 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning Dynamics and the Limits of Monitoring Modality Reliance in Vision-Language Models
Apr 16, 2026Recent advances in vision language models (VLMs) offer reasoning capabilities, yet how these unfold and integrate visual and textual information remains unclear. We analyze reasoning dynamics in 18 VLMs covering instruction-tuned and reasoning-trained models from two different model families. We track confidence over Chain-of-Thought (CoT), measure the corrective effect of reasoning, and evaluate the contribution of intermediate reasoning steps. We find that models are prone to answer inertia, in which early commitments to a prediction are reinforced, rather than revised during reasoning steps. While reasoning-trained models show stronger corrective behavior, their gains depend on modality conditions, from text-dominant to vision-only settings. Using controlled interventions with misleading textual cues, we show that models are consistently influenced by these cues even when visual evidence is sufficient, and assess whether this influence is recoverable from CoT. Although this influence can appear in the CoT, its detectability varies across models and depends on what is being monitored. Reasoning-trained models are more likely to explicitly refer to the cues, but their longer and fluent CoTs can still appear visually grounded while actually following textual cues, obscuring modality reliance. In contrast, instruction-tuned models refer to the cues less explicitly, but their shorter traces reveal inconsistencies with the visual input. Taken together, these findings indicate that CoT provides only a partial view of how different modalities drive VLM decisions, with important implications for the transparency and safety of multimodal systems.
Beyond Binary Classification: Detecting Fine-Grained Sexism in Social Media Videos
Feb 17, 2026Online sexism appears in various forms, which makes its detection challenging. Although automated tools can enhance the identification of sexist content, they are often restricted to binary classification. Consequently, more subtle manifestations of sexism may remain undetected due to the lack of fine-grained, context-sensitive labels. To address this issue, we make the following contributions: (1) we present FineMuSe, a new multimodal sexism detection dataset in Spanish that includes both binary and fine-grained annotations; (2) we introduce a comprehensive hierarchical taxonomy that encompasses forms of sexism, non-sexism, and rhetorical devices of irony and humor; and (3) we evaluate a wide range of LLMs for both binary and fine-grained sexism detection. Our findings indicate that multimodal LLMs perform competitively with human annotators in identifying nuanced forms of sexism; however, they struggle to capture co-occurring sexist types when these are conveyed through visual cues.
Movie Facts and Fibs (MF$^2$): A Benchmark for Long Movie Understanding
Jun 06, 2025Despite recent progress in vision-language models (VLMs), holistic understanding of long-form video content remains a significant challenge, partly due to limitations in current benchmarks. Many focus on peripheral, ``needle-in-a-haystack'' details, encouraging context-insensitive retrieval over deep comprehension. Others rely on large-scale, semi-automatically generated questions (often produced by language models themselves) that are easier for models to answer but fail to reflect genuine understanding. In this paper, we introduce MF$^2$, a new benchmark for evaluating whether models can comprehend, consolidate, and recall key narrative information from full-length movies (50-170 minutes long). MF$^2$ includes over 50 full-length, open-licensed movies, each paired with manually constructed sets of claim pairs -- one true (fact) and one plausible but false (fib), totalling over 850 pairs. These claims target core narrative elements such as character motivations and emotions, causal chains, and event order, and refer to memorable moments that humans can recall without rewatching the movie. Instead of multiple-choice formats, we adopt a binary claim evaluation protocol: for each pair, models must correctly identify both the true and false claims. This reduces biases like answer ordering and enables a more precise assessment of reasoning. Our experiments demonstrate that both open-weight and closed state-of-the-art models fall well short of human performance, underscoring the relative ease of the task for humans and their superior ability to retain and reason over critical narrative information -- an ability current VLMs lack.
MuSeD: A Multimodal Spanish Dataset for Sexism Detection in Social Media Videos
Apr 15, 2025Sexism is generally defined as prejudice and discrimination based on sex or gender, affecting every sector of society, from social institutions to relationships and individual behavior. Social media platforms amplify the impact of sexism by conveying discriminatory content not only through text but also across multiple modalities, highlighting the critical need for a multimodal approach to the analysis of sexism online. With the rise of social media platforms where users share short videos, sexism is increasingly spreading through video content. Automatically detecting sexism in videos is a challenging task, as it requires analyzing the combination of verbal, audio, and visual elements to identify sexist content. In this study, (1) we introduce MuSeD, a new Multimodal Spanish dataset for Sexism Detection consisting of $\approx$ 11 hours of videos extracted from TikTok and BitChute; (2) we propose an innovative annotation framework for analyzing the contribution of textual and multimodal labels in the classification of sexist and non-sexist content; and (3) we evaluate a range of large language models (LLMs) and multimodal LLMs on the task of sexism detection. We find that visual information plays a key role in labeling sexist content for both humans and models. Models effectively detect explicit sexism; however, they struggle with implicit cases, such as stereotypes, instances where annotators also show low agreement. This highlights the inherent difficulty of the task, as identifying implicit sexism depends on the social and cultural context.
