 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoft Actor-Critic with Beta Policy via Implicit Reparameterization Gradients
Paper and Code

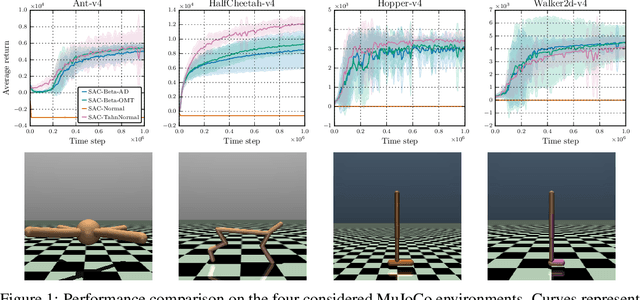

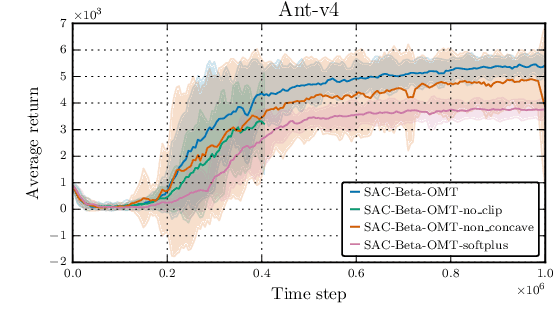
Recent advances in deep reinforcement learning have achieved impressive results in a wide range of complex tasks, but poor sample efficiency remains a major obstacle to real-world deployment. Soft actor-critic (SAC) mitigates this problem by combining stochastic policy optimization and off-policy learning, but its applicability is restricted to distributions whose gradients can be computed through the reparameterization trick. This limitation excludes several important examples such as the beta distribution, which was shown to improve the convergence rate of actor-critic algorithms in high-dimensional continuous control problems thanks to its bounded support. To address this issue, we investigate the use of implicit reparameterization, a powerful technique that extends the class of reparameterizable distributions. In particular, we use implicit reparameterization gradients to train SAC with the beta policy on simulated robot locomotion environments and compare its performance with common baselines. Experimental results show that the beta policy is a viable alternative, as it outperforms the normal policy and is on par with the squashed normal policy, which is the go-to choice for SAC. The code is available at https://github.com/lucadellalib/sac-beta.