 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond surface form: A pipeline for semantic analysis in Alzheimer's Disease detection from spontaneous speech
Dec 15, 2025Alzheimer's Disease (AD) is a progressive neurodegenerative condition that adversely affects cognitive abilities. Language-related changes can be automatically identified through the analysis of outputs from linguistic assessment tasks, such as picture description. Language models show promise as a basis for screening tools for AD, but their limited interpretability poses a challenge in distinguishing true linguistic markers of cognitive decline from surface-level textual patterns. To address this issue, we examine how surface form variation affects classification performance, with the goal of assessing the ability of language models to represent underlying semantic indicators. We introduce a novel approach where texts surface forms are transformed by altering syntax and vocabulary while preserving semantic content. The transformations significantly modify the structure and lexical content, as indicated by low BLEU and chrF scores, yet retain the underlying semantics, as reflected in high semantic similarity scores, isolating the effect of semantic information, and finding models perform similarly to if they were using the original text, with only small deviations in macro-F1. We also investigate whether language from picture descriptions retains enough detail to reconstruct the original image using generative models. We found that image-based transformations add substantial noise reducing classification accuracy. Our methodology provides a novel way of looking at what features influence model predictions, and allows the removal of possible spurious correlations. We find that just using semantic information, language model based classifiers can still detect AD. This work shows that difficult to detect semantic impairment can be identified, addressing an overlooked feature of linguistic deterioration, and opening new pathways for early detection systems.
SemEval-2025 Task 1: AdMIRe -- Advancing Multimodal Idiomaticity Representation
Mar 19, 2025Idiomatic expressions present a unique challenge in NLP, as their meanings are often not directly inferable from their constituent words. Despite recent advancements in Large Language Models (LLMs), idiomaticity remains a significant obstacle to robust semantic representation. We present datasets and tasks for SemEval-2025 Task 1: AdMiRe (Advancing Multimodal Idiomaticity Representation), which challenges the community to assess and improve models' ability to interpret idiomatic expressions in multimodal contexts and in multiple languages. Participants competed in two subtasks: ranking images based on their alignment with idiomatic or literal meanings, and predicting the next image in a sequence. The most effective methods achieved human-level performance by leveraging pretrained LLMs and vision-language models in mixture-of-experts settings, with multiple queries used to smooth over the weaknesses in these models' representations of idiomaticity.
Investigating Idiomaticity in Word Representations
Nov 04, 2024



Idiomatic expressions are an integral part of human languages, often used to express complex ideas in compressed or conventional ways (e.g. eager beaver as a keen and enthusiastic person). However, their interpretations may not be straightforwardly linked to the meanings of their individual components in isolation and this may have an impact for compositional approaches. In this paper, we investigate to what extent word representation models are able to go beyond compositional word combinations and capture multiword expression idiomaticity and some of the expected properties related to idiomatic meanings. We focus on noun compounds of varying levels of idiomaticity in two languages (English and Portuguese), presenting a dataset of minimal pairs containing human idiomaticity judgments for each noun compound at both type and token levels, their paraphrases and their occurrences in naturalistic and sense-neutral contexts, totalling 32,200 sentences. We propose this set of minimal pairs for evaluating how well a model captures idiomatic meanings, and define a set of fine-grained metrics of Affinity and Scaled Similarity, to determine how sensitive the models are to perturbations that may lead to changes in idiomaticity. The results obtained with a variety of representative and widely used models indicate that, despite superficial indications to the contrary in the form of high similarities, idiomaticity is not yet accurately represented in current models. Moreover, the performance of models with different levels of contextualisation suggests that their ability to capture context is not yet able to go beyond more superficial lexical clues provided by the words and to actually incorporate the relevant semantic clues needed for idiomaticity.
Enhancing Idiomatic Representation in Multiple Languages via an Adaptive Contrastive Triplet Loss
Jun 21, 2024Accurately modeling idiomatic or non-compositional language has been a longstanding challenge in Natural Language Processing (NLP). This is partly because these expressions do not derive their meanings solely from their constituent words, but also due to the scarcity of relevant data resources, and their impact on the performance of downstream tasks such as machine translation and simplification. In this paper we propose an approach to model idiomaticity effectively using a triplet loss that incorporates the asymmetric contribution of components words to an idiomatic meaning for training language models by using adaptive contrastive learning and resampling miners to build an idiomatic-aware learning objective. Our proposed method is evaluated on a SemEval challenge and outperforms previous alternatives significantly in many metrics.