ImageChain: Advancing Sequential Image-to-Text Reasoning in Multimodal Large Language Models
Feb 26, 2025Reasoning over sequences of images remains a challenge for multimodal large language models (MLLMs). While recent models incorporate multi-image data during pre-training, they still struggle to recognize sequential structures, often treating images independently. This work introduces ImageChain, a framework that enhances MLLMs with sequential reasoning capabilities over image data by modeling visual sequences as a multi-turn conversation. In ImageChain, images are interleaved with corresponding textual descriptions to form a controlled dialogue that explicitly captures temporal dependencies and narrative progression. Our method optimizes for the task of next-scene description, where the model generates a context-aware description of an upcoming scene based on preceding visual and textual cues. We demonstrate that our approach improves performance on the next-scene description task -- achieving an average improvement from 3.7% to 19% in SimRate, a metric that quantifies semantic similarity to human-annotated ground truths. Moreover, ImageChain achieves robust zero-shot out-of-domain performance in applications ranging from comics to robotics. Extensive experiments validate that instruction-tuning in a multimodal, multi-turn conversation design is key to bridging the gap between static image understanding and temporally-aware reasoning.
Improving Multimodal Classification of Social Media Posts by Leveraging Image-Text Auxiliary tasks
Sep 14, 2023Effectively leveraging multimodal information from social media posts is essential to various downstream tasks such as sentiment analysis, sarcasm detection and hate speech classification. However, combining text and image information is challenging because of the idiosyncratic cross-modal semantics with hidden or complementary information present in matching image-text pairs. In this work, we aim to directly model this by proposing the use of two auxiliary losses jointly with the main task when fine-tuning any pre-trained multimodal model. Image-Text Contrastive (ITC) brings image-text representations of a post closer together and separates them from different posts, capturing underlying dependencies. Image-Text Matching (ITM) facilitates the understanding of semantic correspondence between images and text by penalizing unrelated pairs. We combine these objectives with five multimodal models, demonstrating consistent improvements across four popular social media datasets. Furthermore, through detailed analysis, we shed light on the specific scenarios and cases where each auxiliary task proves to be most effective.
A Multimodal Analysis of Influencer Content on Twitter
Sep 06, 2023



Influencer marketing involves a wide range of strategies in which brands collaborate with popular content creators (i.e., influencers) to leverage their reach, trust, and impact on their audience to promote and endorse products or services. Because followers of influencers are more likely to buy a product after receiving an authentic product endorsement rather than an explicit direct product promotion, the line between personal opinions and commercial content promotion is frequently blurred. This makes automatic detection of regulatory compliance breaches related to influencer advertising (e.g., misleading advertising or hidden sponsorships) particularly difficult. In this work, we (1) introduce a new Twitter (now X) dataset consisting of 15,998 influencer posts mapped into commercial and non-commercial categories for assisting in the automatic detection of commercial influencer content; (2) experiment with an extensive set of predictive models that combine text and visual information showing that our proposed cross-attention approach outperforms state-of-the-art multimodal models; and (3) conduct a thorough analysis of strengths and limitations of our models. We show that multimodal modeling is useful for identifying commercial posts, reducing the amount of false positives, and capturing relevant context that aids in the discovery of undisclosed commercial posts.
Sheffield's Submission to the AmericasNLP Shared Task on Machine Translation into Indigenous Languages
Jun 16, 2023



In this paper we describe the University of Sheffield's submission to the AmericasNLP 2023 Shared Task on Machine Translation into Indigenous Languages which comprises the translation from Spanish to eleven indigenous languages. Our approach consists of extending, training, and ensembling different variations of NLLB-200. We use data provided by the organizers and data from various other sources such as constitutions, handbooks, news articles, and backtranslations generated from monolingual data. On the dev set, our best submission outperforms the baseline by 11% average chrF across all languages, with substantial improvements particularly for Aymara, Guarani and Quechua. On the test set, we achieve the highest average chrF of all the submissions, we rank first in four of the eleven languages, and at least one of our submissions ranks in the top 3 for all languages.
