 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Conversational Brain-Artificial Intelligence Interface
Feb 22, 2024



We introduce Brain-Artificial Intelligence Interfaces (BAIs) as a new class of Brain-Computer Interfaces (BCIs). Unlike conventional BCIs, which rely on intact cognitive capabilities, BAIs leverage the power of artificial intelligence to replace parts of the neuro-cognitive processing pipeline. BAIs allow users to accomplish complex tasks by providing high-level intentions, while a pre-trained AI agent determines low-level details. This approach enlarges the target audience of BCIs to individuals with cognitive impairments, a population often excluded from the benefits of conventional BCIs. We present the general concept of BAIs and illustrate the potential of this new approach with a Conversational BAI based on EEG. In particular, we show in an experiment with simulated phone conversations that the Conversational BAI enables complex communication without the need to generate language. Our work thus demonstrates, for the first time, the ability of a speech neuroprosthesis to enable fluent communication in realistic scenarios with non-invasive technologies.
Efficient SAGE Estimation via Causal Structure Learning
Apr 06, 2023
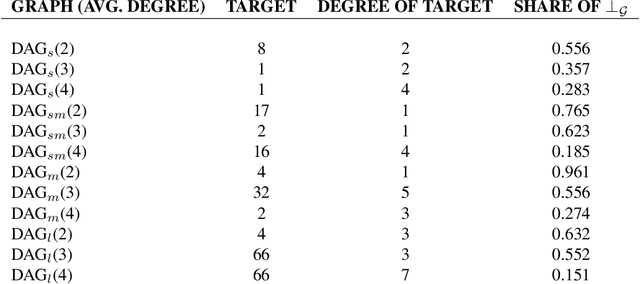
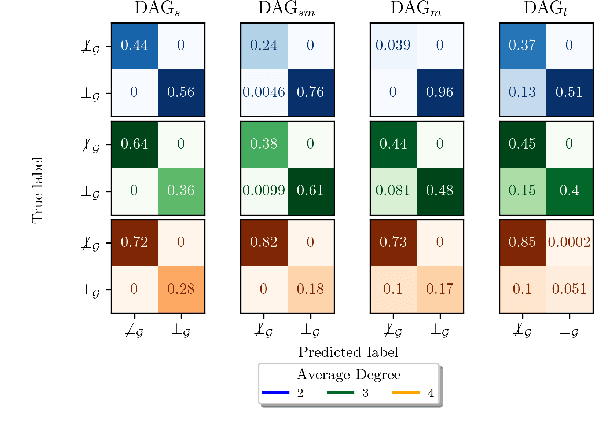
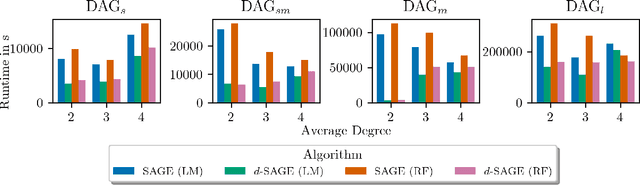
The Shapley Additive Global Importance (SAGE) value is a theoretically appealing interpretability method that fairly attributes global importance to a model's features. However, its exact calculation requires the computation of the feature's surplus performance contributions over an exponential number of feature sets. This is computationally expensive, particularly because estimating the surplus contributions requires sampling from conditional distributions. Thus, SAGE approximation algorithms only take a fraction of the feature sets into account. We propose $d$-SAGE, a method that accelerates SAGE approximation. $d$-SAGE is motivated by the observation that conditional independencies (CIs) between a feature and the model target imply zero surplus contributions, such that their computation can be skipped. To identify CIs, we leverage causal structure learning (CSL) to infer a graph that encodes (conditional) independencies in the data as $d$-separations. This is computationally more efficient because the expense of the one-time graph inference and the $d$-separation queries is negligible compared to the expense of surplus contribution evaluations. Empirically we demonstrate that $d$-SAGE enables the efficient and accurate estimation of SAGE values.
Improvement-Focused Causal Recourse (ICR)
Oct 27, 2022Algorithmic recourse recommendations, such as Karimi et al.'s (2021) causal recourse (CR), inform stakeholders of how to act to revert unfavourable decisions. However, some actions lead to acceptance (i.e., revert the model's decision) but do not lead to improvement (i.e., may not revert the underlying real-world state). To recommend such actions is to recommend fooling the predictor. We introduce a novel method, Improvement-Focused Causal Recourse (ICR), which involves a conceptual shift: Firstly, we require ICR recommendations to guide towards improvement. Secondly, we do not tailor the recommendations to be accepted by a specific predictor. Instead, we leverage causal knowledge to design decision systems that predict accurately pre- and post-recourse. As a result, improvement guarantees translate into acceptance guarantees. We demonstrate that given correct causal knowledge, ICR, in contrast to existing approaches, guides towards both acceptance and improvement.
