 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond surface form: A pipeline for semantic analysis in Alzheimer's Disease detection from spontaneous speech
Dec 15, 2025Alzheimer's Disease (AD) is a progressive neurodegenerative condition that adversely affects cognitive abilities. Language-related changes can be automatically identified through the analysis of outputs from linguistic assessment tasks, such as picture description. Language models show promise as a basis for screening tools for AD, but their limited interpretability poses a challenge in distinguishing true linguistic markers of cognitive decline from surface-level textual patterns. To address this issue, we examine how surface form variation affects classification performance, with the goal of assessing the ability of language models to represent underlying semantic indicators. We introduce a novel approach where texts surface forms are transformed by altering syntax and vocabulary while preserving semantic content. The transformations significantly modify the structure and lexical content, as indicated by low BLEU and chrF scores, yet retain the underlying semantics, as reflected in high semantic similarity scores, isolating the effect of semantic information, and finding models perform similarly to if they were using the original text, with only small deviations in macro-F1. We also investigate whether language from picture descriptions retains enough detail to reconstruct the original image using generative models. We found that image-based transformations add substantial noise reducing classification accuracy. Our methodology provides a novel way of looking at what features influence model predictions, and allows the removal of possible spurious correlations. We find that just using semantic information, language model based classifiers can still detect AD. This work shows that difficult to detect semantic impairment can be identified, addressing an overlooked feature of linguistic deterioration, and opening new pathways for early detection systems.
SemEval-2025 Task 1: AdMIRe -- Advancing Multimodal Idiomaticity Representation
Mar 19, 2025Idiomatic expressions present a unique challenge in NLP, as their meanings are often not directly inferable from their constituent words. Despite recent advancements in Large Language Models (LLMs), idiomaticity remains a significant obstacle to robust semantic representation. We present datasets and tasks for SemEval-2025 Task 1: AdMiRe (Advancing Multimodal Idiomaticity Representation), which challenges the community to assess and improve models' ability to interpret idiomatic expressions in multimodal contexts and in multiple languages. Participants competed in two subtasks: ranking images based on their alignment with idiomatic or literal meanings, and predicting the next image in a sequence. The most effective methods achieved human-level performance by leveraging pretrained LLMs and vision-language models in mixture-of-experts settings, with multiple queries used to smooth over the weaknesses in these models' representations of idiomaticity.
Sign of the Times: Evaluating the use of Large Language Models for Idiomaticity Detection
May 15, 2024



Despite the recent ubiquity of large language models and their high zero-shot prompted performance across a wide range of tasks, it is still not known how well they perform on tasks which require processing of potentially idiomatic language. In particular, how well do such models perform in comparison to encoder-only models fine-tuned specifically for idiomaticity tasks? In this work, we attempt to answer this question by looking at the performance of a range of LLMs (both local and software-as-a-service models) on three idiomaticity datasets: SemEval 2022 Task 2a, FLUTE, and MAGPIE. Overall, we find that whilst these models do give competitive performance, they do not match the results of fine-tuned task-specific models, even at the largest scales (e.g. for GPT-4). Nevertheless, we do see consistent performance improvements across model scale. Additionally, we investigate prompting approaches to improve performance, and discuss the practicalities of using LLMs for these tasks.
Is Less More? Quality, Quantity and Context in Idiom Processing with Natural Language Models
May 14, 2024Compositionality in language models presents a problem when processing idiomatic expressions, as their meaning often cannot be directly derived from their individual parts. Although fine-tuning and other optimization strategies can be used to improve representations of idiomatic expressions, this depends on the availability of relevant data. We present the Noun Compound Synonym Substitution in Books - NCSSB - datasets, which are created by substitution of synonyms of potentially idiomatic English noun compounds in public domain book texts. We explore the trade-off between data quantity and quality when training models for idiomaticity detection, in conjunction with contextual information obtained locally (from the surrounding sentences) or externally (through language resources). Performance on an idiomaticity detection task indicates that dataset quality is a stronger factor for context-enriched models, but that quantity also plays a role in models without context inclusion strategies.
Word Boundary Information Isn't Useful for Encoder Language Models
Jan 15, 2024