Combining Humor and Sarcasm for Improving Political Parody Detection
May 06, 2022
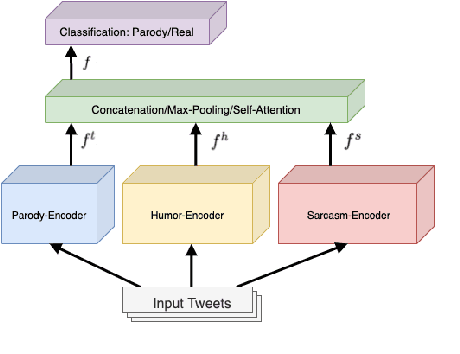
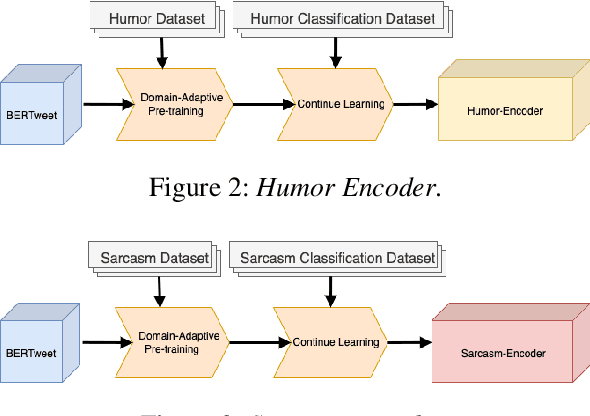

Parody is a figurative device used for mimicking entities for comedic or critical purposes. Parody is intentionally humorous and often involves sarcasm. This paper explores jointly modelling these figurative tropes with the goal of improving performance of political parody detection in tweets. To this end, we present a multi-encoder model that combines three parallel encoders to enrich parody-specific representations with humor and sarcasm information. Experiments on a publicly available data set of political parody tweets demonstrate that our approach outperforms previous state-of-the-art methods.
Point-of-Interest Type Prediction using Text and Images
Sep 01, 2021

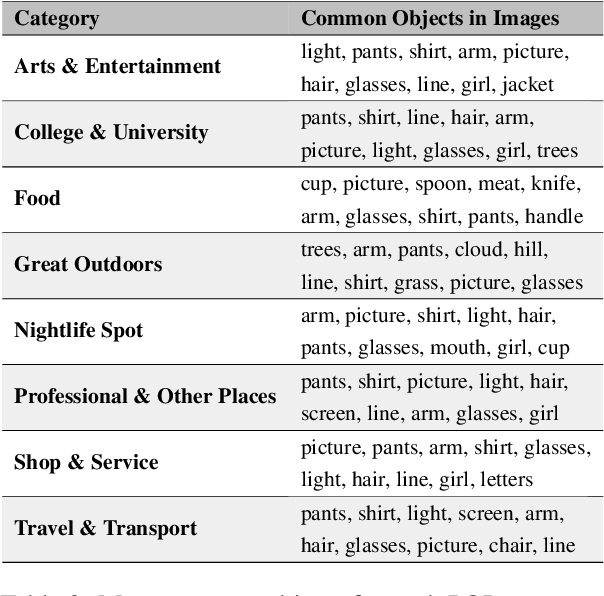
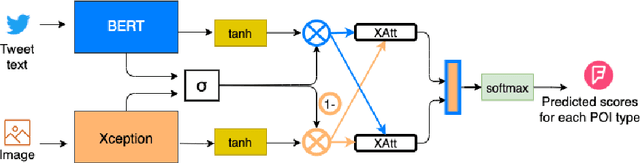
Point-of-interest (POI) type prediction is the task of inferring the type of a place from where a social media post was shared. Inferring a POI's type is useful for studies in computational social science including sociolinguistics, geosemiotics, and cultural geography, and has applications in geosocial networking technologies such as recommendation and visualization systems. Prior efforts in POI type prediction focus solely on text, without taking visual information into account. However in reality, the variety of modalities, as well as their semiotic relationships with one another, shape communication and interactions in social media. This paper presents a study on POI type prediction using multimodal information from text and images available at posting time. For that purpose, we enrich a currently available data set for POI type prediction with the images that accompany the text messages. Our proposed method extracts relevant information from each modality to effectively capture interactions between text and image achieving a macro F1 of 47.21 across eight categories significantly outperforming the state-of-the-art method for POI type prediction based on text-only methods. Finally, we provide a detailed analysis to shed light on cross-modal interactions and the limitations of our best performing model.