 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDASB -- Discrete Audio and Speech Benchmark
Paper and Code
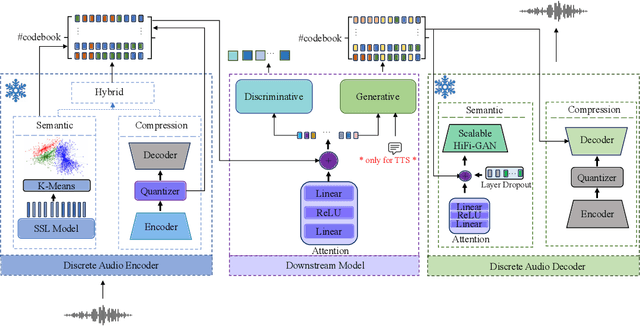
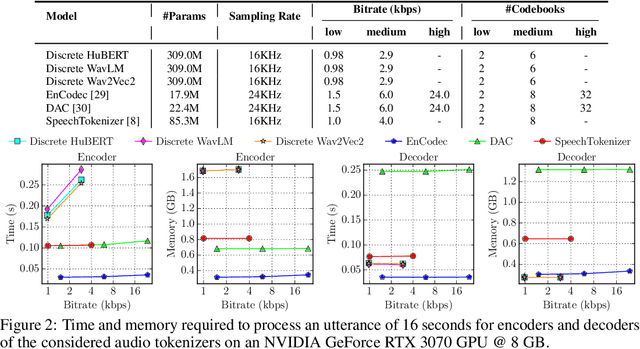
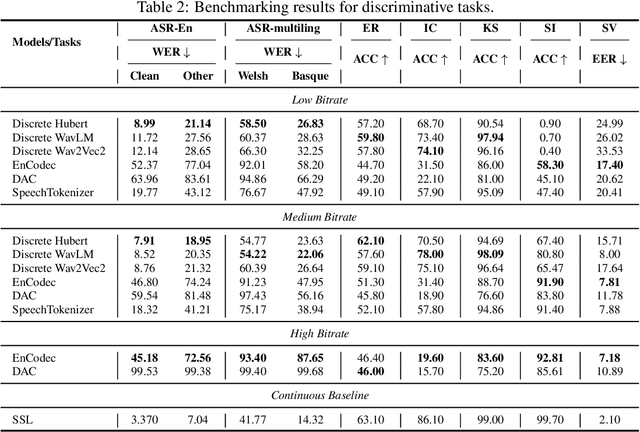
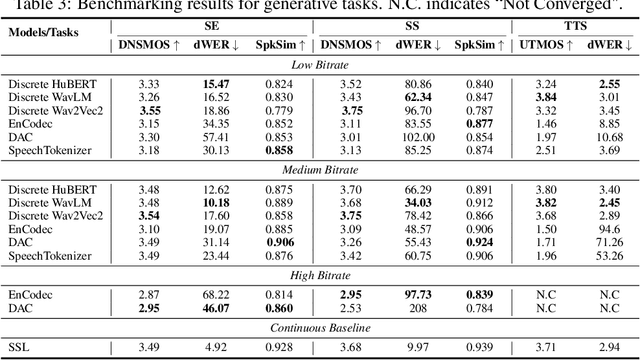
Discrete audio tokens have recently gained considerable attention for their potential to connect audio and language processing, enabling the creation of modern multimodal large language models. Ideal audio tokens must effectively preserve phonetic and semantic content along with paralinguistic information, speaker identity, and other details. While several types of audio tokens have been recently proposed, identifying the optimal tokenizer for various tasks is challenging due to the inconsistent evaluation settings in existing studies. To address this gap, we release the Discrete Audio and Speech Benchmark (DASB), a comprehensive leaderboard for benchmarking discrete audio tokens across a wide range of discriminative tasks, including speech recognition, speaker identification and verification, emotion recognition, keyword spotting, and intent classification, as well as generative tasks such as speech enhancement, separation, and text-to-speech. Our results show that, on average, semantic tokens outperform compression tokens across most discriminative and generative tasks. However, the performance gap between semantic tokens and standard continuous representations remains substantial, highlighting the need for further research in this field.