 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Arrow: From Impossibility to Possibilities in Multi-Criteria Benchmarking
Feb 07, 2026Modern benchmarks such as HELM MMLU account for multiple metrics like accuracy, robustness and efficiency. When trying to turn these metrics into a single ranking, natural aggregation procedures can become incoherent or unstable to changes in the model set. We formalize this aggregation as a social choice problem where each metric induces a preference ranking over models on each dataset, and a benchmark operator aggregates these votes across metrics. While prior work has focused on Arrow's impossibility result, we argue that the impossibility often originates from pathological examples and identify sufficient conditions under which these disappear, and meaningful multi-criteria benchmarking becomes possible. In particular, we deal with three restrictions on the combinations of rankings and prove that on single-peaked, group-separable and distance-restricted preferences, the benchmark operator allows for the construction of well-behaved rankings of the involved models. Empirically, we investigate several modern benchmark suites like HELM MMLU and verify which structural conditions are fulfilled on which benchmark problems.
Consensus in Motion: A Case of Dynamic Rationality of Sequential Learning in Probability Aggregation
Apr 20, 2025We propose a framework for probability aggregation based on propositional probability logic. Unlike conventional judgment aggregation, which focuses on static rationality, our model addresses dynamic rationality by ensuring that collective beliefs update consistently with new information. We show that any consensus-compatible and independent aggregation rule on a non-nested agenda is necessarily linear. Furthermore, we provide sufficient conditions for a fair learning process, where individuals initially agree on a specified subset of propositions known as the common ground, and new information is restricted to this shared foundation. This guarantees that updating individual judgments via Bayesian conditioning-whether performed before or after aggregation-yields the same collective belief. A distinctive feature of our framework is its treatment of sequential decision-making, which allows new information to be incorporated progressively through multiple stages while maintaining the established common ground. We illustrate our findings with a running example in a political scenario concerning healthcare and immigration policies.
A Statistical Case Against Empirical Human-AI Alignment
Feb 20, 2025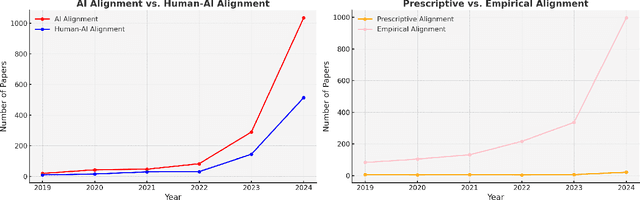



Empirical human-AI alignment aims to make AI systems act in line with observed human behavior. While noble in its goals, we argue that empirical alignment can inadvertently introduce statistical biases that warrant caution. This position paper thus advocates against naive empirical alignment, offering prescriptive alignment and a posteriori empirical alignment as alternatives. We substantiate our principled argument by tangible examples like human-centric decoding of language models.
Contributions to the Decision Theoretic Foundations of Machine Learning and Robust Statistics under Weakly Structured Information
Jan 17, 2025This habilitation thesis is cumulative and, therefore, is collecting and connecting research that I (together with several co-authors) have conducted over the last few years. Thus, the absolute core of the work is formed by the ten publications listed on page 5 under the name Contributions 1 to 10. The references to the complete versions of these articles are also found in this list, making them as easily accessible as possible for readers wishing to dive deep into the different research projects. The chapters following this thesis, namely Parts A to C and the concluding remarks, serve to place the articles in a larger scientific context, to (briefly) explain their respective content on a less formal level, and to highlight some interesting perspectives for future research in their respective contexts. Naturally, therefore, the following presentation has neither the level of detail nor the formal rigor that can (hopefully) be found in the papers. The purpose of the following text is to provide the reader an easy and high-level access to this interesting and important research field as a whole, thereby, advertising it to a broader audience.
Reciprocal Learning
Aug 12, 2024


We demonstrate that a wide array of machine learning algorithms are specific instances of one single paradigm: reciprocal learning. These instances range from active learning over multi-armed bandits to self-training. We show that all these algorithms do not only learn parameters from data but also vice versa: They iteratively alter training data in a way that depends on the current model fit. We introduce reciprocal learning as a generalization of these algorithms using the language of decision theory. This allows us to study under what conditions they converge. The key is to guarantee that reciprocal learning contracts such that the Banach fixed-point theorem applies. In this way, we find that reciprocal learning algorithms converge at linear rates to an approximately optimal model under relatively mild assumptions on the loss function, if their predictions are probabilistic and the sample adaption is both non-greedy and either randomized or regularized. We interpret these findings and provide corollaries that relate them to specific active learning, self-training, and bandit algorithms.
