 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCL-MASR: A Continual Learning Benchmark for Multilingual ASR
Paper and Code
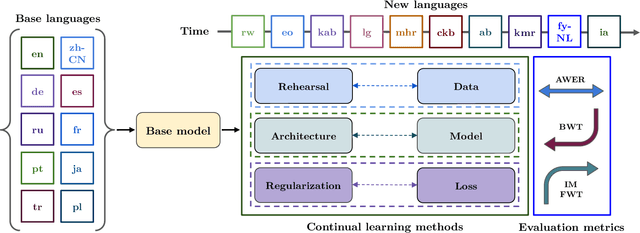
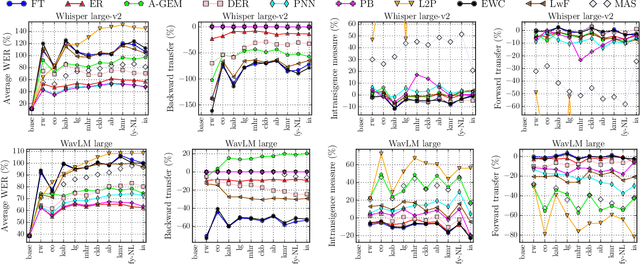
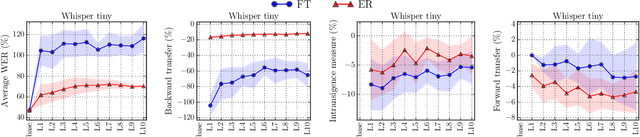
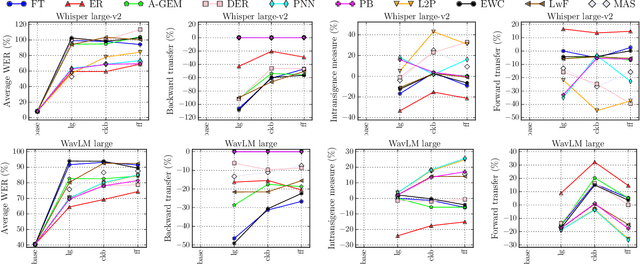
Modern multilingual automatic speech recognition (ASR) systems like Whisper have made it possible to transcribe audio in multiple languages with a single model. However, current state-of-the-art ASR models are typically evaluated on individual languages or in a multi-task setting, overlooking the challenge of continually learning new languages. There is insufficient research on how to add new languages without losing valuable information from previous data. Furthermore, existing continual learning benchmarks focus mostly on vision and language tasks, leaving continual learning for multilingual ASR largely unexplored. To bridge this gap, we propose CL-MASR, a benchmark designed for studying multilingual ASR in a continual learning setting. CL-MASR provides a diverse set of continual learning methods implemented on top of large-scale pretrained ASR models, along with common metrics to assess the effectiveness of learning new languages while addressing the issue of catastrophic forgetting. To the best of our knowledge, CL-MASR is the first continual learning benchmark for the multilingual ASR task. The code is available at https://github.com/speechbrain/benchmarks.