 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWavSLM: Single-Stream Speech Language Modeling via WavLM Distillation
Mar 05, 2026Large language models show that simple autoregressive training can yield scalable and coherent generation, but extending this paradigm to speech remains challenging due to the entanglement of semantic and acoustic information. Most existing speech language models rely on text supervision, hierarchical token streams, or complex hybrid architectures, departing from the single-stream generative pretraining paradigm that has proven effective in text. In this work, we introduce WavSLM, a speech language model trained by quantizing and distilling self-supervised WavLM representations into a single codebook and optimizing an autoregressive next-chunk prediction objective. WavSLM jointly models semantic and acoustic information within a single token stream without text supervision or text pretraining. Despite its simplicity, it achieves competitive performance on consistency benchmarks and speech generation while using fewer parameters, less training data, and supporting streaming inference. Demo samples are available at https://lucadellalib.github.io/wavslm-web/.
Beyond Fixed Frames: Dynamic Character-Aligned Speech Tokenization
Jan 30, 2026Neural audio codecs are at the core of modern conversational speech technologies, converting continuous speech into sequences of discrete tokens that can be processed by LLMs. However, existing codecs typically operate at fixed frame rates, allocating tokens uniformly in time and producing unnecessarily long sequences. In this work, we introduce DyCAST, a Dynamic Character-Aligned Speech Tokenizer that enables variable-frame-rate tokenization through soft character-level alignment and explicit duration modeling. DyCAST learns to associate tokens with character-level linguistic units during training and supports alignment-free inference with direct control over token durations at decoding time. To improve speech resynthesis quality at low frame rates, we further introduce a retrieval-augmented decoding mechanism that enhances reconstruction fidelity without increasing bitrate. Experiments show that DyCAST achieves competitive speech resynthesis quality and downstream performance while using significantly fewer tokens than fixed-frame-rate codecs.
FocalCodec-Stream: Streaming Low-Bitrate Speech Coding via Causal Distillation
Sep 19, 2025Neural audio codecs are a fundamental component of modern generative audio pipelines. Although recent codecs achieve strong low-bitrate reconstruction and provide powerful representations for downstream tasks, most are non-streamable, limiting their use in real-time applications. We present FocalCodec-Stream, a hybrid codec based on focal modulation that compresses speech into a single binary codebook at 0.55 - 0.80 kbps with a theoretical latency of 80 ms. Our approach combines multi-stage causal distillation of WavLM with targeted architectural improvements, including a lightweight refiner module that enhances quality under latency constraints. Experiments show that FocalCodec-Stream outperforms existing streamable codecs at comparable bitrates, while preserving both semantic and acoustic information. The result is a favorable trade-off between reconstruction quality, downstream task performance, latency, and efficiency. Code and checkpoints will be released at https://github.com/lucadellalib/focalcodec.
FocalCodec: Low-Bitrate Speech Coding via Focal Modulation Networks
Feb 06, 2025



Large language models have revolutionized natural language processing through self-supervised pretraining on massive datasets. Inspired by this success, researchers have explored adapting these methods to speech by discretizing continuous audio into tokens using neural audio codecs. However, existing approaches face limitations, including high bitrates, the loss of either semantic or acoustic information, and the reliance on multi-codebook designs when trying to capture both, which increases architectural complexity for downstream tasks. To address these challenges, we introduce FocalCodec, an efficient low-bitrate codec based on focal modulation that utilizes a single binary codebook to compress speech between 0.16 and 0.65 kbps. FocalCodec delivers competitive performance in speech resynthesis and voice conversion at lower bitrates than the current state-of-the-art, while effectively handling multilingual speech and noisy environments. Evaluation on downstream tasks shows that FocalCodec successfully preserves sufficient semantic and acoustic information, while also being well-suited for generative modeling. Demo samples, code and checkpoints are available at https://lucadellalib.github.io/focalcodec-web/.
