 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDigitizing Nepal's Written Heritage: A Comprehensive HTR Pipeline for Old Nepali Manuscripts
Dec 18, 2025
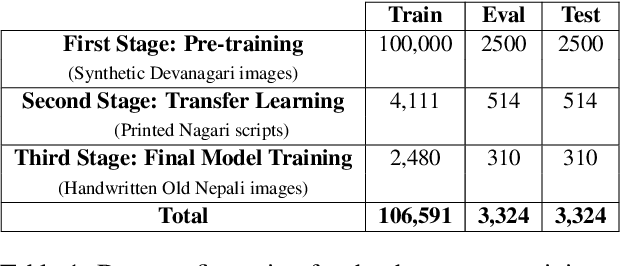

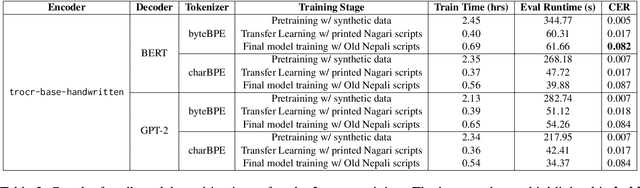
This paper presents the first end-to-end pipeline for Handwritten Text Recognition (HTR) for Old Nepali, a historically significant but low-resource language. We adopt a line-level transcription approach and systematically explore encoder-decoder architectures and data-centric techniques to improve recognition accuracy. Our best model achieves a Character Error Rate (CER) of 4.9\%. In addition, we implement and evaluate decoding strategies and analyze token-level confusions to better understand model behaviour and error patterns. While the dataset we used for evaluation is confidential, we release our training code, model configurations, and evaluation scripts to support further research in HTR for low-resource historical scripts.
GUARD: Glocal Uncertainty-Aware Robust Decoding for Effective and Efficient Open-Ended Text Generation
Aug 28, 2025Open-ended text generation faces a critical challenge: balancing coherence with diversity in LLM outputs. While contrastive search-based decoding strategies have emerged to address this trade-off, their practical utility is often limited by hyperparameter dependence and high computational costs. We introduce GUARD, a self-adaptive decoding method that effectively balances these competing objectives through a novel "Glocal" uncertainty-driven framework. GUARD combines global entropy estimates with local entropy deviations to integrate both long-term and short-term uncertainty signals. We demonstrate that our proposed global entropy formulation effectively mitigates abrupt variations in uncertainty, such as sudden overconfidence or high entropy spikes, and provides theoretical guarantees of unbiasedness and consistency. To reduce computational overhead, we incorporate a simple yet effective token-count-based penalty into GUARD. Experimental results demonstrate that GUARD achieves a good balance between text diversity and coherence, while exhibiting substantial improvements in generation speed. In a more nuanced comparison study across different dimensions of text quality, both human and LLM evaluators validated its remarkable performance. Our code is available at https://github.com/YecanLee/GUARD.
Modern Models, Medieval Texts: A POS Tagging Study of Old Occitan
Mar 10, 2025Large language models (LLMs) have demonstrated remarkable capabilities in natural language processing, yet their effectiveness in handling historical languages remains largely unexplored. This study examines the performance of open-source LLMs in part-of-speech (POS) tagging for Old Occitan, a historical language characterized by non-standardized orthography and significant diachronic variation. Through comparative analysis of two distinct corpora-hagiographical and medical texts-we evaluate how current models handle the inherent challenges of processing a low-resource historical language. Our findings demonstrate critical limitations in LLM performance when confronted with extreme orthographic and syntactic variability. We provide detailed error analysis and specific recommendations for improving model performance in historical language processing. This research advances our understanding of LLM capabilities in challenging linguistic contexts while offering practical insights for both computational linguistics and historical language studies.
A Statistical Case Against Empirical Human-AI Alignment
Feb 20, 2025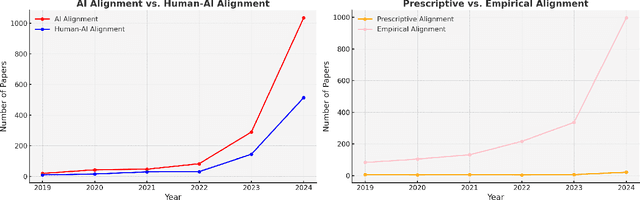



Empirical human-AI alignment aims to make AI systems act in line with observed human behavior. While noble in its goals, we argue that empirical alignment can inadvertently introduce statistical biases that warrant caution. This position paper thus advocates against naive empirical alignment, offering prescriptive alignment and a posteriori empirical alignment as alternatives. We substantiate our principled argument by tangible examples like human-centric decoding of language models.
Towards Better Open-Ended Text Generation: A Multicriteria Evaluation Framework
Oct 24, 2024



