 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOff-Policy Evaluation with Strategic Agents via Local Disclosure
Jun 05, 2026We study off-policy evaluation (OPE) under strategic behavior where decision subjects (or agents) respond to a decision maker's policy by strategically modifying their covariates. Such behavior induces a policy-dependent covariate shift, breaking the standard assumption in existing methods that covariates are exogenous to the policy. Related work addresses this challenge by imposing strong assumptions such as repeated interactions or full knowledge of agents' response behavior, substantially limiting its applicability to OPE. In contrast, we consider a one-shot OPE setting where the decision maker has only partial knowledge of the agents' response behavior. Our key insight is that disclosing local information through post-hoc explanations reveals agents' pre-strategic covariates prior to adaptation, mitigating the information loss induced by strategic behavior. Leveraging this structure, we estimate a statistical model for the agents' responses and construct a doubly robust estimator for policy value. By assuming that the agents' cost sensitivity follows a conditional log-normal distribution, we establish consistency of the proposed estimator and validate our approach empirically. More broadly, our results highlight how interaction design can mitigate information asymmetry by revealing otherwise hidden structure in agents' strategic responses.
Self-Supervised Laplace Approximation for Bayesian Uncertainty Quantification
May 12, 2026Approximate Bayesian inference typically revolves around computing the posterior parameter distribution. In practice, however, the main object of interest is often a model's predictions rather than its parameters. In this work, we propose to bypass the parameter posterior and focus directly on approximating the posterior predictive distribution. We achieve this by drawing inspiration from self-training within self-supervised and semi-supervised learning. Essentially, we quantify a Bayesian model's predictive uncertainty by refitting on self-predicted data. The idea is strikingly simple: If a model assigns high likelihood to self-predicted data, these predictions are of low uncertainty, and vice versa. This yields a deterministic, sampling-free approximation of the posterior predictive. The modular structure of our Self-Supervised Laplace Approximation (SSLA) further allows us to plug in different prior specifications, enabling classical Bayesian sensitivity (w.r.t. prior choice) analysis. In order to bypass expensive refitting, we further introduce an approximate version of SSLA, called ASSLA. We study (A)SSLA both theoretically and empirically in regression models ranging from Bayesian linear models to Bayesian neural networks. Across a wide array of regression tasks with simulated and real-world datasets, our methods outperform classical Laplace approximations in predictive calibration while remaining computationally efficient.
* Accepted for publication in TMLR (https://openreview.net/forum?id=T8w8L2t3JG)
Quantification of Credal Uncertainty: A Distance-Based Approach
Mar 28, 2026Credal sets, i.e., closed convex sets of probability measures, provide a natural framework to represent aleatoric and epistemic uncertainty in machine learning. Yet how to quantify these two types of uncertainty for a given credal set, particularly in multiclass classification, remains underexplored. In this paper, we propose a distance-based approach to quantify total, aleatoric, and epistemic uncertainty for credal sets. Concretely, we introduce a family of such measures within the framework of Integral Probability Metrics (IPMs). The resulting quantities admit clear semantic interpretations, satisfy natural theoretical desiderata, and remain computationally tractable for common choices of IPMs. We instantiate the framework with the total variation distance and obtain simple, efficient uncertainty measures for multiclass classification. In the binary case, this choice recovers established uncertainty measures, for which a principled multiclass generalization has so far been missing. Empirical results confirm practical usefulness, with favorable performance at low computational cost.
Incentive Aware AI Regulations: A Credal Characterisation
Mar 05, 2026While high-stakes ML applications demand strict regulations, strategic ML providers often evade them to lower development costs. To address this challenge, we cast AI regulation as a mechanism design problem under uncertainty and introduce regulation mechanisms: a framework that maps empirical evidence from models to a license for some market share. The providers can select from a set of licenses, effectively forcing them to bet on their model's ability to fulfil regulation. We aim at regulation mechanisms that achieve perfect market outcome, i.e. (a) drive non-compliant providers to self-exclude, and (b) ensure participation from compliant providers. We prove that a mechanism has perfect market outcome if and only if the set of non-compliant distributions forms a credal set, i.e., a closed, convex set of probability measures. This result connects mechanism design and imprecise probability by establishing a duality between regulation mechanisms and the set of non-compliant distributions. We also demonstrate these mechanisms in practice via experiments on regulating use of spurious features for prediction and fairness. Our framework provides new insights at the intersection of mechanism design and imprecise probability, offering a foundation for development of enforceable AI regulations.