Soft Actor-Critic with Beta Policy via Implicit Reparameterization Gradients
Sep 08, 2024
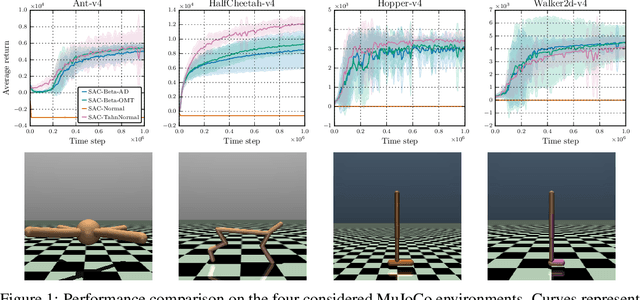

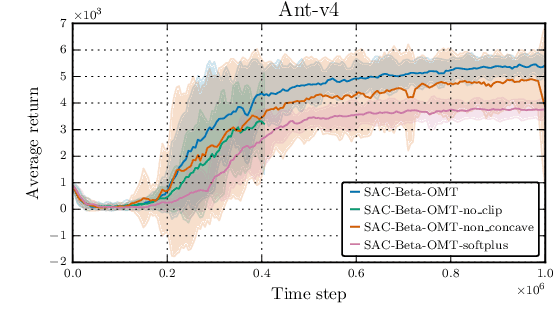
Recent advances in deep reinforcement learning have achieved impressive results in a wide range of complex tasks, but poor sample efficiency remains a major obstacle to real-world deployment. Soft actor-critic (SAC) mitigates this problem by combining stochastic policy optimization and off-policy learning, but its applicability is restricted to distributions whose gradients can be computed through the reparameterization trick. This limitation excludes several important examples such as the beta distribution, which was shown to improve the convergence rate of actor-critic algorithms in high-dimensional continuous control problems thanks to its bounded support. To address this issue, we investigate the use of implicit reparameterization, a powerful technique that extends the class of reparameterizable distributions. In particular, we use implicit reparameterization gradients to train SAC with the beta policy on simulated robot locomotion environments and compare its performance with common baselines. Experimental results show that the beta policy is a viable alternative, as it outperforms the normal policy and is on par with the squashed normal policy, which is the go-to choice for SAC. The code is available at https://github.com/lucadellalib/sac-beta.
How to Choose a Reinforcement-Learning Algorithm
Jul 30, 2024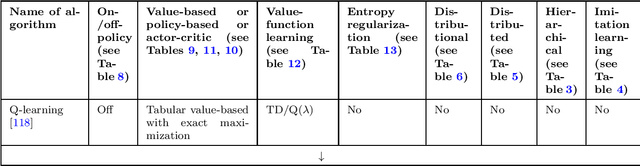
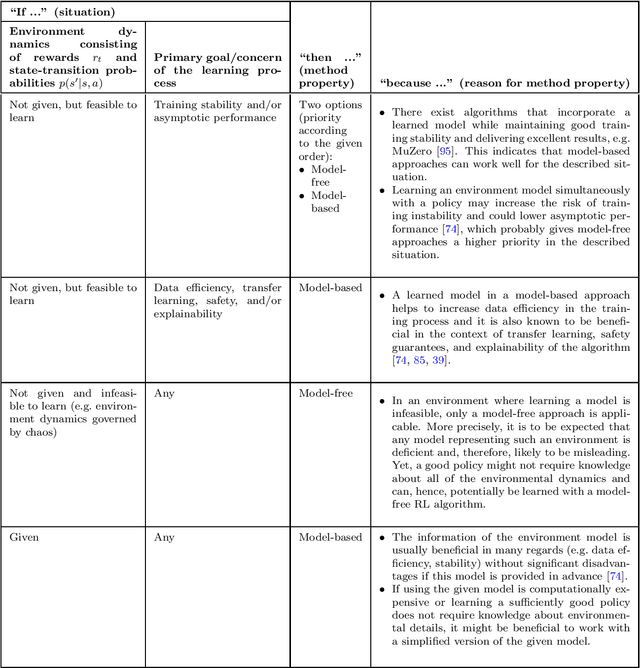
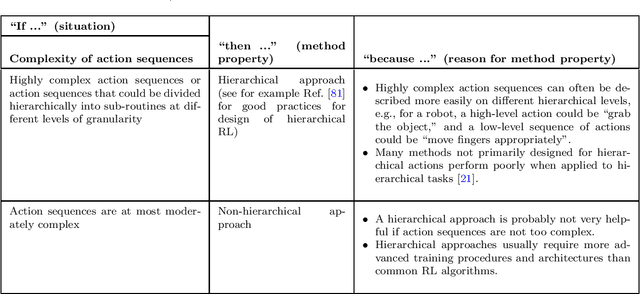

The field of reinforcement learning offers a large variety of concepts and methods to tackle sequential decision-making problems. This variety has become so large that choosing an algorithm for a task at hand can be challenging. In this work, we streamline the process of choosing reinforcement-learning algorithms and action-distribution families. We provide a structured overview of existing methods and their properties, as well as guidelines for when to choose which methods. An interactive version of these guidelines is available online at https://rl-picker.github.io/.