2021 BEETL Competition: Advancing Transfer Learning for Subject Independence & Heterogenous EEG Data Sets
Feb 14, 2022
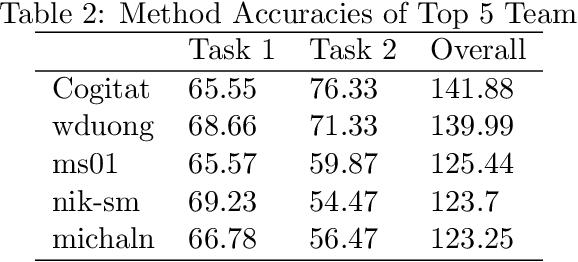
Transfer learning and meta-learning offer some of the most promising avenues to unlock the scalability of healthcare and consumer technologies driven by biosignal data. This is because current methods cannot generalise well across human subjects' data and handle learning from different heterogeneously collected data sets, thus limiting the scale of training data. On the other side, developments in transfer learning would benefit significantly from a real-world benchmark with immediate practical application. Therefore, we pick electroencephalography (EEG) as an exemplar for what makes biosignal machine learning hard. We design two transfer learning challenges around diagnostics and Brain-Computer-Interfacing (BCI), that have to be solved in the face of low signal-to-noise ratios, major variability among subjects, differences in the data recording sessions and techniques, and even between the specific BCI tasks recorded in the dataset. Task 1 is centred on the field of medical diagnostics, addressing automatic sleep stage annotation across subjects. Task 2 is centred on Brain-Computer Interfacing (BCI), addressing motor imagery decoding across both subjects and data sets. The BEETL competition with its over 30 competing teams and its 3 winning entries brought attention to the potential of deep transfer learning and combinations of set theory and conventional machine learning techniques to overcome the challenges. The results set a new state-of-the-art for the real-world BEETL benchmark.
A Causal Perspective on Meaningful and Robust Algorithmic Recourse
Jul 16, 2021
Algorithmic recourse explanations inform stakeholders on how to act to revert unfavorable predictions. However, in general ML models do not predict well in interventional distributions. Thus, an action that changes the prediction in the desired way may not lead to an improvement of the underlying target. Such recourse is neither meaningful nor robust to model refits. Extending the work of Karimi et al. (2021), we propose meaningful algorithmic recourse (MAR) that only recommends actions that improve both prediction and target. We justify this selection constraint by highlighting the differences between model audit and meaningful, actionable recourse explanations. Additionally, we introduce a relaxation of MAR called effective algorithmic recourse (EAR), which, under certain assumptions, yields meaningful recourse by only allowing interventions on causes of the target.
Decomposition of Global Feature Importance into Direct and Associative Components (DEDACT)
Jun 15, 2021
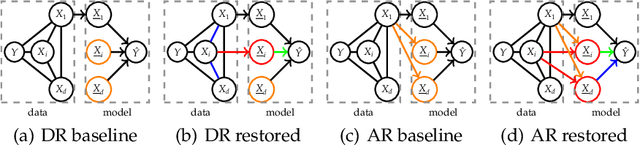
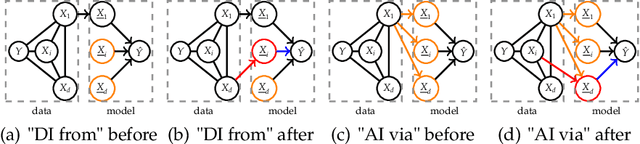
Global model-agnostic feature importance measures either quantify whether features are directly used for a model's predictions (direct importance) or whether they contain prediction-relevant information (associative importance). Direct importance provides causal insight into the model's mechanism, yet it fails to expose the leakage of information from associated but not directly used variables. In contrast, associative importance exposes information leakage but does not provide causal insight into the model's mechanism. We introduce DEDACT - a framework to decompose well-established direct and associative importance measures into their respective associative and direct components. DEDACT provides insight into both the sources of prediction-relevant information in the data and the direct and indirect feature pathways by which the information enters the model. We demonstrate the method's usefulness on simulated examples.
