 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Assisted Analysis of Vowel Length Contrasts in Wolof
Jun 01, 2017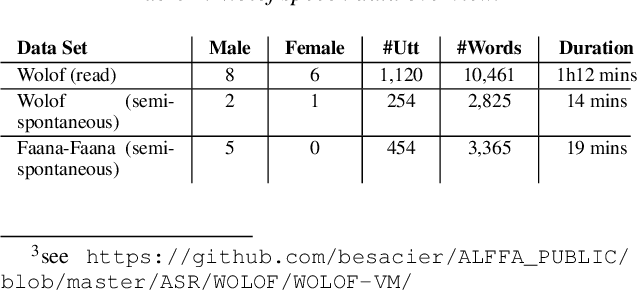

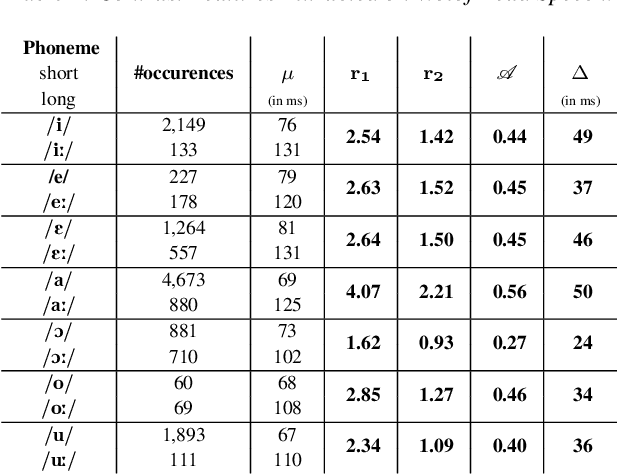

Growing digital archives and improving algorithms for automatic analysis of text and speech create new research opportunities for fundamental research in phonetics. Such empirical approaches allow statistical evaluation of a much larger set of hypothesis about phonetic variation and its conditioning factors (among them geographical / dialectal variants). This paper illustrates this vision and proposes to challenge automatic methods for the analysis of a not easily observable phenomenon: vowel length contrast. We focus on Wolof, an under-resourced language from Sub-Saharan Africa. In particular, we propose multiple features to make a fine evaluation of the degree of length contrast under different factors such as: read vs semi spontaneous speech ; standard vs dialectal Wolof. Our measures made fully automatically on more than 20k vowel tokens show that our proposed features can highlight different degrees of contrast for each vowel considered. We notably show that contrast is weaker in semi-spontaneous speech and in a non standard semi-spontaneous dialect.