Beyond Arrow: From Impossibility to Possibilities in Multi-Criteria Benchmarking
Feb 07, 2026Modern benchmarks such as HELM MMLU account for multiple metrics like accuracy, robustness and efficiency. When trying to turn these metrics into a single ranking, natural aggregation procedures can become incoherent or unstable to changes in the model set. We formalize this aggregation as a social choice problem where each metric induces a preference ranking over models on each dataset, and a benchmark operator aggregates these votes across metrics. While prior work has focused on Arrow's impossibility result, we argue that the impossibility often originates from pathological examples and identify sufficient conditions under which these disappear, and meaningful multi-criteria benchmarking becomes possible. In particular, we deal with three restrictions on the combinations of rankings and prove that on single-peaked, group-separable and distance-restricted preferences, the benchmark operator allows for the construction of well-behaved rankings of the involved models. Empirically, we investigate several modern benchmark suites like HELM MMLU and verify which structural conditions are fulfilled on which benchmark problems.
Performative Learning Theory
Feb 04, 2026Performative predictions influence the very outcomes they aim to forecast. We study performative predictions that affect a sample (e.g., only existing users of an app) and/or the whole population (e.g., all potential app users). This raises the question of how well models generalize under performativity. For example, how well can we draw insights about new app users based on existing users when both of them react to the app's predictions? We address this question by embedding performative predictions into statistical learning theory. We prove generalization bounds under performative effects on the sample, on the population, and on both. A key intuition behind our proofs is that in the worst case, the population negates predictions, while the sample deceptively fulfills them. We cast such self-negating and self-fulfilling predictions as min-max and min-min risk functionals in Wasserstein space, respectively. Our analysis reveals a fundamental trade-off between performatively changing the world and learning from it: the more a model affects data, the less it can learn from it. Moreover, our analysis results in a surprising insight on how to improve generalization guarantees by retraining on performatively distorted samples. We illustrate our bounds in a case study on prediction-informed assignments of unemployed German residents to job trainings, drawing upon administrative labor market records from 1975 to 2017 in Germany.
GUARD: Glocal Uncertainty-Aware Robust Decoding for Effective and Efficient Open-Ended Text Generation
Aug 28, 2025

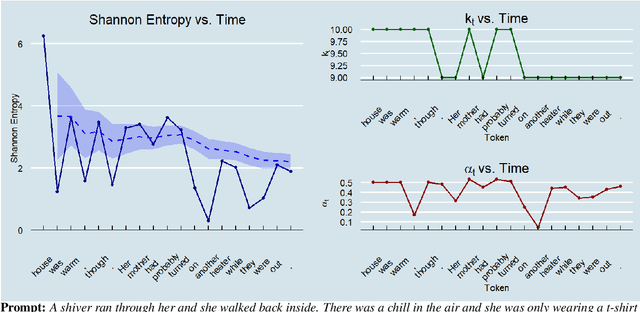

Open-ended text generation faces a critical challenge: balancing coherence with diversity in LLM outputs. While contrastive search-based decoding strategies have emerged to address this trade-off, their practical utility is often limited by hyperparameter dependence and high computational costs. We introduce GUARD, a self-adaptive decoding method that effectively balances these competing objectives through a novel "Glocal" uncertainty-driven framework. GUARD combines global entropy estimates with local entropy deviations to integrate both long-term and short-term uncertainty signals. We demonstrate that our proposed global entropy formulation effectively mitigates abrupt variations in uncertainty, such as sudden overconfidence or high entropy spikes, and provides theoretical guarantees of unbiasedness and consistency. To reduce computational overhead, we incorporate a simple yet effective token-count-based penalty into GUARD. Experimental results demonstrate that GUARD achieves a good balance between text diversity and coherence, while exhibiting substantial improvements in generation speed. In a more nuanced comparison study across different dimensions of text quality, both human and LLM evaluators validated its remarkable performance. Our code is available at https://github.com/YecanLee/GUARD.
