 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Learning in Multilingual NMT via Language-Specific Embeddings
Paper and Code
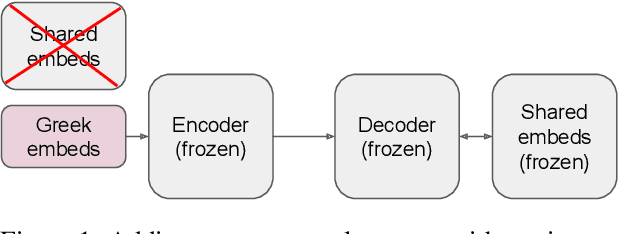
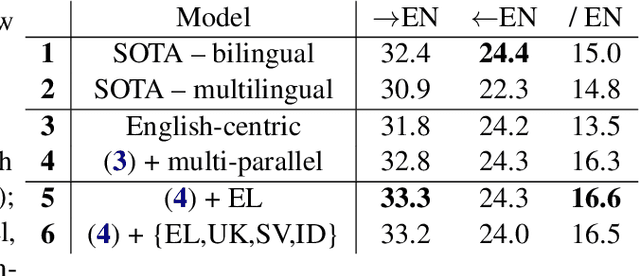
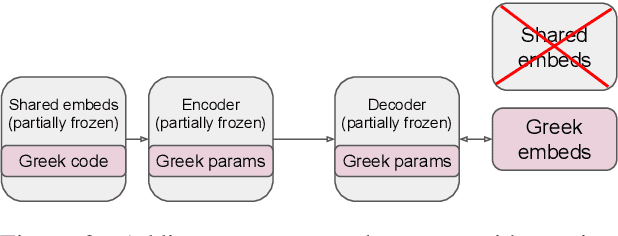
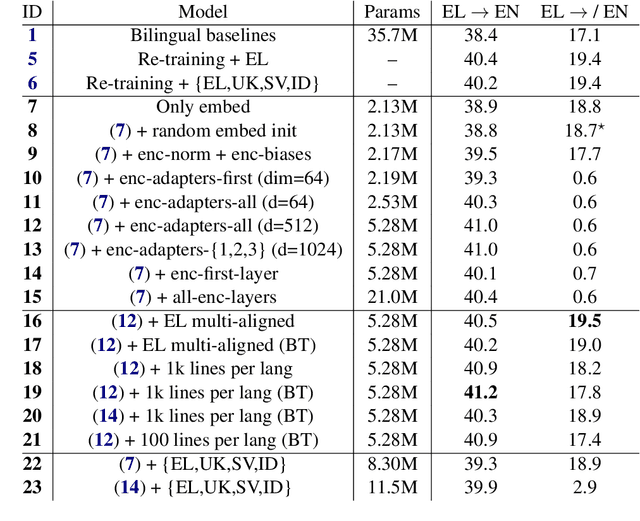
This paper proposes a technique for adding a new source or target language to an existing multilingual NMT model without re-training it on the initial set of languages. It consists in replacing the shared vocabulary with a small language-specific vocabulary and fine-tuning the new embeddings on the new language's parallel data. Some additional language-specific components may be trained to improve performance (e.g., Transformer layers or adapter modules). Because the parameters of the original model are not modified, its performance on the initial languages does not degrade. We show on two sets of experiments (small-scale on TED Talks, and large-scale on ParaCrawl) that this approach performs as well or better as the more costly alternatives; and that it has excellent zero-shot performance: training on English-centric data is enough to translate between the new language and any of the initial languages.