 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Attention as Compact Kernel Regression
Jan 30, 2026Recent work has revealed a link between self-attention mechanisms in transformers and test-time kernel regression via the Nadaraya-Watson estimator, with standard softmax attention corresponding to a Gaussian kernel. However, a kernel-theoretic understanding of sparse attention mechanisms is currently missing. In this paper, we establish a formal correspondence between sparse attention and compact (bounded support) kernels. We show that normalized ReLU and sparsemax attention arise from Epanechnikov kernel regression under fixed and adaptive normalizations, respectively. More generally, we demonstrate that widely used kernels in nonparametric density estimation -- including Epanechnikov, biweight, and triweight -- correspond to $α$-entmax attention with $α= 1 + \frac{1}{n}$ for $n \in \mathbb{N}$, while the softmax/Gaussian relationship emerges in the limit $n \to \infty$. This unified perspective explains how sparsity naturally emerges from kernel design and provides principled alternatives to heuristic top-$k$ attention and other associative memory mechanisms. Experiments with a kernel-regression-based variant of transformers -- Memory Mosaics -- show that kernel-based sparse attention achieves competitive performance on language modeling, in-context learning, and length generalization tasks, offering a principled framework for designing attention mechanisms.
Movie Facts and Fibs (MF$^2$): A Benchmark for Long Movie Understanding
Jun 06, 2025Despite recent progress in vision-language models (VLMs), holistic understanding of long-form video content remains a significant challenge, partly due to limitations in current benchmarks. Many focus on peripheral, ``needle-in-a-haystack'' details, encouraging context-insensitive retrieval over deep comprehension. Others rely on large-scale, semi-automatically generated questions (often produced by language models themselves) that are easier for models to answer but fail to reflect genuine understanding. In this paper, we introduce MF$^2$, a new benchmark for evaluating whether models can comprehend, consolidate, and recall key narrative information from full-length movies (50-170 minutes long). MF$^2$ includes over 50 full-length, open-licensed movies, each paired with manually constructed sets of claim pairs -- one true (fact) and one plausible but false (fib), totalling over 850 pairs. These claims target core narrative elements such as character motivations and emotions, causal chains, and event order, and refer to memorable moments that humans can recall without rewatching the movie. Instead of multiple-choice formats, we adopt a binary claim evaluation protocol: for each pair, models must correctly identify both the true and false claims. This reduces biases like answer ordering and enables a more precise assessment of reasoning. Our experiments demonstrate that both open-weight and closed state-of-the-art models fall well short of human performance, underscoring the relative ease of the task for humans and their superior ability to retain and reason over critical narrative information -- an ability current VLMs lack.
$\infty$-Video: A Training-Free Approach to Long Video Understanding via Continuous-Time Memory Consolidation
Jan 31, 2025



Current video-language models struggle with long-video understanding due to limited context lengths and reliance on sparse frame subsampling, often leading to information loss. This paper introduces $\infty$-Video, which can process arbitrarily long videos through a continuous-time long-term memory (LTM) consolidation mechanism. Our framework augments video Q-formers by allowing them to process unbounded video contexts efficiently and without requiring additional training. Through continuous attention, our approach dynamically allocates higher granularity to the most relevant video segments, forming "sticky" memories that evolve over time. Experiments with Video-LLaMA and VideoChat2 demonstrate improved performance in video question-answering tasks, showcasing the potential of continuous-time LTM mechanisms to enable scalable and training-free comprehension of long videos.
Hopfield-Fenchel-Young Networks: A Unified Framework for Associative Memory Retrieval
Nov 13, 2024



Associative memory models, such as Hopfield networks and their modern variants, have garnered renewed interest due to advancements in memory capacity and connections with self-attention in transformers. In this work, we introduce a unified framework-Hopfield-Fenchel-Young networks-which generalizes these models to a broader family of energy functions. Our energies are formulated as the difference between two Fenchel-Young losses: one, parameterized by a generalized entropy, defines the Hopfield scoring mechanism, while the other applies a post-transformation to the Hopfield output. By utilizing Tsallis and norm entropies, we derive end-to-end differentiable update rules that enable sparse transformations, uncovering new connections between loss margins, sparsity, and exact retrieval of single memory patterns. We further extend this framework to structured Hopfield networks using the SparseMAP transformation, allowing the retrieval of pattern associations rather than a single pattern. Our framework unifies and extends traditional and modern Hopfield networks and provides an energy minimization perspective for widely used post-transformations like $\ell_2$-normalization and layer normalization-all through suitable choices of Fenchel-Young losses and by using convex analysis as a building block. Finally, we validate our Hopfield-Fenchel-Young networks on diverse memory recall tasks, including free and sequential recall. Experiments on simulated data, image retrieval, multiple instance learning, and text rationalization demonstrate the effectiveness of our approach.