Generalization Bounds and Stopping Rules for Learning with Self-Selected Data
May 12, 2025
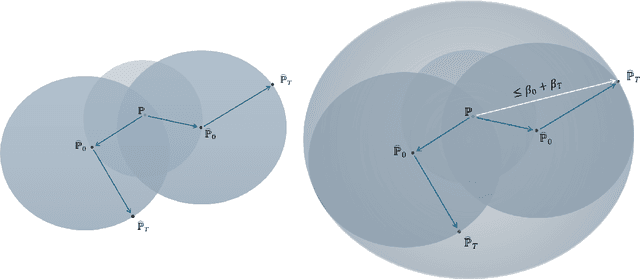
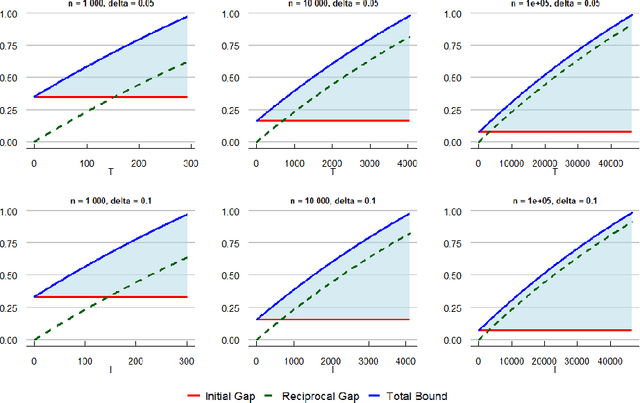
Many learning paradigms self-select training data in light of previously learned parameters. Examples include active learning, semi-supervised learning, bandits, or boosting. Rodemann et al. (2024) unify them under the framework of "reciprocal learning". In this article, we address the question of how well these methods can generalize from their self-selected samples. In particular, we prove universal generalization bounds for reciprocal learning using covering numbers and Wasserstein ambiguity sets. Our results require no assumptions on the distribution of self-selected data, only verifiable conditions on the algorithms. We prove results for both convergent and finite iteration solutions. The latter are anytime valid, thereby giving rise to stopping rules for a practitioner seeking to guarantee the out-of-sample performance of their reciprocal learning algorithm. Finally, we illustrate our bounds and stopping rules for reciprocal learning's special case of semi-supervised learning.
A Statistical Case Against Empirical Human-AI Alignment
Feb 20, 2025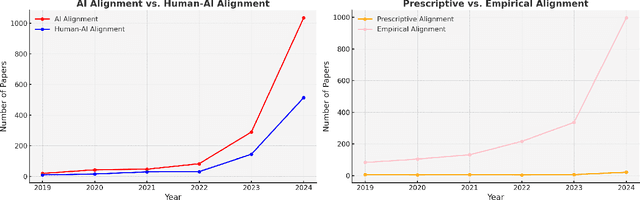



Empirical human-AI alignment aims to make AI systems act in line with observed human behavior. While noble in its goals, we argue that empirical alignment can inadvertently introduce statistical biases that warrant caution. This position paper thus advocates against naive empirical alignment, offering prescriptive alignment and a posteriori empirical alignment as alternatives. We substantiate our principled argument by tangible examples like human-centric decoding of language models.
Towards Better Open-Ended Text Generation: A Multicriteria Evaluation Framework
Oct 24, 2024



Open-ended text generation has become a prominent task in natural language processing due to the rise of powerful (large) language models. However, evaluating the quality of these models and the employed decoding strategies remains challenging because of trade-offs among widely used metrics such as coherence, diversity, and perplexity. Decoding methods often excel in some metrics while underperforming in others, complicating the establishment of a clear ranking. In this paper, we present novel ranking strategies within this multicriteria framework. Specifically, we employ benchmarking approaches based on partial orderings and present a new summary metric designed to balance existing automatic indicators, providing a more holistic evaluation of text generation quality. Furthermore, we discuss the alignment of these approaches with human judgments. Our experiments demonstrate that the proposed methods offer a robust way to compare decoding strategies, exhibit similarities with human preferences, and serve as valuable tools in guiding model selection for open-ended text generation tasks. Finally, we suggest future directions for improving evaluation methodologies in text generation. Our codebase, datasets, and models are publicly available.