 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end named entity extraction from speech
Paper and Code
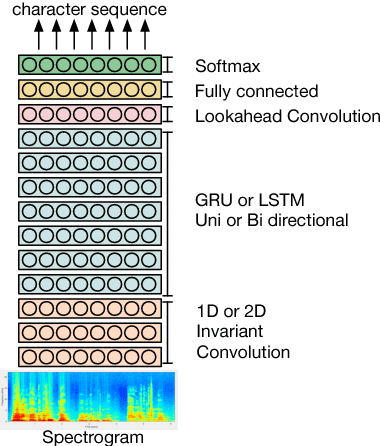
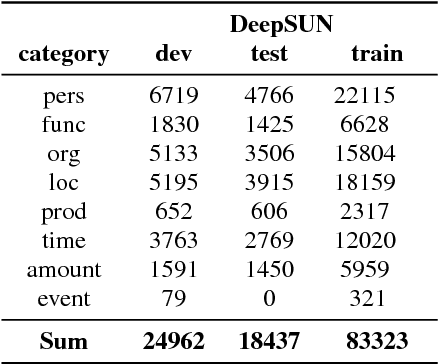

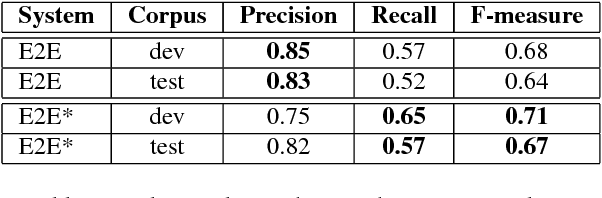
Named entity recognition (NER) is among SLU tasks that usually extract semantic information from textual documents. Until now, NER from speech is made through a pipeline process that consists in processing first an automatic speech recognition (ASR) on the audio and then processing a NER on the ASR outputs. Such approach has some disadvantages (error propagation, metric to tune ASR systems sub-optimal in regards to the final task, reduced space search at the ASR output level...) and it is known that more integrated approaches outperform sequential ones, when they can be applied. In this paper, we present a first study of end-to-end approach that directly extracts named entities from speech, though a unique neural architecture. On a such way, a joint optimization is able for both ASR and NER. Experiments are carried on French data easily accessible, composed of data distributed in several evaluation campaign. Experimental results show that this end-to-end approach provides better results (F-measure=0.69 on test data) than a classical pipeline approach to detect named entity categories (F-measure=0.65).