 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInferES : A Natural Language Inference Corpus for Spanish Featuring Negation-Based Contrastive and Adversarial Examples
Paper and Code

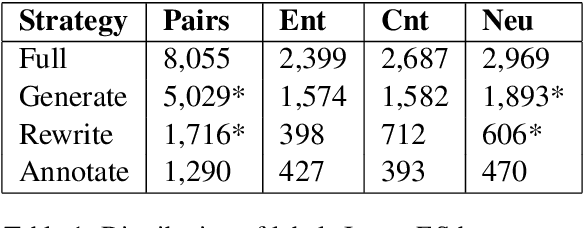
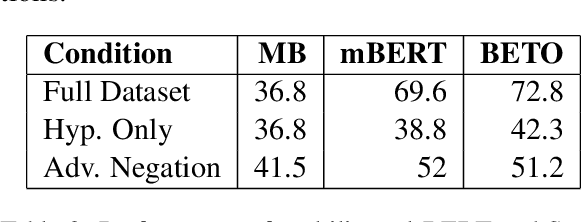

In this paper, we present InferES - an original corpus for Natural Language Inference (NLI) in European Spanish. We propose, implement, and analyze a variety of corpus-creating strategies utilizing expert linguists and crowd workers. The objectives behind InferES are to provide high-quality data, and, at the same time to facilitate the systematic evaluation of automated systems. Specifically, we focus on measuring and improving the performance of machine learning systems on negation-based adversarial examples and their ability to generalize across out-of-distribution topics. We train two transformer models on InferES (8,055 gold examples) in a variety of scenarios. Our best model obtains 72.8% accuracy, leaving a lot of room for improvement. The "hypothesis-only" baseline performs only 2%-5% higher than majority, indicating much fewer annotation artifacts than prior work. We find that models trained on InferES generalize very well across topics (both in- and out-of-distribution) and perform moderately well on negation-based adversarial examples.