A Distance Covariance-based Kernel for Nonlinear Causal Clustering in Heterogeneous Populations
Jun 07, 2021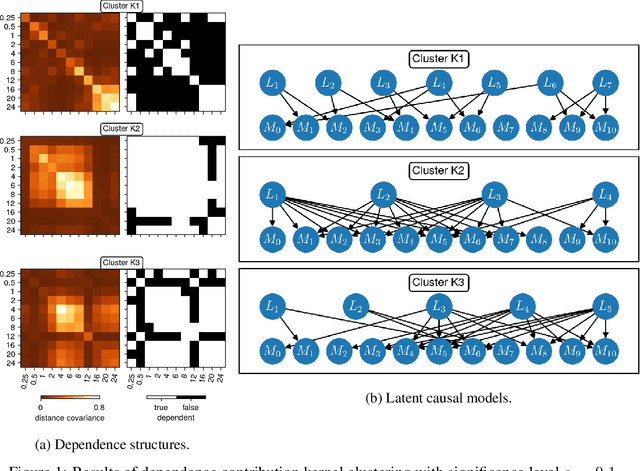
We consider the problem of causal structure learning in the setting of heterogeneous populations, i.e., populations in which a single causal structure does not adequately represent all population members, as is common in biological and social sciences. To this end, we introduce a distance covariance-based kernel designed specifically to measure the similarity between the underlying nonlinear causal structures of different samples. This kernel enables us to perform clustering to identify the homogeneous subpopulations. Indeed, we prove the corresponding feature map is a statistically consistent estimator of nonlinear independence structure, rendering the kernel itself a statistical test for the hypothesis that sets of samples come from different generating causal structures. We can then use existing methods to learn a causal structure for each of these subpopulations. We demonstrate using our kernel for causal clustering with an application in genetics, allowing us to reason about the latent transcription factor networks regulating measured gene expression levels.
Relative Feature Importance
Jul 16, 2020
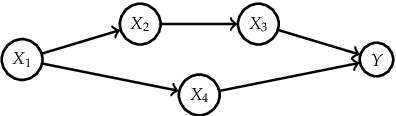
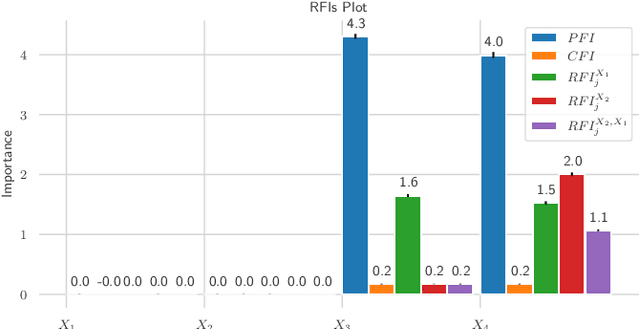
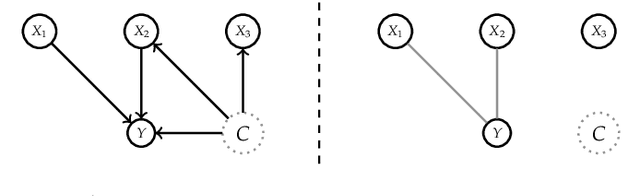
Interpretable Machine Learning (IML) methods are used to gain insight into the relevance of a feature of interest for the performance of a model. Commonly used IML methods differ in whether they consider features of interest in isolation, e.g., Permutation Feature Importance (PFI), or in relation to all remaining feature variables, e.g., Conditional Feature Importance (CFI). As such, the perturbation mechanisms inherent to PFI and CFI represent extreme reference points. We introduce Relative Feature Importance (RFI), a generalization of PFI and CFI that allows for a more nuanced feature importance computation beyond the PFI versus CFI dichotomy. With RFI, the importance of a feature relative to any other subset of features can be assessed, including variables that were not available at training time. We derive general interpretation rules for RFI based on a detailed theoretical analysis of the implications of relative feature relevance, and demonstrate the method's usefulness on simulated examples.