Sparse and Structured Hopfield Networks
Feb 21, 2024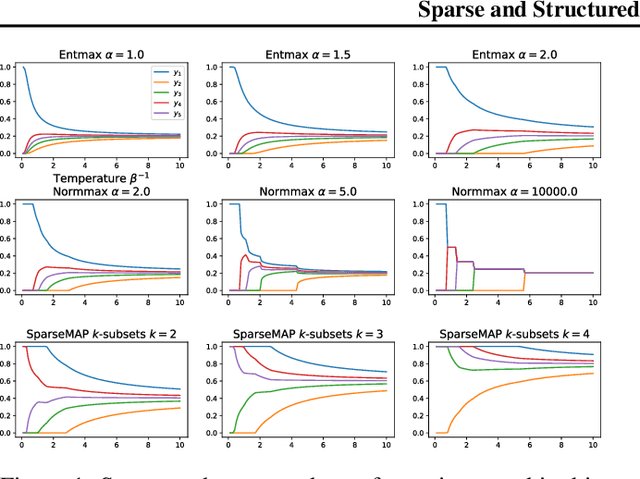
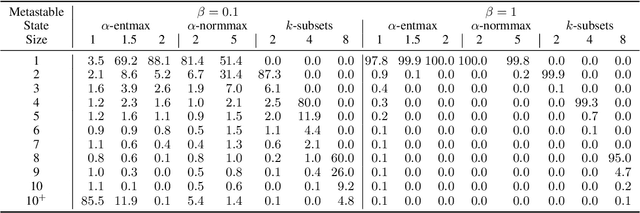
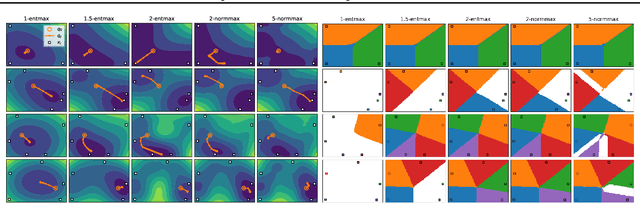
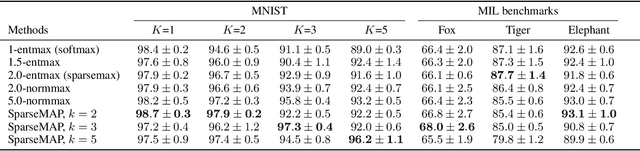
Modern Hopfield networks have enjoyed recent interest due to their connection to attention in transformers. Our paper provides a unified framework for sparse Hopfield networks by establishing a link with Fenchel-Young losses. The result is a new family of Hopfield-Fenchel-Young energies whose update rules are end-to-end differentiable sparse transformations. We reveal a connection between loss margins, sparsity, and exact memory retrieval. We further extend this framework to structured Hopfield networks via the SparseMAP transformation, which can retrieve pattern associations instead of a single pattern. Experiments on multiple instance learning and text rationalization demonstrate the usefulness of our approach.
Symplectic Momentum Neural Networks -- Using Discrete Variational Mechanics as a prior in Deep Learning
Jan 21, 2022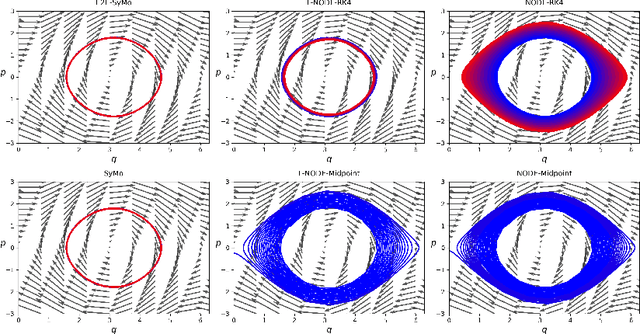
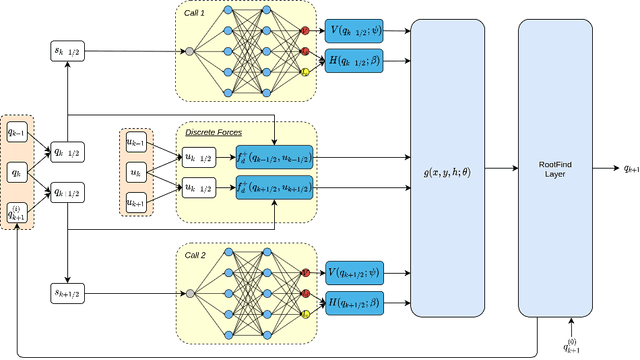
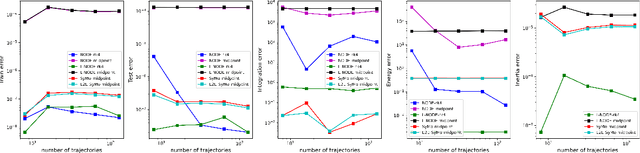
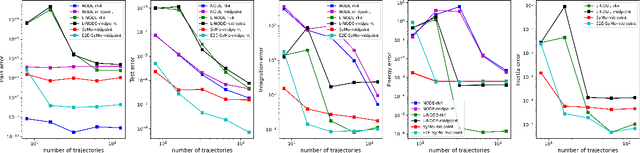
With deep learning being gaining attention from the research community for prediction and control of real physical systems, learning important representations is becoming now more than ever mandatory. It is of extremely importance that deep learning representations are coherent with physics. When learning from discrete data this can be guaranteed by including some sort of prior into the learning, however not all discretization priors preserve important structures from the physics. In this paper we introduce Symplectic Momentum Neural Networks (SyMo) as models from a discrete formulation of mechanics for non-separable mechanical systems. The combination of such formulation leads SyMos to be constrained towards preserving important geometric structures such as momentum and a symplectic form and learn from limited data. Furthermore, it allows to learn dynamics only from the poses as training data. We extend SyMos to include variational integrators within the learning framework by developing an implicit root-find layer which leads to End-to-End Symplectic Momentum Neural Networks (E2E-SyMo). Through experimental results, using the pendulum and cartpole we show that such combination not only allows these models tol earn from limited data but also provides the models with the capability of preserving the symplectic form and show better long-term behaviour.