 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA dual task learning approach to fine-tune a multilingual semantic speech encoder for Spoken Language Understanding
Jun 17, 2024Self-Supervised Learning is vastly used to efficiently represent speech for Spoken Language Understanding, gradually replacing conventional approaches. Meanwhile, textual SSL models are proposed to encode language-agnostic semantics. SAMU-XLSR framework employed this semantic information to enrich multilingual speech representations. A recent study investigated SAMU-XLSR in-domain semantic enrichment by specializing it on downstream transcriptions, leading to state-of-the-art results on a challenging SLU task. This study's interest lies in the loss of multilingual performances and lack of specific-semantics training induced by such specialization in close languages without any SLU implication. We also consider SAMU-XLSR's loss of initial cross-lingual abilities due to a separate SLU fine-tuning. Therefore, this paper proposes a dual task learning approach to improve SAMU-XLSR semantic enrichment while considering distant languages for multilingual and language portability experiments.
Semantic enrichment towards efficient speech representations
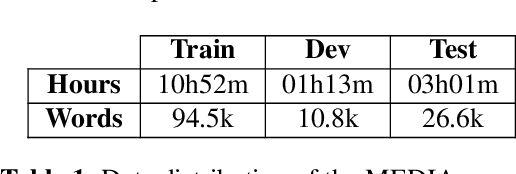
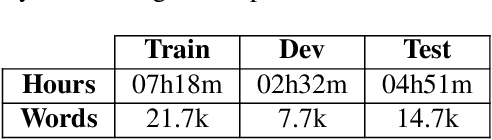
Jul 03, 2023Over the past few years, self-supervised learned speech representations have emerged as fruitful replacements for conventional surface representations when solving Spoken Language Understanding (SLU) tasks. Simultaneously, multilingual models trained on massive textual data were introduced to encode language agnostic semantics. Recently, the SAMU-XLSR approach introduced a way to make profit from such textual models to enrich multilingual speech representations with language agnostic semantics. By aiming for better semantic extraction on a challenging Spoken Language Understanding task and in consideration with computation costs, this study investigates a specific in-domain semantic enrichment of the SAMU-XLSR model by specializing it on a small amount of transcribed data from the downstream task. In addition, we show the benefits of the use of same-domain French and Italian benchmarks for low-resource language portability and explore cross-domain capacities of the enriched SAMU-XLSR.
On the Use of Semantically-Aligned Speech Representations for Spoken Language Understanding
Oct 11, 2022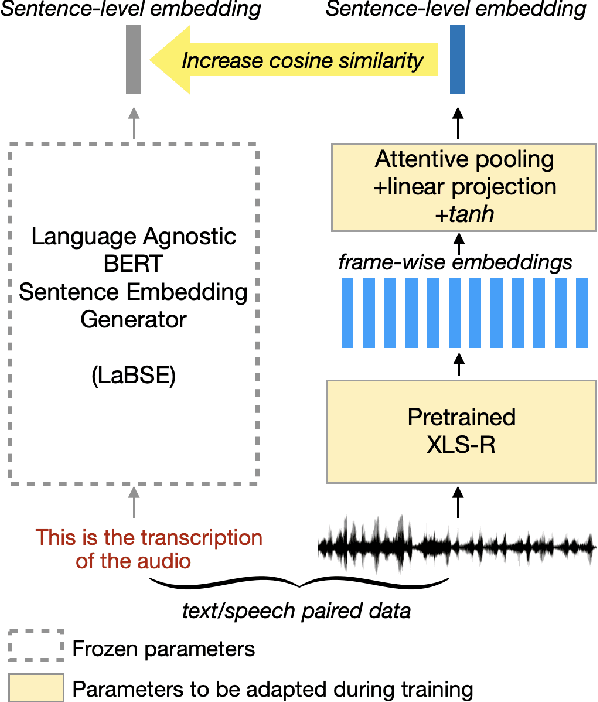
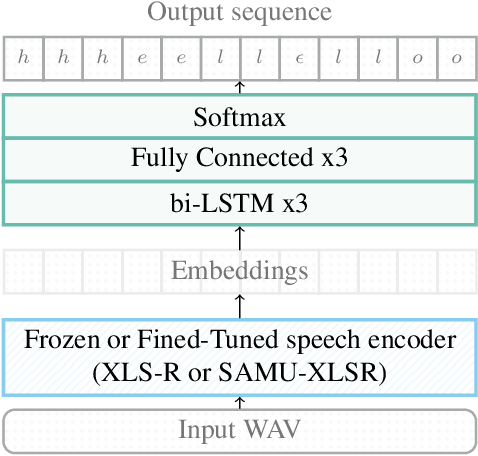
In this paper we examine the use of semantically-aligned speech representations for end-to-end spoken language understanding (SLU). We employ the recently-introduced SAMU-XLSR model, which is designed to generate a single embedding that captures the semantics at the utterance level, semantically aligned across different languages. This model combines the acoustic frame-level speech representation learning model (XLS-R) with the Language Agnostic BERT Sentence Embedding (LaBSE) model. We show that the use of the SAMU-XLSR model instead of the initial XLS-R model improves significantly the performance in the framework of end-to-end SLU. Finally, we present the benefits of using this model towards language portability in SLU.
Where are we in semantic concept extraction for Spoken Language Understanding?
Jun 24, 2021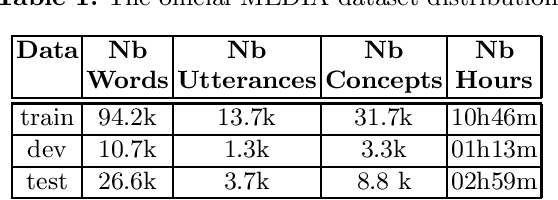


Spoken language understanding (SLU) topic has seen a lot of progress these last three years, with the emergence of end-to-end neural approaches. Spoken language understanding refers to natural language processing tasks related to semantic extraction from speech signal, like named entity recognition from speech or slot filling task in a context of human-machine dialogue. Classically, SLU tasks were processed through a cascade approach that consists in applying, firstly, an automatic speech recognition process, followed by a natural language processing module applied to the automatic transcriptions. These three last years, end-to-end neural approaches, based on deep neural networks, have been proposed in order to directly extract the semantics from speech signal, by using a single neural model. More recent works on self-supervised training with unlabeled data open new perspectives in term of performance for automatic speech recognition and natural language processing. In this paper, we present a brief overview of the recent advances on the French MEDIA benchmark dataset for SLU, with or without the use of additional data. We also present our last results that significantly outperform the current state-of-the-art with a Concept Error Rate (CER) of 11.2%, instead of 13.6% for the last state-of-the-art system presented this year.