Pitfalls to Avoid when Interpreting Machine Learning Models
Jul 08, 2020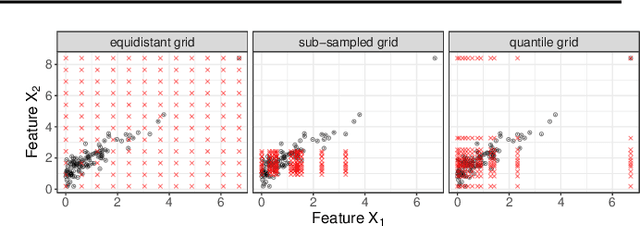
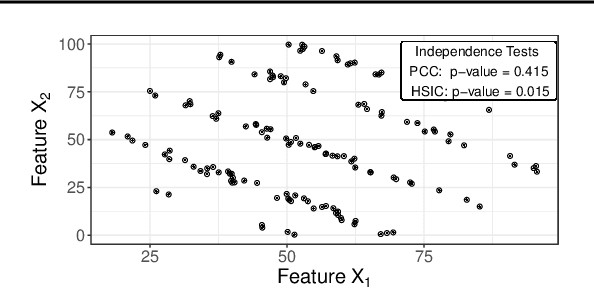
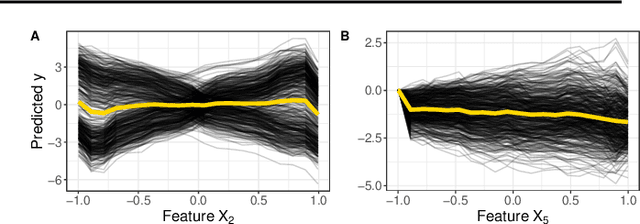
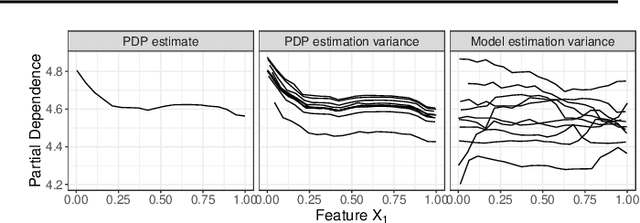
Modern requirements for machine learning (ML) models include both high predictive performance and model interpretability. A growing number of techniques provide model interpretations, but can lead to wrong conclusions if applied incorrectly. We illustrate pitfalls of ML model interpretation such as bad model generalization, dependent features, feature interactions or unjustified causal interpretations. Our paper addresses ML practitioners by raising awareness of pitfalls and pointing out solutions for correct model interpretation, as well as ML researchers by discussing open issues for further research.
Measurement Dependence Inducing Latent Causal Models
Oct 19, 2019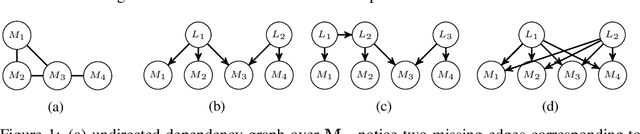
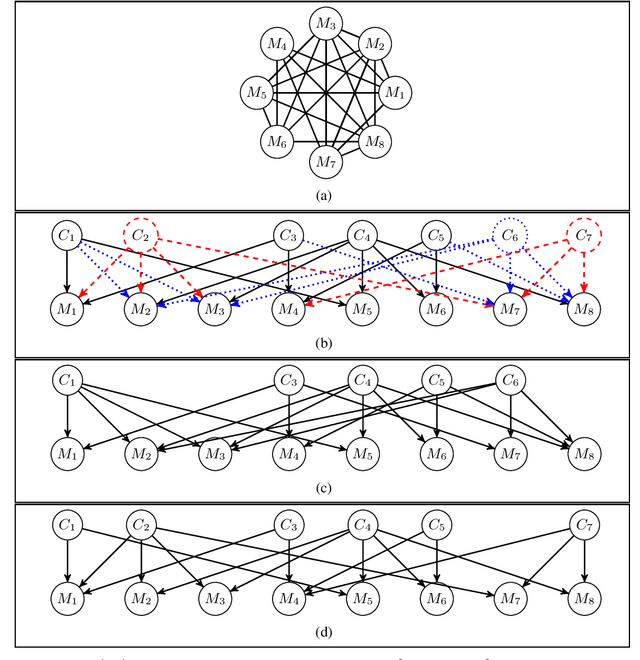
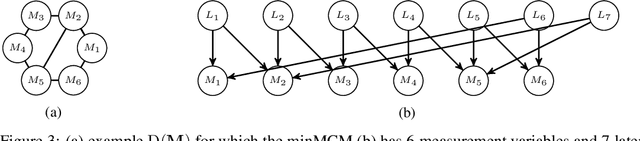
We consider the task of causal structure learning over measurement dependence inducing latent (MeDIL) causal models. We show that this task can be framed in terms of the graph theoretical problem of finding edge clique covers, resulting in a simple algorithm for returning minimal MeDIL causal models (minMCMs). This algorithm is non-parametric, requiring no assumptions about linearity or Gaussianity. Furthermore, despite rather weak assumptions about the class of MeDIL causal models, we show that minimality in minMCMs implies three rather specific and interesting properties: first, minMCMs provide lower bounds on (i) the number of latent causal variables and (ii) the number of functional causal relations that are required to model a complex system at any level of granularity; second, a minMCM contains no causal links between the latent variables; and third, in contrast to factor analysis, a minMCM may require more latent than measurement variables.