 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond surface form: A pipeline for semantic analysis in Alzheimer's Disease detection from spontaneous speech
Dec 15, 2025Alzheimer's Disease (AD) is a progressive neurodegenerative condition that adversely affects cognitive abilities. Language-related changes can be automatically identified through the analysis of outputs from linguistic assessment tasks, such as picture description. Language models show promise as a basis for screening tools for AD, but their limited interpretability poses a challenge in distinguishing true linguistic markers of cognitive decline from surface-level textual patterns. To address this issue, we examine how surface form variation affects classification performance, with the goal of assessing the ability of language models to represent underlying semantic indicators. We introduce a novel approach where texts surface forms are transformed by altering syntax and vocabulary while preserving semantic content. The transformations significantly modify the structure and lexical content, as indicated by low BLEU and chrF scores, yet retain the underlying semantics, as reflected in high semantic similarity scores, isolating the effect of semantic information, and finding models perform similarly to if they were using the original text, with only small deviations in macro-F1. We also investigate whether language from picture descriptions retains enough detail to reconstruct the original image using generative models. We found that image-based transformations add substantial noise reducing classification accuracy. Our methodology provides a novel way of looking at what features influence model predictions, and allows the removal of possible spurious correlations. We find that just using semantic information, language model based classifiers can still detect AD. This work shows that difficult to detect semantic impairment can be identified, addressing an overlooked feature of linguistic deterioration, and opening new pathways for early detection systems.
Limitations of Religious Data and the Importance of the Target Domain: Towards Machine Translation for Guinea-Bissau Creole
Apr 03, 2025We introduce a new dataset for machine translation of Guinea-Bissau Creole (Kiriol), comprising around 40 thousand parallel sentences to English and Portuguese. This dataset is made up of predominantly religious data (from the Bible and texts from the Jehovah's Witnesses), but also a small amount of general domain data (from a dictionary). This mirrors the typical resource availability of many low resource languages. We train a number of transformer-based models to investigate how to improve domain transfer from religious data to a more general domain. We find that adding even 300 sentences from the target domain when training substantially improves the translation performance, highlighting the importance and need for data collection for low-resource languages, even on a small-scale. We additionally find that Portuguese-to-Kiriol translation models perform better on average than other source and target language pairs, and investigate how this relates to the morphological complexity of the languages involved and the degree of lexical overlap between creoles and lexifiers. Overall, we hope our work will stimulate research into Kiriol and into how machine translation might better support creole languages in general.
Sign of the Times: Evaluating the use of Large Language Models for Idiomaticity Detection
May 15, 2024



Despite the recent ubiquity of large language models and their high zero-shot prompted performance across a wide range of tasks, it is still not known how well they perform on tasks which require processing of potentially idiomatic language. In particular, how well do such models perform in comparison to encoder-only models fine-tuned specifically for idiomaticity tasks? In this work, we attempt to answer this question by looking at the performance of a range of LLMs (both local and software-as-a-service models) on three idiomaticity datasets: SemEval 2022 Task 2a, FLUTE, and MAGPIE. Overall, we find that whilst these models do give competitive performance, they do not match the results of fine-tuned task-specific models, even at the largest scales (e.g. for GPT-4). Nevertheless, we do see consistent performance improvements across model scale. Additionally, we investigate prompting approaches to improve performance, and discuss the practicalities of using LLMs for these tasks.
Word Boundary Information Isn't Useful for Encoder Language Models
Jan 15, 2024



All existing transformer-based approaches to NLP using subword tokenisation algorithms encode whitespace (word boundary information) through the use of special space symbols (such as \#\# or \_) forming part of tokens. These symbols have been shown to a) lead to reduced morphological validity of tokenisations, and b) give substantial vocabulary redundancy. As such, removing these symbols has been shown to have a beneficial effect on the processing of morphologically complex words for transformer encoders in the pretrain-finetune paradigm. In this work, we explore whether word boundary information is at all useful to such models. In particular, we train transformer encoders across four different training scales, and investigate several alternative approaches to including word boundary information, evaluating on a range of tasks across different domains and problem set-ups: GLUE (for sentence-level classification), NER (for token-level classification), and two classification datasets involving complex words (Superbizarre and FLOTA). Overall, through an extensive experimental setup that includes the pre-training of 29 models, we find no substantial improvements from our alternative approaches, suggesting that modifying tokenisers to remove word boundary information isn't leading to a loss of useful information.
Sheffield's Submission to the AmericasNLP Shared Task on Machine Translation into Indigenous Languages
Jun 16, 2023



