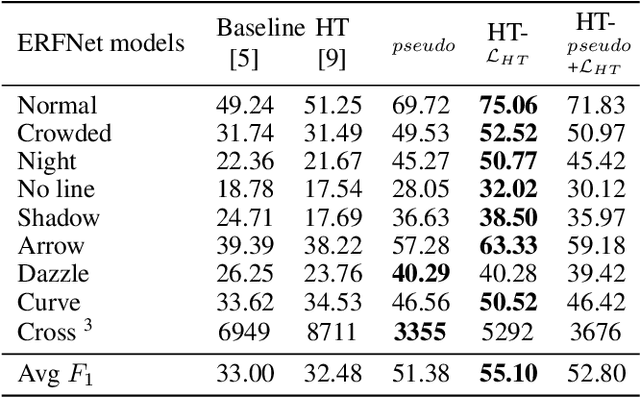
Current work on lane detection relies on large manually annotated datasets. We reduce the dependency on annotations by leveraging massive cheaply available unlabelled data. We propose a novel loss function exploiting geometric knowledge of lanes in Hough space, where a lane can be identified as a local maximum. By splitting lanes into separate channels, we can localize each lane via simple global max-pooling. The location of the maximum encodes the layout of a lane, while the intensity indicates the the probability of a lane being present. Maximizing the log-probability of the maximal bins helps neural networks find lanes without labels. On the CULane and TuSimple datasets, we show that the proposed Hough Transform loss improves performance significantly by learning from large amounts of unlabelled images.
One-Step Time-Dependent Future Video Frame Prediction with a Convolutional Encoder-Decoder Neural Network
Jul 24, 2017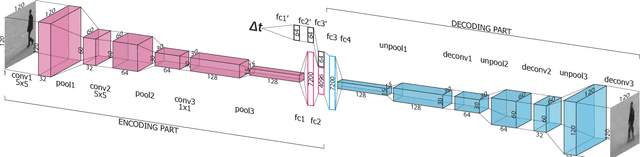
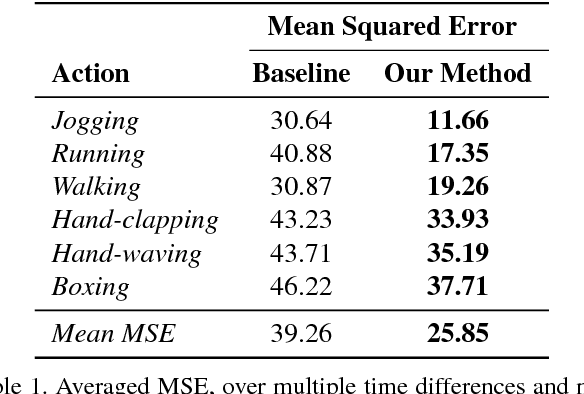


There is an inherent need for autonomous cars, drones, and other robots to have a notion of how their environment behaves and to anticipate changes in the near future. In this work, we focus on anticipating future appearance given the current frame of a video. Existing work focuses on either predicting the future appearance as the next frame of a video, or predicting future motion as optical flow or motion trajectories starting from a single video frame. This work stretches the ability of CNNs (Convolutional Neural Networks) to predict an anticipation of appearance at an arbitrarily given future time, not necessarily the next video frame. We condition our predicted future appearance on a continuous time variable that allows us to anticipate future frames at a given temporal distance, directly from the input video frame. We show that CNNs can learn an intrinsic representation of typical appearance changes over time and successfully generate realistic predictions at a deliberate time difference in the near future.