All existing transformer-based approaches to NLP using subword tokenisation algorithms encode whitespace (word boundary information) through the use of special space symbols (such as \#\# or \_) forming part of tokens. These symbols have been shown to a) lead to reduced morphological validity of tokenisations, and b) give substantial vocabulary redundancy. As such, removing these symbols has been shown to have a beneficial effect on the processing of morphologically complex words for transformer encoders in the pretrain-finetune paradigm. In this work, we explore whether word boundary information is at all useful to such models. In particular, we train transformer encoders across four different training scales, and investigate several alternative approaches to including word boundary information, evaluating on a range of tasks across different domains and problem set-ups: GLUE (for sentence-level classification), NER (for token-level classification), and two classification datasets involving complex words (Superbizarre and FLOTA). Overall, through an extensive experimental setup that includes the pre-training of 29 models, we find no substantial improvements from our alternative approaches, suggesting that modifying tokenisers to remove word boundary information isn't leading to a loss of useful information.
Sample Efficient Approaches for Idiomaticity Detection
May 23, 2022
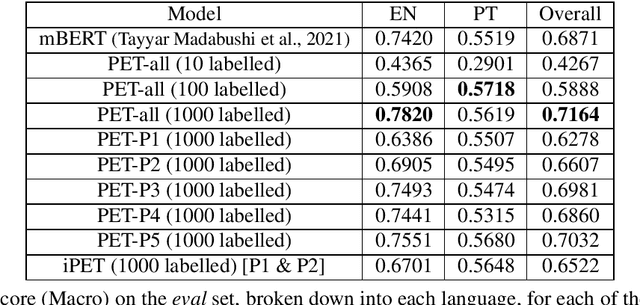
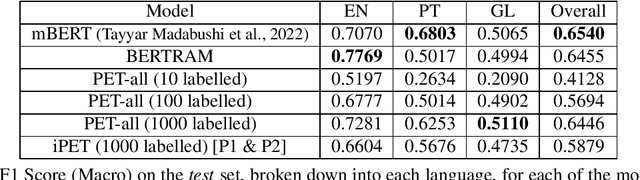

Deep neural models, in particular Transformer-based pre-trained language models, require a significant amount of data to train. This need for data tends to lead to problems when dealing with idiomatic multiword expressions (MWEs), which are inherently less frequent in natural text. As such, this work explores sample efficient methods of idiomaticity detection. In particular we study the impact of Pattern Exploit Training (PET), a few-shot method of classification, and BERTRAM, an efficient method of creating contextual embeddings, on the task of idiomaticity detection. In addition, to further explore generalisability, we focus on the identification of MWEs not present in the training data. Our experiments show that while these methods improve performance on English, they are much less effective on Portuguese and Galician, leading to an overall performance about on par with vanilla mBERT. Regardless, we believe sample efficient methods for both identifying and representing potentially idiomatic MWEs are very encouraging and hold significant potential for future exploration.
drsphelps at SemEval-2022 Task 2: Learning idiom representations using BERTRAM
Apr 07, 2022
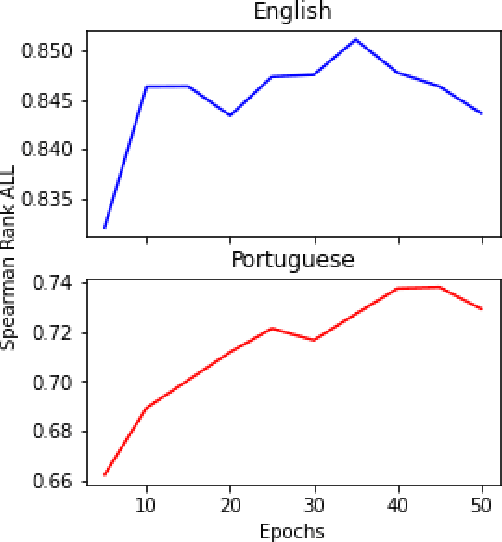

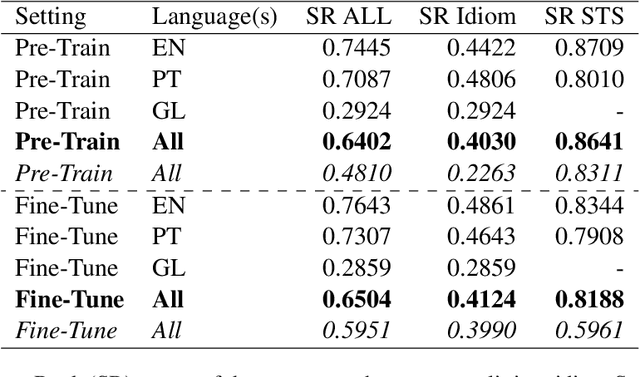
This paper describes our system for SemEval-2022 Task 2 Multilingual Idiomaticity Detection and Sentence Embedding sub-task B. We modify a standard BERT sentence transformer by adding embeddings for each idioms, which are created using BERTRAM and a small number of contexts. We show that this technique increases the quality of idiom representations and leads to better performance on the task. We also perform analysis on our final results and show that the quality of the produced idiom embeddings is highly sensitive to the quality of the input contexts.