 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeypoint based Sign Language Translation without Glosses
Apr 22, 2022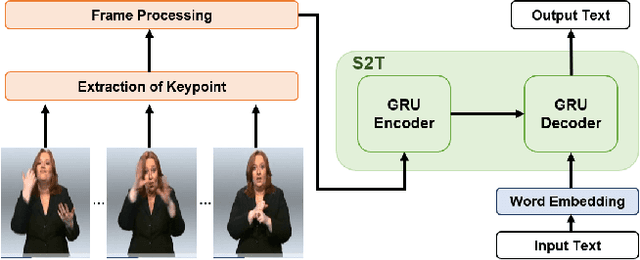
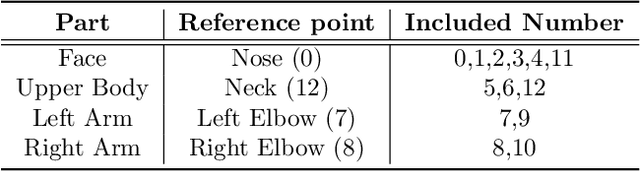
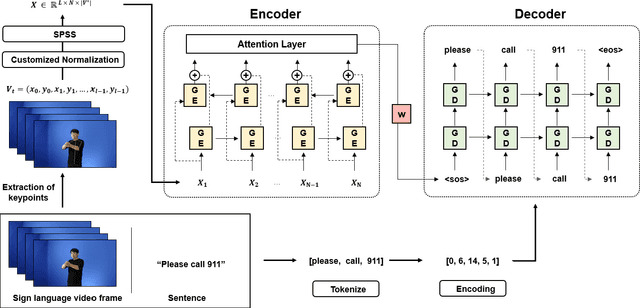
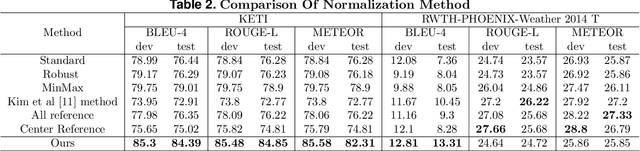
Sign Language Translation (SLT) is a task that has not been studied relatively much compared to the study of Sign Language Recognition (SLR). However, the SLR is a study that recognizes the unique grammar of sign language, which is different from the spoken language and has a problem that non-disabled people cannot easily interpret. So, we're going to solve the problem of translating directly spoken language in sign language video. To this end, we propose a new keypoint normalization method for performing translation based on the skeleton point of the signer and robustly normalizing these points in sign language translation. It contributed to performance improvement by a customized normalization method depending on the body parts. In addition, we propose a stochastic frame selection method that enables frame augmentation and sampling at the same time. Finally, it is translated into the spoken