 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAfrica-Centric Self-Supervised Pre-Training for Multilingual Speech Representation in a Sub-Saharan Context
Apr 05, 2024

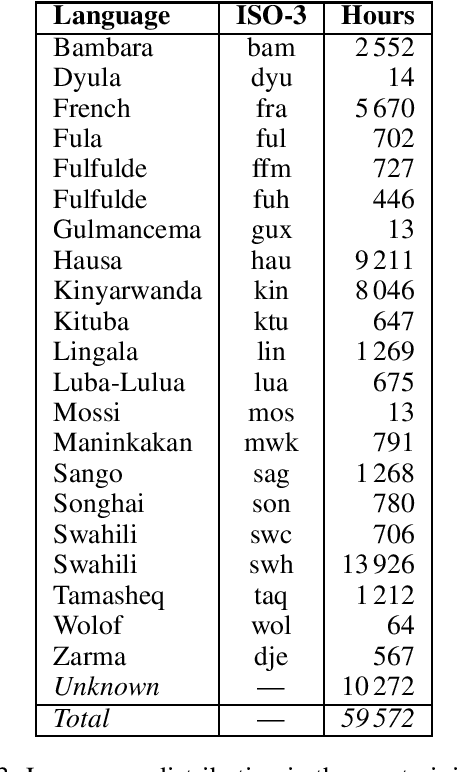
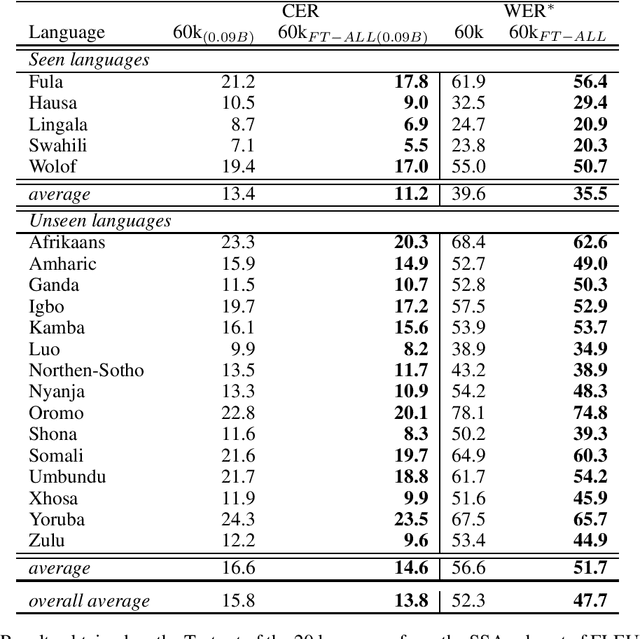
We present the first self-supervised multilingual speech model trained exclusively on African speech. The model learned from nearly 60 000 hours of unlabeled speech segments in 21 languages and dialects spoken in sub-Saharan Africa. On the SSA subset of the FLEURS-102 dataset, our approach based on a HuBERT$_{base}$ (0.09B) architecture shows competitive results, for ASR downstream task, compared to the w2v-bert-51 (0.6B) pre-trained model proposed in the FLEURS benchmark, while being more efficient by using 7x less data and 6x less parameters. Furthermore, in the context of a LID downstream task, our approach outperforms FLEURS baselines accuracy by over 22\%.
Kallaama: A Transcribed Speech Dataset about Agriculture in the Three Most Widely Spoken Languages in Senegal
Apr 02, 2024This work is part of the Kallaama project, whose objective is to produce and disseminate national languages corpora for speech technologies developments, in the field of agriculture. Except for Wolof, which benefits from some language data for natural language processing, national languages of Senegal are largely ignored by language technology providers. However, such technologies are keys to the protection, promotion and teaching of these languages. Kallaama focuses on the 3 main spoken languages by Senegalese people: Wolof, Pulaar and Sereer. These languages are widely spoken by the population, with around 10 million of native Senegalese speakers, not to mention those outside the country. However, they remain under-resourced in terms of machine-readable data that can be used for automatic processing and language technologies, all the more so in the agricultural sector. We release a transcribed speech dataset containing 125 hours of recordings, about agriculture, in each of the above-mentioned languages. These resources are specifically designed for Automatic Speech Recognition purpose, including traditional approaches. To build such technologies, we provide textual corpora in Wolof and Pulaar, and a pronunciation lexicon containing 49,132 entries from the Wolof dataset.
Preuve de concept d'un bot vocal dialoguant en wolof
Apr 02, 2024This paper presents the proof-of-concept of the first automatic voice assistant ever built in Wolof language, the main vehicular language spoken in Senegal. This voicebot is the result of a collaborative research project between Orange Innovation in France, Orange Senegal (aka Sonatel) and ADNCorp, a small IT company based in Dakar, Senegal. The purpose of the voicebot is to provide information to Orange customers about the Sargal loyalty program of Orange Senegal by using the most natural mean to communicate: speech. The voicebot receives in input the customer's oral request that is then processed by a SLU system to reply to the customer's request using audio recordings. The first results of this proof-of-concept are encouraging as we achieved 22\% of WER for the ASR task and 78\% of F1-score on the NLU task.
* in French language
Machine Assisted Analysis of Vowel Length Contrasts in Wolof
Jun 01, 2017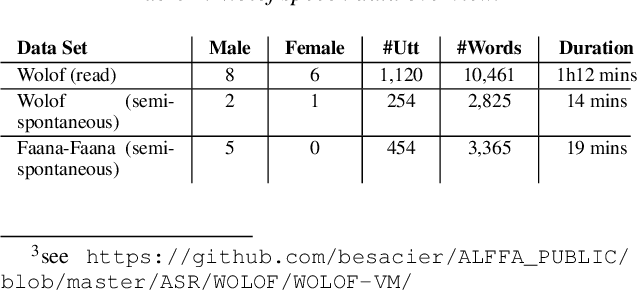