Statistical Multicriteria Benchmarking via the GSD-Front
Jun 06, 2024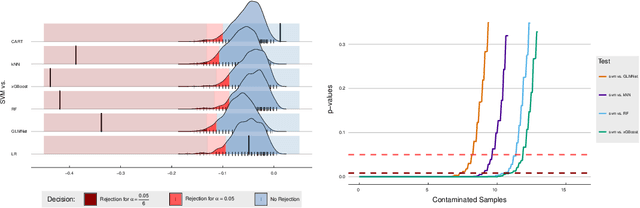
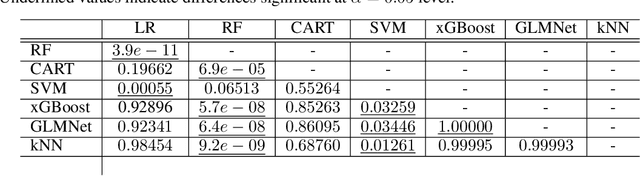
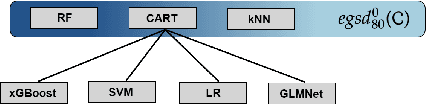
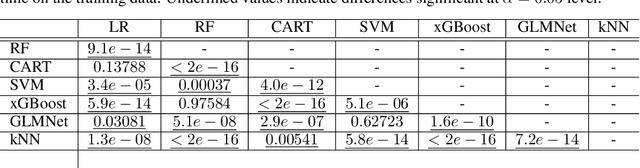
Given the vast number of classifiers that have been (and continue to be) proposed, reliable methods for comparing them are becoming increasingly important. The desire for reliability is broken down into three main aspects: (1) Comparisons should allow for different quality metrics simultaneously. (2) Comparisons should take into account the statistical uncertainty induced by the choice of benchmark suite. (3) The robustness of the comparisons under small deviations in the underlying assumptions should be verifiable. To address (1), we propose to compare classifiers using a generalized stochastic dominance ordering (GSD) and present the GSD-front as an information-efficient alternative to the classical Pareto-front. For (2), we propose a consistent statistical estimator for the GSD-front and construct a statistical test for whether a (potentially new) classifier lies in the GSD-front of a set of state-of-the-art classifiers. For (3), we relax our proposed test using techniques from robust statistics and imprecise probabilities. We illustrate our concepts on the benchmark suite PMLB and on the platform OpenML.
Semi-Supervised Learning guided by the Generalized Bayes Rule under Soft Revision
May 24, 2024
We provide a theoretical and computational investigation of the Gamma-Maximin method with soft revision, which was recently proposed as a robust criterion for pseudo-label selection (PLS) in semi-supervised learning. Opposed to traditional methods for PLS we use credal sets of priors ("generalized Bayes") to represent the epistemic modeling uncertainty. These latter are then updated by the Gamma-Maximin method with soft revision. We eventually select pseudo-labeled data that are most likely in light of the least favorable distribution from the so updated credal set. We formalize the task of finding optimal pseudo-labeled data w.r.t. the Gamma-Maximin method with soft revision as an optimization problem. A concrete implementation for the class of logistic models then allows us to compare the predictive power of the method with competing approaches. It is observed that the Gamma-Maximin method with soft revision can achieve very promising results, especially when the proportion of labeled data is low.
Comparing Machine Learning Algorithms by Union-Free Generic Depth
Dec 20, 2023We propose a framework for descriptively analyzing sets of partial orders based on the concept of depth functions. Despite intensive studies in linear and metric spaces, there is very little discussion on depth functions for non-standard data types such as partial orders. We introduce an adaptation of the well-known simplicial depth to the set of all partial orders, the union-free generic (ufg) depth. Moreover, we utilize our ufg depth for a comparison of machine learning algorithms based on multidimensional performance measures. Concretely, we provide two examples of classifier comparisons on samples of standard benchmark data sets. Our results demonstrate promisingly the wide variety of different analysis approaches based on ufg methods. Furthermore, the examples outline that our approach differs substantially from existing benchmarking approaches, and thus adds a new perspective to the vivid debate on classifier comparison.
