 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuSeD: A Multimodal Spanish Dataset for Sexism Detection in Social Media Videos
Apr 15, 2025Sexism is generally defined as prejudice and discrimination based on sex or gender, affecting every sector of society, from social institutions to relationships and individual behavior. Social media platforms amplify the impact of sexism by conveying discriminatory content not only through text but also across multiple modalities, highlighting the critical need for a multimodal approach to the analysis of sexism online. With the rise of social media platforms where users share short videos, sexism is increasingly spreading through video content. Automatically detecting sexism in videos is a challenging task, as it requires analyzing the combination of verbal, audio, and visual elements to identify sexist content. In this study, (1) we introduce MuSeD, a new Multimodal Spanish dataset for Sexism Detection consisting of $\approx$ 11 hours of videos extracted from TikTok and BitChute; (2) we propose an innovative annotation framework for analyzing the contribution of textual and multimodal labels in the classification of sexist and non-sexist content; and (3) we evaluate a range of large language models (LLMs) and multimodal LLMs on the task of sexism detection. We find that visual information plays a key role in labeling sexist content for both humans and models. Models effectively detect explicit sexism; however, they struggle with implicit cases, such as stereotypes, instances where annotators also show low agreement. This highlights the inherent difficulty of the task, as identifying implicit sexism depends on the social and cultural context.
What distinguishes conspiracy from critical narratives? A computational analysis of oppositional discourse
Jul 15, 2024The current prevalence of conspiracy theories on the internet is a significant issue, tackled by many computational approaches. However, these approaches fail to recognize the relevance of distinguishing between texts which contain a conspiracy theory and texts which are simply critical and oppose mainstream narratives. Furthermore, little attention is usually paid to the role of inter-group conflict in oppositional narratives. We contribute by proposing a novel topic-agnostic annotation scheme that differentiates between conspiracies and critical texts, and that defines span-level categories of inter-group conflict. We also contribute with the multilingual XAI-DisInfodemics corpus (English and Spanish), which contains a high-quality annotation of Telegram messages related to COVID-19 (5,000 messages per language). We also demonstrate the feasibility of an NLP-based automatization by performing a range of experiments that yield strong baseline solutions. Finally, we perform an analysis which demonstrates that the promotion of intergroup conflict and the presence of violence and anger are key aspects to distinguish between the two types of oppositional narratives, i.e., conspiracy vs. critical.
InferES : A Natural Language Inference Corpus for Spanish Featuring Negation-Based Contrastive and Adversarial Examples
Oct 06, 2022
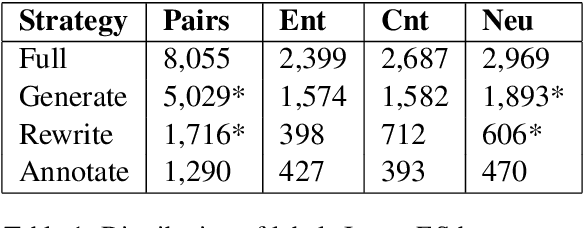
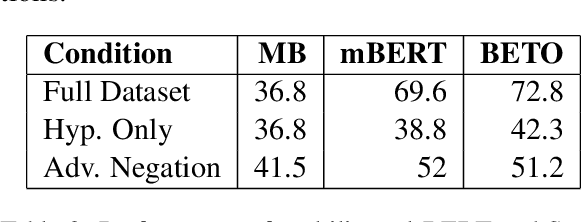

In this paper, we present InferES - an original corpus for Natural Language Inference (NLI) in European Spanish. We propose, implement, and analyze a variety of corpus-creating strategies utilizing expert linguists and crowd workers. The objectives behind InferES are to provide high-quality data, and, at the same time to facilitate the systematic evaluation of automated systems. Specifically, we focus on measuring and improving the performance of machine learning systems on negation-based adversarial examples and their ability to generalize across out-of-distribution topics. We train two transformer models on InferES (8,055 gold examples) in a variety of scenarios. Our best model obtains 72.8% accuracy, leaving a lot of room for improvement. The "hypothesis-only" baseline performs only 2%-5% higher than majority, indicating much fewer annotation artifacts than prior work. We find that models trained on InferES generalize very well across topics (both in- and out-of-distribution) and perform moderately well on negation-based adversarial examples.