Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAfrica-Centric Self-Supervised Pre-Training for Multilingual Speech Representation in a Sub-Saharan Context
Paper and Code
Apr 05, 2024

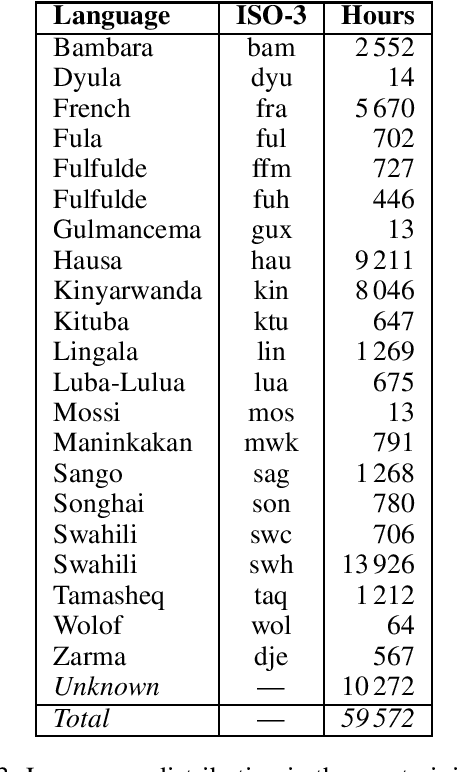
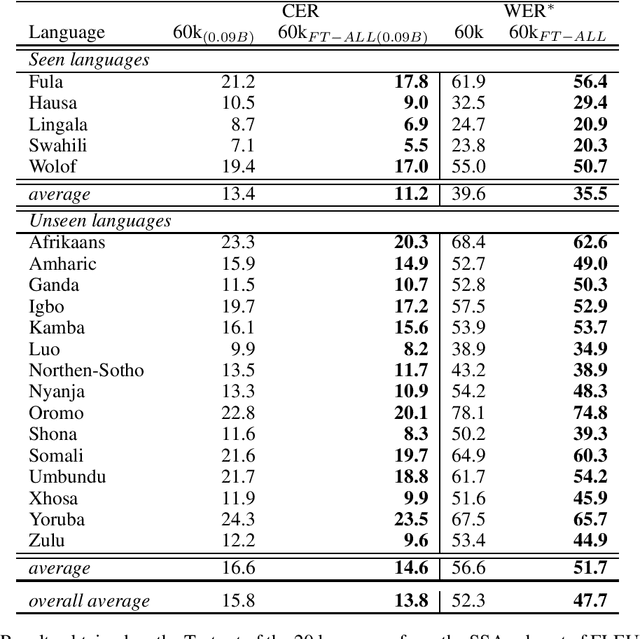
We present the first self-supervised multilingual speech model trained exclusively on African speech. The model learned from nearly 60 000 hours of unlabeled speech segments in 21 languages and dialects spoken in sub-Saharan Africa. On the SSA subset of the FLEURS-102 dataset, our approach based on a HuBERT$_{base}$ (0.09B) architecture shows competitive results, for ASR downstream task, compared to the w2v-bert-51 (0.6B) pre-trained model proposed in the FLEURS benchmark, while being more efficient by using 7x less data and 6x less parameters. Furthermore, in the context of a LID downstream task, our approach outperforms FLEURS baselines accuracy by over 22\%.
* To appear in AfricaNLP 2024
View paper on