SemEval-2022 Task 2: Multilingual Idiomaticity Detection and Sentence Embedding
Apr 21, 2022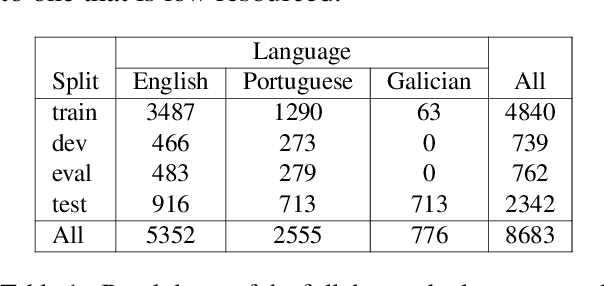
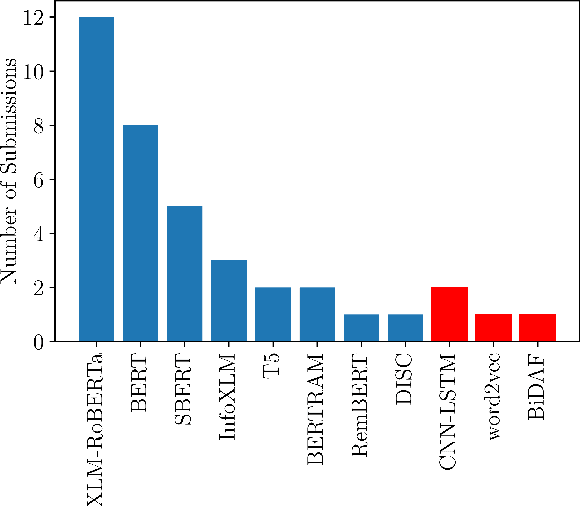

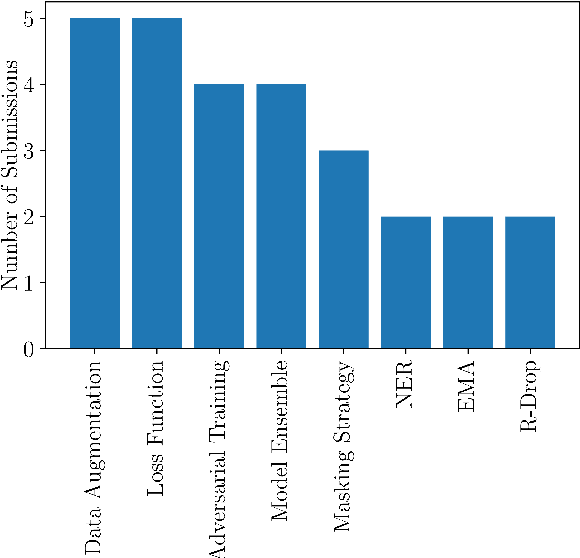
This paper presents the shared task on Multilingual Idiomaticity Detection and Sentence Embedding, which consists of two subtasks: (a) a binary classification one aimed at identifying whether a sentence contains an idiomatic expression, and (b) a task based on semantic text similarity which requires the model to adequately represent potentially idiomatic expressions in context. Each subtask includes different settings regarding the amount of training data. Besides the task description, this paper introduces the datasets in English, Portuguese, and Galician and their annotation procedure, the evaluation metrics, and a summary of the participant systems and their results. The task had close to 100 registered participants organised into twenty five teams making over 650 and 150 submissions in the practice and evaluation phases respectively.
Matrix Factorization using Window Sampling and Negative Sampling for Improved Word Representations
Jun 07, 2016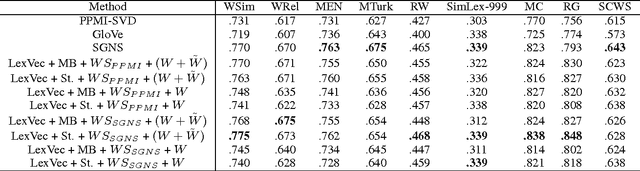
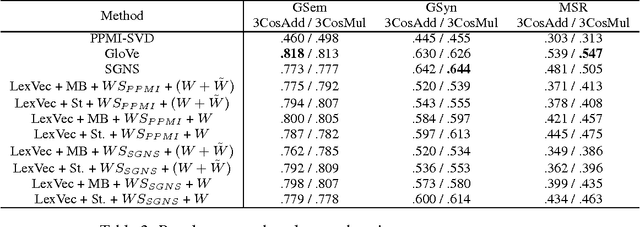
In this paper, we propose LexVec, a new method for generating distributed word representations that uses low-rank, weighted factorization of the Positive Point-wise Mutual Information matrix via stochastic gradient descent, employing a weighting scheme that assigns heavier penalties for errors on frequent co-occurrences while still accounting for negative co-occurrence. Evaluation on word similarity and analogy tasks shows that LexVec matches and often outperforms state-of-the-art methods on many of these tasks.
Enhancing the LexVec Distributed Word Representation Model Using Positional Contexts and External Memory
Jun 03, 2016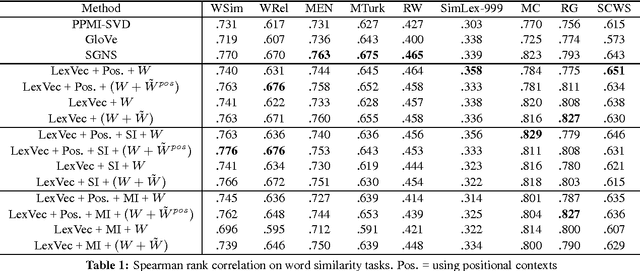
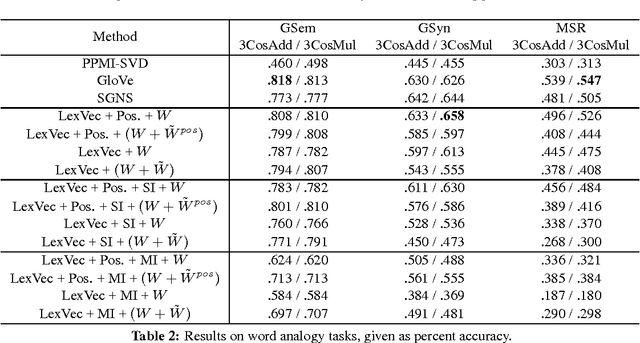
In this paper we take a state-of-the-art model for distributed word representation that explicitly factorizes the positive pointwise mutual information (PPMI) matrix using window sampling and negative sampling and address two of its shortcomings. We improve syntactic performance by using positional contexts, and solve the need to store the PPMI matrix in memory by working on aggregate data in external memory. The effectiveness of both modifications is shown using word similarity and analogy tasks.