Open-ended text generation has become a prominent task in natural language processing due to the rise of powerful (large) language models. However, evaluating the quality of these models and the employed decoding strategies remains challenging because of trade-offs among widely used metrics such as coherence, diversity, and perplexity. Decoding methods often excel in some metrics while underperforming in others, complicating the establishment of a clear ranking. In this paper, we present novel ranking strategies within this multicriteria framework. Specifically, we employ benchmarking approaches based on partial orderings and present a new summary metric designed to balance existing automatic indicators, providing a more holistic evaluation of text generation quality. Furthermore, we discuss the alignment of these approaches with human judgments. Our experiments demonstrate that the proposed methods offer a robust way to compare decoding strategies, exhibit similarities with human preferences, and serve as valuable tools in guiding model selection for open-ended text generation tasks. Finally, we suggest future directions for improving evaluation methodologies in text generation. Our codebase, datasets, and models are publicly available.
Decoding Decoded: Understanding Hyperparameter Effects in Open-Ended Text Generation
Oct 08, 2024Decoding strategies for large language models (LLMs) are a critical but often underexplored aspect of text generation tasks. Since LLMs produce probability distributions over the entire vocabulary, various decoding methods have been developed to transform these probabilities into coherent and fluent text, each with its own set of hyperparameters. In this study, we present a large-scale, comprehensive analysis of how hyperparameter selection affects text quality in open-ended text generation across multiple LLMs, datasets, and evaluation metrics. Through an extensive sensitivity analysis, we provide practical guidelines for hyperparameter tuning and demonstrate the substantial influence of these choices on text quality. Using three established datasets, spanning factual domains (e.g., news) and creative domains (e.g., fiction), we show that hyperparameter tuning significantly impacts generation quality, though its effects vary across models and tasks. We offer in-depth insights into these effects, supported by both human evaluations and a synthesis of widely-used automatic evaluation metrics.
Adaptive Contrastive Search: Uncertainty-Guided Decoding for Open-Ended Text Generation
Jul 26, 2024Decoding from the output distributions of large language models to produce high-quality text is a complex challenge in language modeling. Various approaches, such as beam search, sampling with temperature, $k-$sampling, nucleus $p-$sampling, typical decoding, contrastive decoding, and contrastive search, have been proposed to address this problem, aiming to improve coherence, diversity, as well as resemblance to human-generated text. In this study, we introduce adaptive contrastive search, a novel decoding strategy extending contrastive search by incorporating an adaptive degeneration penalty, guided by the estimated uncertainty of the model at each generation step. This strategy is designed to enhance both the creativity and diversity of the language modeling process while at the same time producing coherent and high-quality generated text output. Our findings indicate performance enhancement in both aspects, across different model architectures and datasets, underscoring the effectiveness of our method in text generation tasks. Our code base, datasets, and models are publicly available.
A tailored Handwritten-Text-Recognition System for Medieval Latin
Aug 18, 2023The Bavarian Academy of Sciences and Humanities aims to digitize its Medieval Latin Dictionary. This dictionary entails record cards referring to lemmas in medieval Latin, a low-resource language. A crucial step of the digitization process is the Handwritten Text Recognition (HTR) of the handwritten lemmas found on these record cards. In our work, we introduce an end-to-end pipeline, tailored to the medieval Latin dictionary, for locating, extracting, and transcribing the lemmas. We employ two state-of-the-art (SOTA) image segmentation models to prepare the initial data set for the HTR task. Furthermore, we experiment with different transformer-based models and conduct a set of experiments to explore the capabilities of different combinations of vision encoders with a GPT-2 decoder. Additionally, we also apply extensive data augmentation resulting in a highly competitive model. The best-performing setup achieved a Character Error Rate (CER) of 0.015, which is even superior to the commercial Google Cloud Vision model, and shows more stable performance.
How Different Is Stereotypical Bias Across Languages?
Jul 14, 2023Recent studies have demonstrated how to assess the stereotypical bias in pre-trained English language models. In this work, we extend this branch of research in multiple different dimensions by systematically investigating (a) mono- and multilingual models of (b) different underlying architectures with respect to their bias in (c) multiple different languages. To that end, we make use of the English StereoSet data set (Nadeem et al., 2021), which we semi-automatically translate into German, French, Spanish, and Turkish. We find that it is of major importance to conduct this type of analysis in a multilingual setting, as our experiments show a much more nuanced picture as well as notable differences from the English-only analysis. The main takeaways from our analysis are that mGPT-2 (partly) shows surprising anti-stereotypical behavior across languages, English (monolingual) models exhibit the strongest bias, and the stereotypes reflected in the data set are least present in Turkish models. Finally, we release our codebase alongside the translated data sets and practical guidelines for the semi-automatic translation to encourage a further extension of our work to other languages.