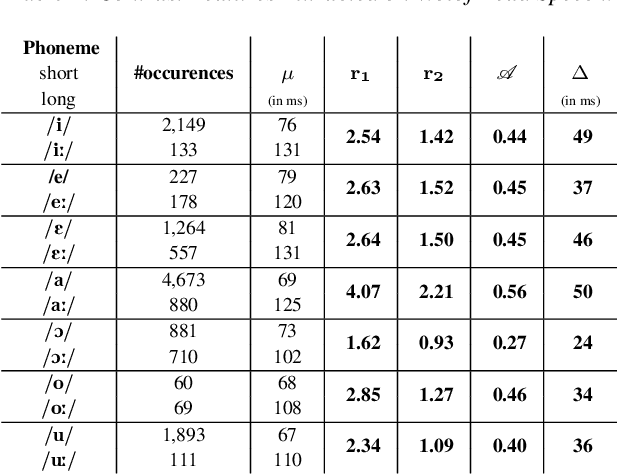

Growing digital archives and improving algorithms for automatic analysis of text and speech create new research opportunities for fundamental research in phonetics. Such empirical approaches allow statistical evaluation of a much larger set of hypothesis about phonetic variation and its conditioning factors (among them geographical / dialectal variants). This paper illustrates this vision and proposes to challenge automatic methods for the analysis of a not easily observable phenomenon: vowel length contrast. We focus on Wolof, an under-resourced language from Sub-Saharan Africa. In particular, we propose multiple features to make a fine evaluation of the degree of length contrast under different factors such as: read vs semi spontaneous speech ; standard vs dialectal Wolof. Our measures made fully automatically on more than 20k vowel tokens show that our proposed features can highlight different degrees of contrast for each vowel considered. We notably show that contrast is weaker in semi-spontaneous speech and in a non standard semi-spontaneous dialect.