 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Statistical Case Against Empirical Human-AI Alignment
Feb 20, 2025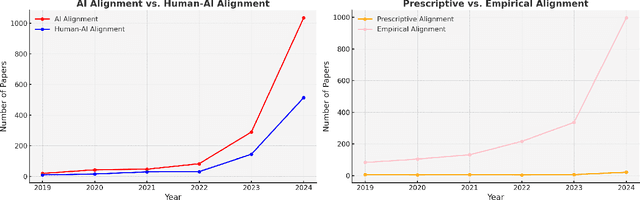



Empirical human-AI alignment aims to make AI systems act in line with observed human behavior. While noble in its goals, we argue that empirical alignment can inadvertently introduce statistical biases that warrant caution. This position paper thus advocates against naive empirical alignment, offering prescriptive alignment and a posteriori empirical alignment as alternatives. We substantiate our principled argument by tangible examples like human-centric decoding of language models.
Efficient SAGE Estimation via Causal Structure Learning
Apr 06, 2023
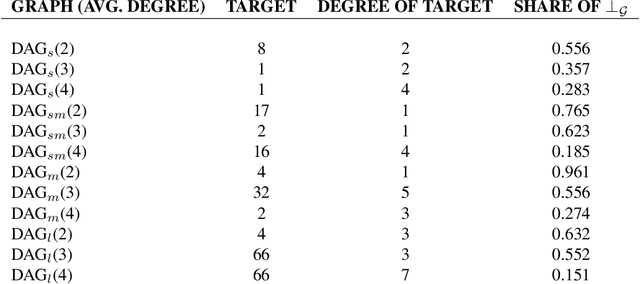
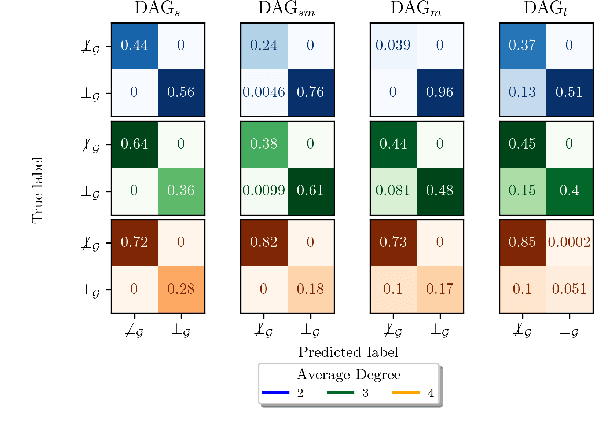
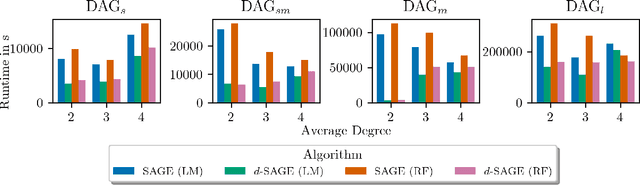
The Shapley Additive Global Importance (SAGE) value is a theoretically appealing interpretability method that fairly attributes global importance to a model's features. However, its exact calculation requires the computation of the feature's surplus performance contributions over an exponential number of feature sets. This is computationally expensive, particularly because estimating the surplus contributions requires sampling from conditional distributions. Thus, SAGE approximation algorithms only take a fraction of the feature sets into account. We propose $d$-SAGE, a method that accelerates SAGE approximation. $d$-SAGE is motivated by the observation that conditional independencies (CIs) between a feature and the model target imply zero surplus contributions, such that their computation can be skipped. To identify CIs, we leverage causal structure learning (CSL) to infer a graph that encodes (conditional) independencies in the data as $d$-separations. This is computationally more efficient because the expense of the one-time graph inference and the $d$-separation queries is negligible compared to the expense of surplus contribution evaluations. Empirically we demonstrate that $d$-SAGE enables the efficient and accurate estimation of SAGE values.