 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocal Modulation Networks for Interpretable Sound Classification
Paper and Code
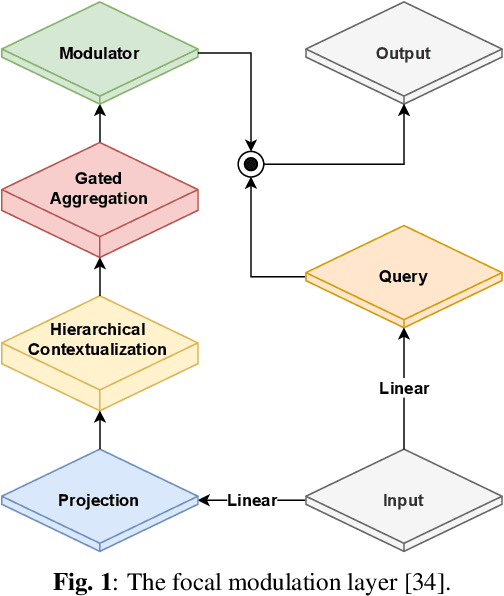
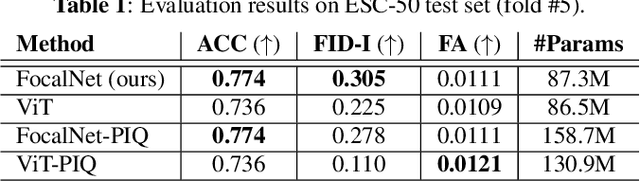
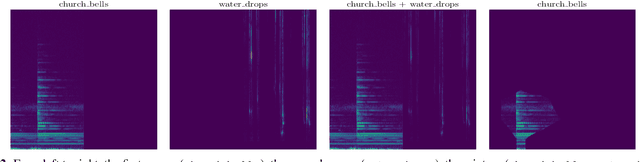
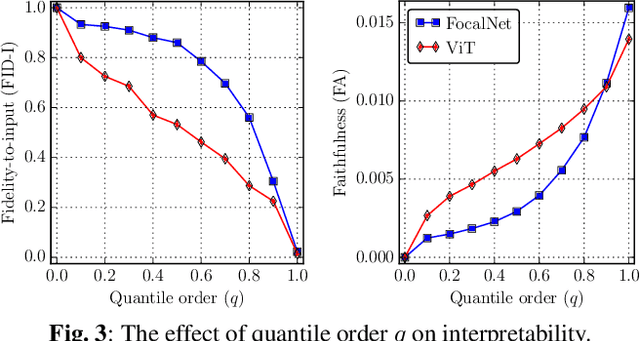
The increasing success of deep neural networks has raised concerns about their inherent black-box nature, posing challenges related to interpretability and trust. While there has been extensive exploration of interpretation techniques in vision and language, interpretability in the audio domain has received limited attention, primarily focusing on post-hoc explanations. This paper addresses the problem of interpretability by-design in the audio domain by utilizing the recently proposed attention-free focal modulation networks (FocalNets). We apply FocalNets to the task of environmental sound classification for the first time and evaluate their interpretability properties on the popular ESC-50 dataset. Our method outperforms a similarly sized vision transformer both in terms of accuracy and interpretability. Furthermore, it is competitive against PIQ, a method specifically designed for post-hoc interpretation in the audio domain.