Open-Source Conversational AI with SpeechBrain 1.0
Jul 02, 2024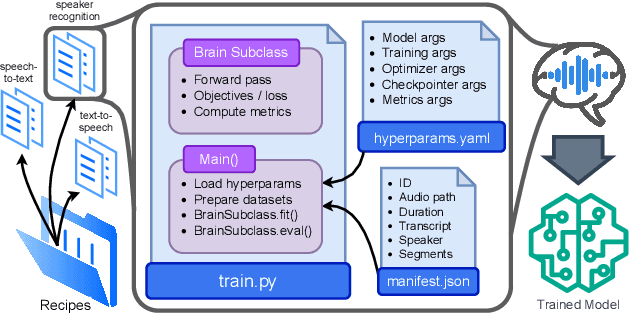

SpeechBrain is an open-source Conversational AI toolkit based on PyTorch, focused particularly on speech processing tasks such as speech recognition, speech enhancement, speaker recognition, text-to-speech, and much more. It promotes transparency and replicability by releasing both the pre-trained models and the complete "recipes" of code and algorithms required for training them. This paper presents SpeechBrain 1.0, a significant milestone in the evolution of the toolkit, which now has over 200 recipes for speech, audio, and language processing tasks, and more than 100 models available on Hugging Face. SpeechBrain 1.0 introduces new technologies to support diverse learning modalities, Large Language Model (LLM) integration, and advanced decoding strategies, along with novel models, tasks, and modalities. It also includes a new benchmark repository, offering researchers a unified platform for evaluating models across diverse tasks
DASB -- Discrete Audio and Speech Benchmark
Jun 20, 2024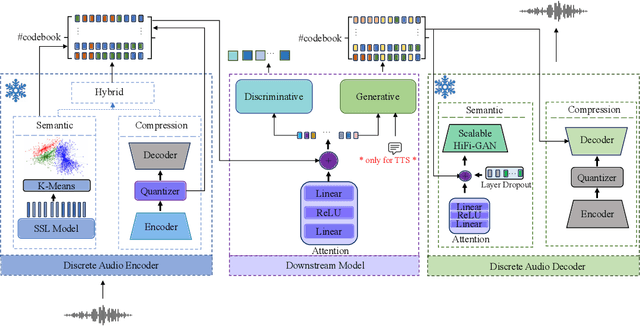
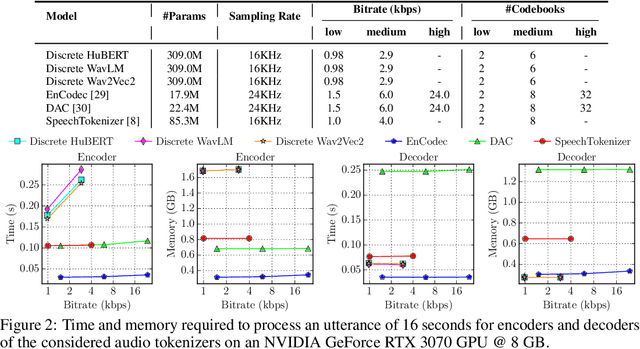
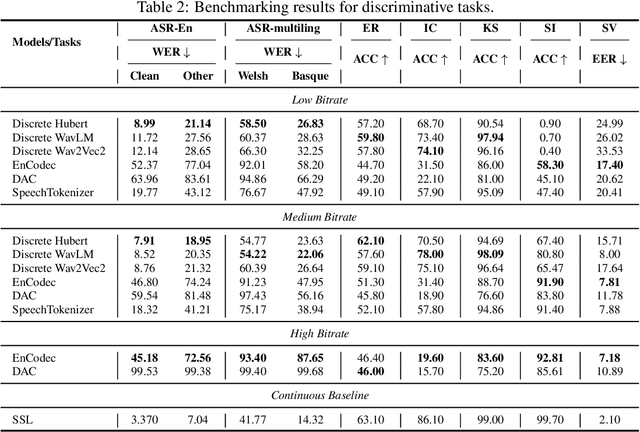
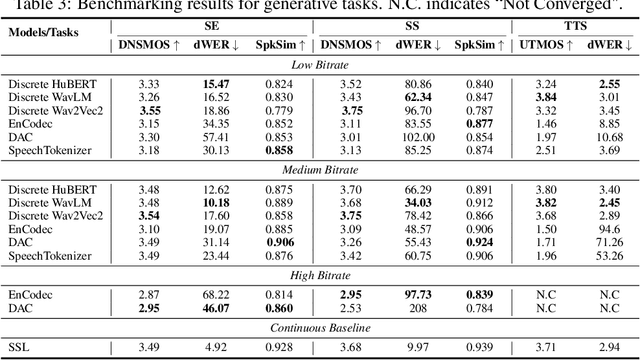
Discrete audio tokens have recently gained considerable attention for their potential to connect audio and language processing, enabling the creation of modern multimodal large language models. Ideal audio tokens must effectively preserve phonetic and semantic content along with paralinguistic information, speaker identity, and other details. While several types of audio tokens have been recently proposed, identifying the optimal tokenizer for various tasks is challenging due to the inconsistent evaluation settings in existing studies. To address this gap, we release the Discrete Audio and Speech Benchmark (DASB), a comprehensive leaderboard for benchmarking discrete audio tokens across a wide range of discriminative tasks, including speech recognition, speaker identification and verification, emotion recognition, keyword spotting, and intent classification, as well as generative tasks such as speech enhancement, separation, and text-to-speech. Our results show that, on average, semantic tokens outperform compression tokens across most discriminative and generative tasks. However, the performance gap between semantic tokens and standard continuous representations remains substantial, highlighting the need for further research in this field.