In this paper we describe the University of Sheffield's submission to the AmericasNLP 2023 Shared Task on Machine Translation into Indigenous Languages which comprises the translation from Spanish to eleven indigenous languages. Our approach consists of extending, training, and ensembling different variations of NLLB-200. We use data provided by the organizers and data from various other sources such as constitutions, handbooks, news articles, and backtranslations generated from monolingual data. On the dev set, our best submission outperforms the baseline by 11% average chrF across all languages, with substantial improvements particularly for Aymara, Guarani and Quechua. On the test set, we achieve the highest average chrF of all the submissions, we rank first in four of the eleven languages, and at least one of our submissions ranks in the top 3 for all languages.
NAVER LABS Europe's Multilingual Speech Translation Systems for the IWSLT 2023 Low-Resource Track
Jun 13, 2023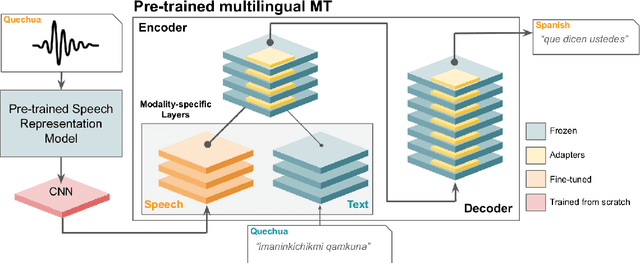
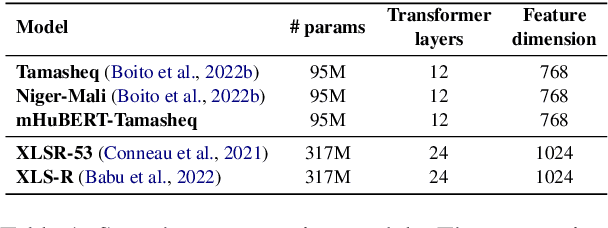
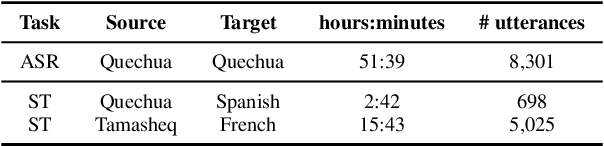
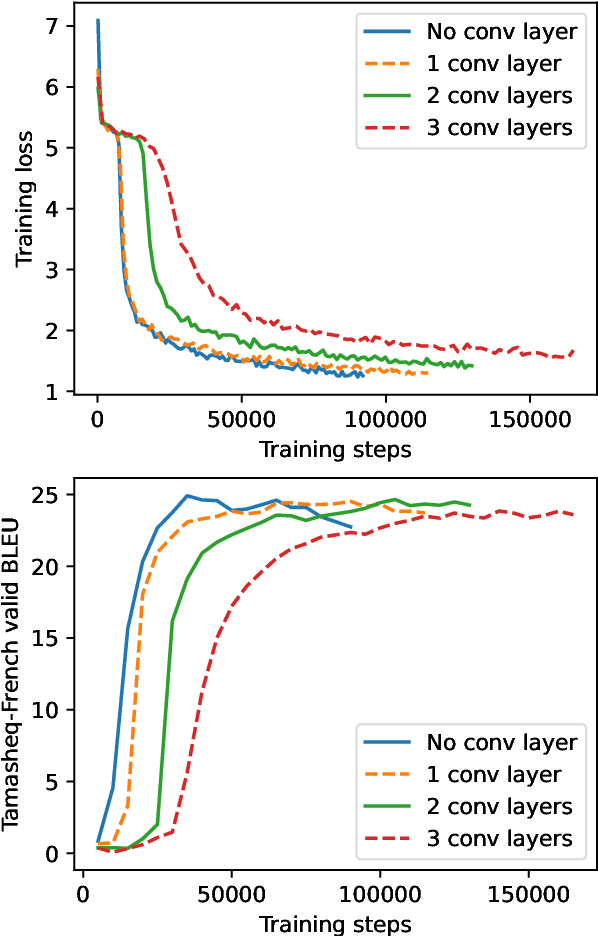
This paper presents NAVER LABS Europe's systems for Tamasheq-French and Quechua-Spanish speech translation in the IWSLT 2023 Low-Resource track. Our work attempts to maximize translation quality in low-resource settings using multilingual parameter-efficient solutions that leverage strong pre-trained models. Our primary submission for Tamasheq outperforms the previous state of the art by 7.5 BLEU points on the IWSLT 2022 test set, and achieves 23.6 BLEU on this year's test set, outperforming the second best participant by 7.7 points. For Quechua, we also rank first and achieve 17.7 BLEU, despite having only two hours of translation data. Finally, we show that our proposed multilingual architecture is also competitive for high-resource languages, outperforming the best unconstrained submission to the IWSLT 2021 Multilingual track, despite using much less training data and compute.
Use of Transformer-Based Models for Word-Level Transliteration of the Book of the Dean of Lismore
May 31, 2022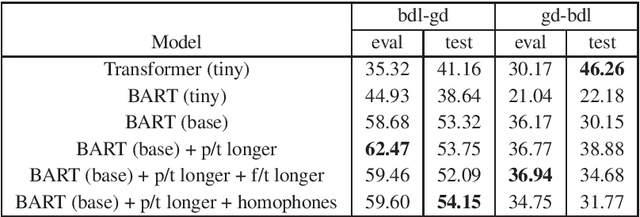
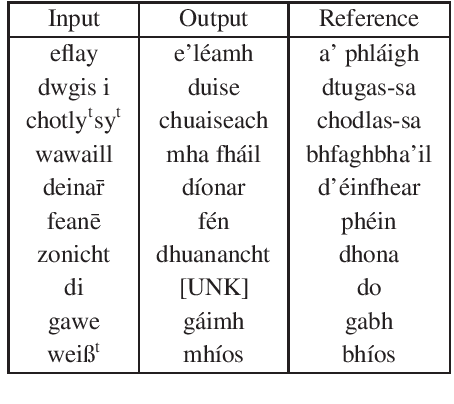