language through an Attention-based translation model. Our method can be applied to various datasets in a way that can be applied to datasets without glosses. In addition, quantitative experimental evaluation proved the excellence of our method.
Efficient Inference for Multilingual Neural Machine Translation
Sep 14, 2021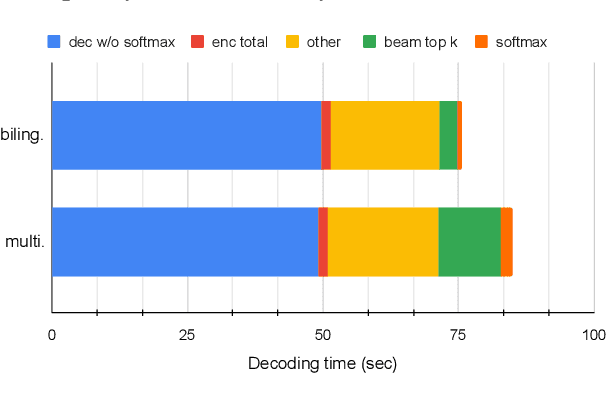
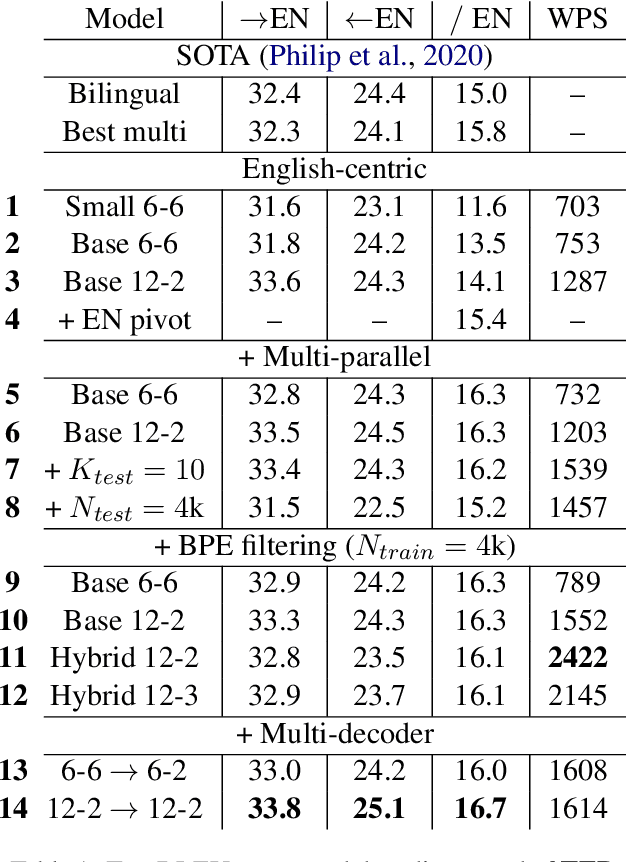
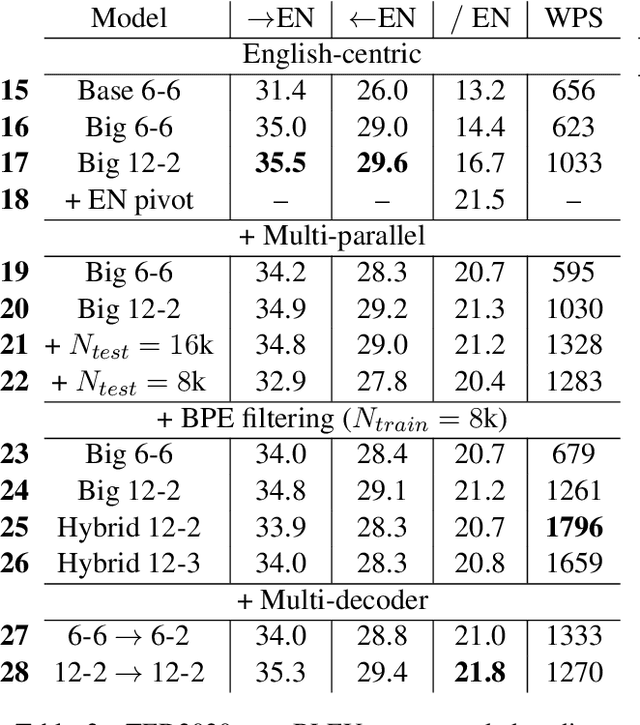
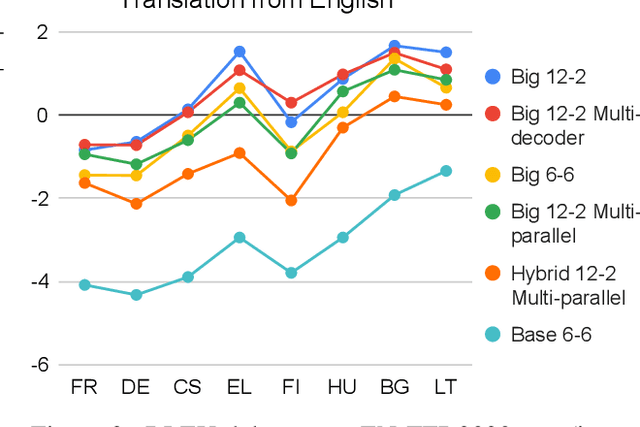
Multilingual NMT has become an attractive solution for MT deployment in production. But to match bilingual quality, it comes at the cost of larger and slower models. In this work, we consider several ways to make multilingual NMT faster at inference without degrading its quality. We experiment with several "light decoder" architectures in two 20-language multi-parallel settings: small-scale on TED Talks and large-scale on ParaCrawl. Our experiments demonstrate that combining a shallow decoder with vocabulary filtering leads to more than twice faster inference with no loss in translation quality. We validate our findings with BLEU and chrF (on 380 language pairs), robustness evaluation and human evaluation.