Robust Statistical Comparison of Random Variables with Locally Varying Scale of Measurement
Jun 22, 2023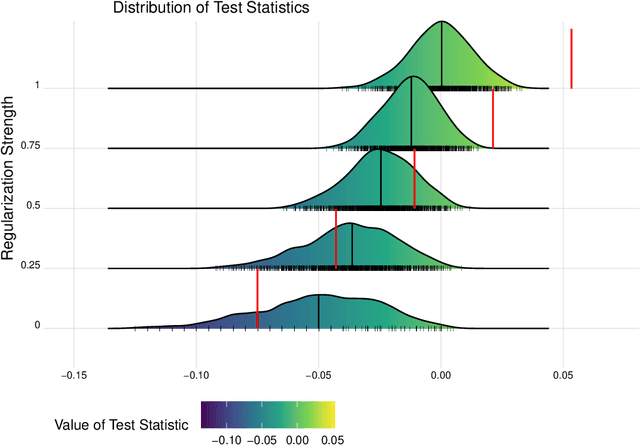
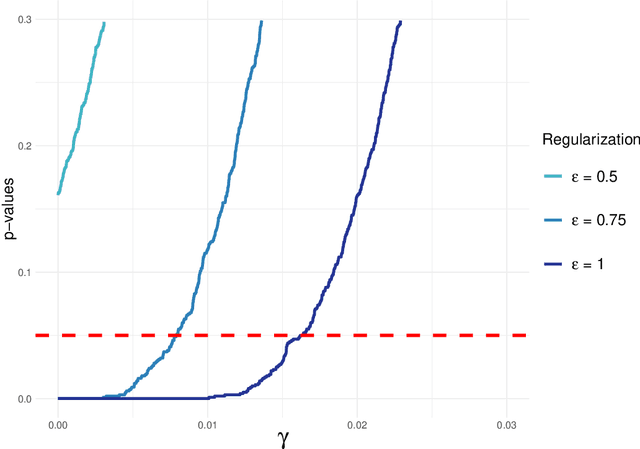
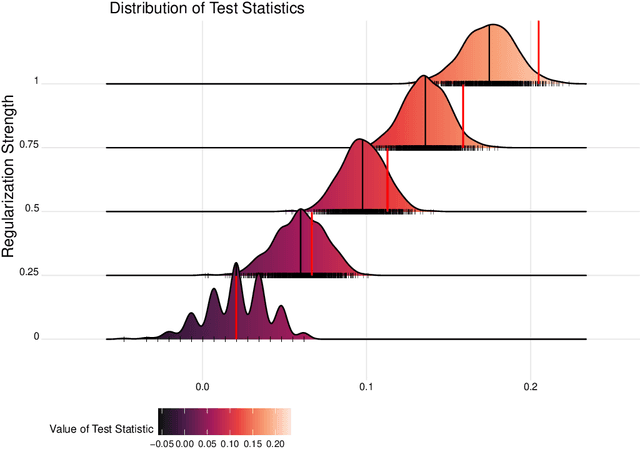
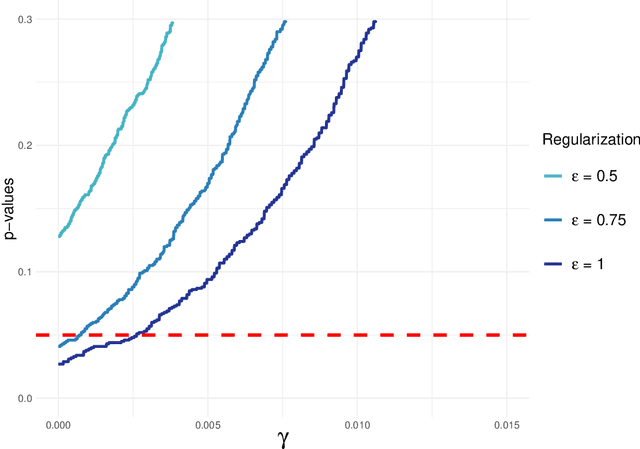
Spaces with locally varying scale of measurement, like multidimensional structures with differently scaled dimensions, are pretty common in statistics and machine learning. Nevertheless, it is still understood as an open question how to exploit the entire information encoded in them properly. We address this problem by considering an order based on (sets of) expectations of random variables mapping into such non-standard spaces. This order contains stochastic dominance and expectation order as extreme cases when no, or respectively perfect, cardinal structure is given. We derive a (regularized) statistical test for our proposed generalized stochastic dominance (GSD) order, operationalize it by linear optimization, and robustify it by imprecise probability models. Our findings are illustrated with data from multidimensional poverty measurement, finance, and medicine.
Depth Functions for Partial Orders with a Descriptive Analysis of Machine Learning Algorithms
Apr 19, 2023We propose a framework for descriptively analyzing sets of partial orders based on the concept of depth functions. Despite intensive studies of depth functions in linear and metric spaces, there is very little discussion on depth functions for non-standard data types such as partial orders. We introduce an adaptation of the well-known simplicial depth to the set of all partial orders, the union-free generic (ufg) depth. Moreover, we utilize our ufg depth for a comparison of machine learning algorithms based on multidimensional performance measures. Concretely, we analyze the distribution of different classifier performances over a sample of standard benchmark data sets. Our results promisingly demonstrate that our approach differs substantially from existing benchmarking approaches and, therefore, adds a new perspective to the vivid debate on the comparison of classifiers.