Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLIG-CRIStAL System for the WMT17 Automatic Post-Editing Task
Paper and Code
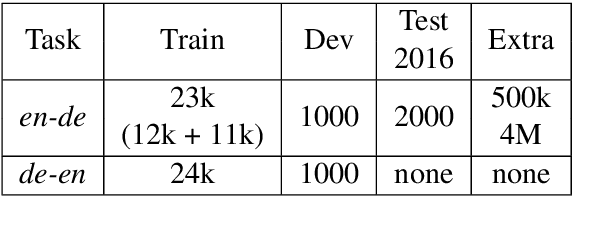

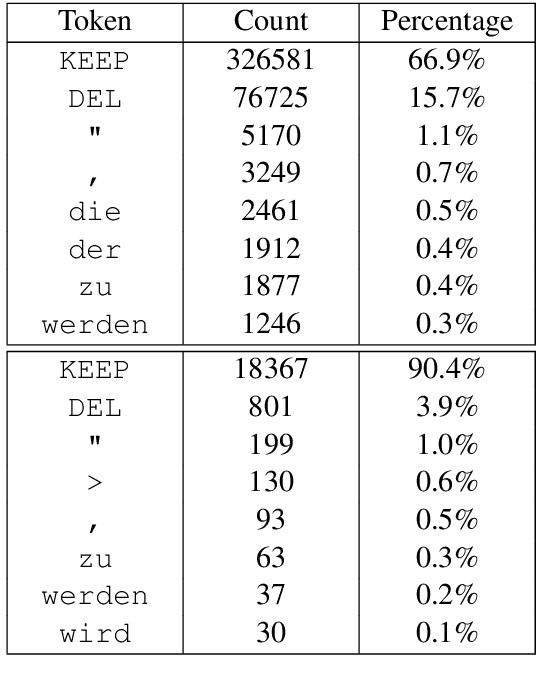

This paper presents the LIG-CRIStAL submission to the shared Automatic Post- Editing task of WMT 2017. We propose two neural post-editing models: a monosource model with a task-specific attention mechanism, which performs particularly well in a low-resource scenario; and a chained architecture which makes use of the source sentence to provide extra context. This latter architecture manages to slightly improve our results when more training data is available. We present and discuss our results on two datasets (en-de and de-en) that are made available for the task.
* keywords: neural post-edition, attention models
View paper on