The Book of the Dean of Lismore (BDL) is a 16th-century Scottish Gaelic manuscript written in a non-standard orthography. In this work, we outline the problem of transliterating the text of the BDL into a standardised orthography, and perform exploratory experiments using Transformer-based models for this task. In particular, we focus on the task of word-level transliteration, and achieve a character-level BLEU score of 54.15 with our best model, a BART architecture pre-trained on the text of Scottish Gaelic Wikipedia and then fine-tuned on around 2,000 word-level parallel examples. Our initial experiments give promising results, but we highlight the shortcomings of our model, and discuss directions for future work.
Sample Efficient Approaches for Idiomaticity Detection
May 23, 2022
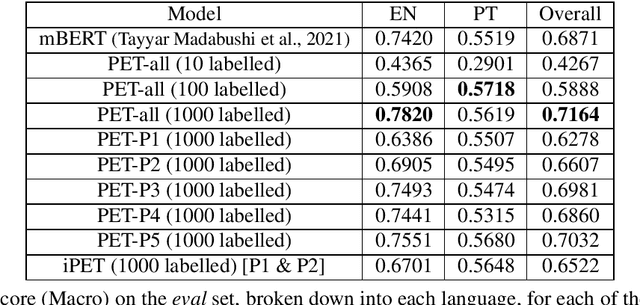
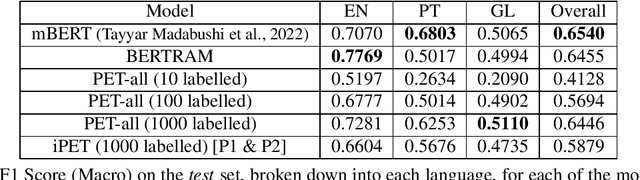