How Should We Extract Discrete Audio Tokens from Self-Supervised Models?
Jun 15, 2024



Discrete audio tokens have recently gained attention for their potential to bridge the gap between audio and language processing. Ideal audio tokens must preserve content, paralinguistic elements, speaker identity, and many other audio details. Current audio tokenization methods fall into two categories: Semantic tokens, acquired through quantization of Self-Supervised Learning (SSL) models, and Neural compression-based tokens (codecs). Although previous studies have benchmarked codec models to identify optimal configurations, the ideal setup for quantizing pretrained SSL models remains unclear. This paper explores the optimal configuration of semantic tokens across discriminative and generative tasks. We propose a scalable solution to train a universal vocoder across multiple SSL layers. Furthermore, an attention mechanism is employed to identify task-specific influential layers, enhancing the adaptability and performance of semantic tokens in diverse audio applications.
Listenable Maps for Zero-Shot Audio Classifiers
May 27, 2024Interpreting the decisions of deep learning models, including audio classifiers, is crucial for ensuring the transparency and trustworthiness of this technology. In this paper, we introduce LMAC-ZS (Listenable Maps for Audio Classifiers in the Zero-Shot context), which, to the best of our knowledge, is the first decoder-based post-hoc interpretation method for explaining the decisions of zero-shot audio classifiers. The proposed method utilizes a novel loss function that maximizes the faithfulness to the original similarity between a given text-and-audio pair. We provide an extensive evaluation using the Contrastive Language-Audio Pretraining (CLAP) model to showcase that our interpreter remains faithful to the decisions in a zero-shot classification context. Moreover, we qualitatively show that our method produces meaningful explanations that correlate well with different text prompts.