Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing the LexVec Distributed Word Representation Model Using Positional Contexts and External Memory
Paper and Code
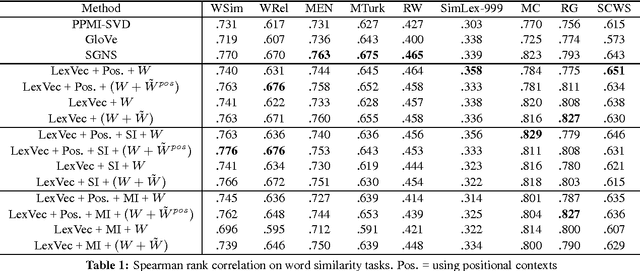
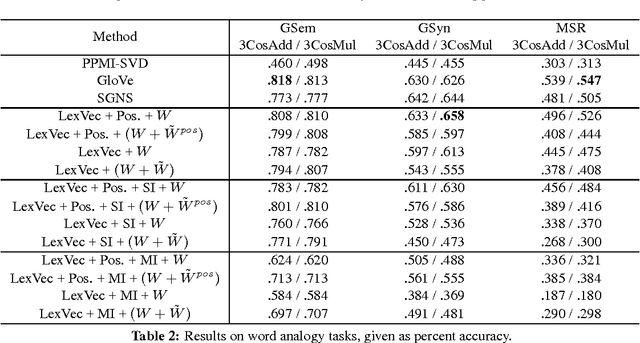
In this paper we take a state-of-the-art model for distributed word representation that explicitly factorizes the positive pointwise mutual information (PPMI) matrix using window sampling and negative sampling and address two of its shortcomings. We improve syntactic performance by using positional contexts, and solve the need to store the PPMI matrix in memory by working on aggregate data in external memory. The effectiveness of both modifications is shown using word similarity and analogy tasks.
View paper on