Deep neural models, in particular Transformer-based pre-trained language models, require a significant amount of data to train. This need for data tends to lead to problems when dealing with idiomatic multiword expressions (MWEs), which are inherently less frequent in natural text. As such, this work explores sample efficient methods of idiomaticity detection. In particular we study the impact of Pattern Exploit Training (PET), a few-shot method of classification, and BERTRAM, an efficient method of creating contextual embeddings, on the task of idiomaticity detection. In addition, to further explore generalisability, we focus on the identification of MWEs not present in the training data. Our experiments show that while these methods improve performance on English, they are much less effective on Portuguese and Galician, leading to an overall performance about on par with vanilla mBERT. Regardless, we believe sample efficient methods for both identifying and representing potentially idiomatic MWEs are very encouraging and hold significant potential for future exploration.
SemEval-2022 Task 2: Multilingual Idiomaticity Detection and Sentence Embedding
Apr 21, 2022
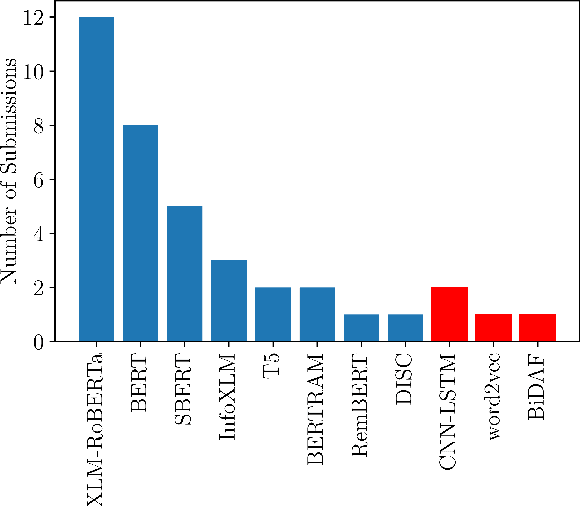

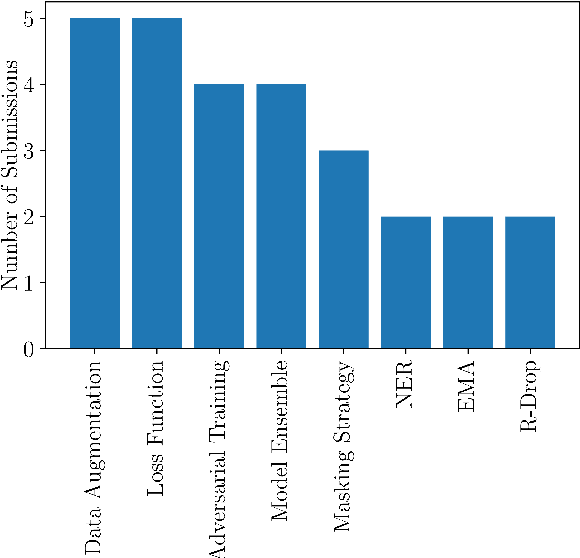
This paper presents the shared task on Multilingual Idiomaticity Detection and Sentence Embedding, which consists of two subtasks: (a) a binary classification one aimed at identifying whether a sentence contains an idiomatic expression, and (b) a task based on semantic text similarity which requires the model to adequately represent potentially idiomatic expressions in context. Each subtask includes different settings regarding the amount of training data. Besides the task description, this paper introduces the datasets in English, Portuguese, and Galician and their annotation procedure, the evaluation metrics, and a summary of the participant systems and their results. The task had close to 100 registered participants organised into twenty five teams making over 650 and 150 submissions in the practice and evaluation phases respectively.
Improving Tokenisation by Alternative Treatment of Spaces
Apr 08, 2022


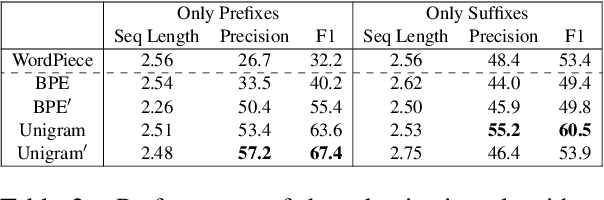
Tokenisation is the first step in almost all NLP tasks, and state-of-the-art transformer-based language models all use subword tokenisation algorithms to process input text. Existing algorithms have problems, often producing tokenisations of limited linguistic validity, and representing equivalent strings differently depending on their position within a word. We hypothesise that these problems hinder the ability of transformer-based models to handle complex words, and suggest that these problems are a result of allowing tokens to include spaces. We thus experiment with an alternative tokenisation approach where spaces are always treated as individual tokens. Specifically, we apply this modification to the BPE and Unigram algorithms. We find that our modified algorithms lead to improved performance on downstream NLP tasks that involve handling complex words, whilst having no detrimental effect on performance in general natural language understanding tasks. Intrinsically, we find our modified algorithms give more morphologically correct tokenisations, in particular when handling prefixes. Given the results of our experiments, we advocate for always treating spaces as individual tokens as an improved tokenisation method.