 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNative Language Identification with Large Language Models
Dec 13, 2023We present the first experiments on Native Language Identification (NLI) using LLMs such as GPT-4. NLI is the task of predicting a writer's first language by analyzing their writings in a second language, and is used in second language acquisition and forensic linguistics. Our results show that GPT models are proficient at NLI classification, with GPT-4 setting a new performance record of 91.7% on the benchmark TOEFL11 test set in a zero-shot setting. We also show that unlike previous fully-supervised settings, LLMs can perform NLI without being limited to a set of known classes, which has practical implications for real-world applications. Finally, we also show that LLMs can provide justification for their choices, providing reasoning based on spelling errors, syntactic patterns, and usage of directly translated linguistic patterns.
Why So Down? The Role of Negative Pointwise Mutual Information in Distributional Semantics
Aug 19, 2019
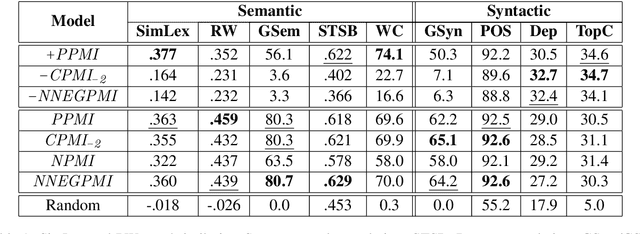
In distributional semantics, the pointwise mutual information ($\mathit{PMI}$) weighting of the cooccurrence matrix performs far better than raw counts. There is, however, an issue with unobserved pair cooccurrences as $\mathit{PMI}$ goes to negative infinity. This problem is aggravated by unreliable statistics from finite corpora which lead to a large number of such pairs. A common practice is to clip negative $\mathit{PMI}$ ($\mathit{\texttt{-} PMI}$) at $0$, also known as Positive $\mathit{PMI}$ ($\mathit{PPMI}$). In this paper, we investigate alternative ways of dealing with $\mathit{\texttt{-} PMI}$ and, more importantly, study the role that negative information plays in the performance of a low-rank, weighted factorization of different $\mathit{PMI}$ matrices. Using various semantic and syntactic tasks as probes into models which use either negative or positive $\mathit{PMI}$ (or both), we find that most of the encoded semantics and syntax come from positive $\mathit{PMI}$, in contrast to $\mathit{\texttt{-} PMI}$ which contributes almost exclusively syntactic information. Our findings deepen our understanding of distributional semantics, while also introducing novel $PMI$ variants and grounding the popular $PPMI$ measure.
Think Again Networks and the Delta Loss
Apr 30, 2019
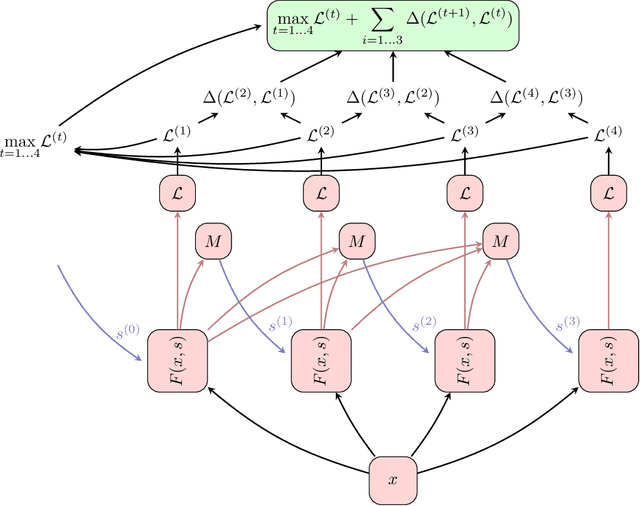
This short paper introduces an abstraction called Think Again Networks (ThinkNet) which can be applied to any state-dependent function (such as a recurrent neural network).
Restricted Recurrent Neural Tensor Networks: Exploiting Word Frequency and Compositionality
May 11, 2018
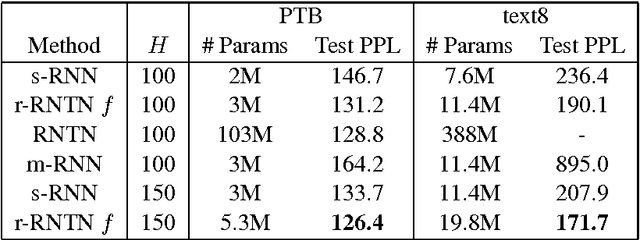
Increasing the capacity of recurrent neural networks (RNN) usually involves augmenting the size of the hidden layer, with significant increase of computational cost. Recurrent neural tensor networks (RNTN) increase capacity using distinct hidden layer weights for each word, but with greater costs in memory usage. In this paper, we introduce restricted recurrent neural tensor networks (r-RNTN) which reserve distinct hidden layer weights for frequent vocabulary words while sharing a single set of weights for infrequent words. Perplexity evaluations show that for fixed hidden layer sizes, r-RNTNs improve language model performance over RNNs using only a small fraction of the parameters of unrestricted RNTNs. These results hold for r-RNTNs using Gated Recurrent Units and Long Short-Term Memory.
Incorporating Subword Information into Matrix Factorization Word Embeddings
May 09, 2018

The positive effect of adding subword information to word embeddings has been demonstrated for predictive models. In this paper we investigate whether similar benefits can also be derived from incorporating subwords into counting models. We evaluate the impact of different types of subwords (n-grams and unsupervised morphemes), with results confirming the importance of subword information in learning representations of rare and out-of-vocabulary words.
Matrix Factorization using Window Sampling and Negative Sampling for Improved Word Representations
Jun 07, 2016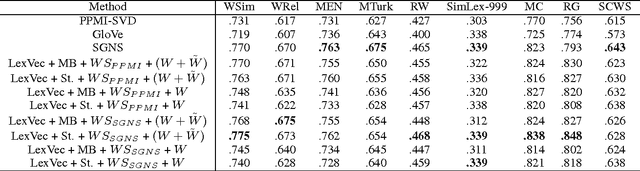
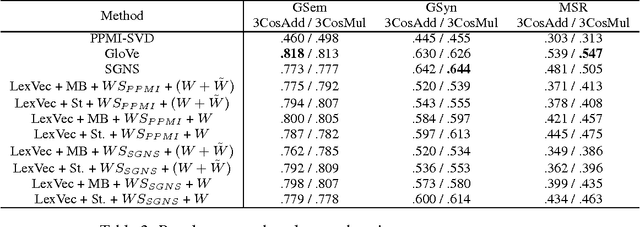
In this paper, we propose LexVec, a new method for generating distributed word representations that uses low-rank, weighted factorization of the Positive Point-wise Mutual Information matrix via stochastic gradient descent, employing a weighting scheme that assigns heavier penalties for errors on frequent co-occurrences while still accounting for negative co-occurrence. Evaluation on word similarity and analogy tasks shows that LexVec matches and often outperforms state-of-the-art methods on many of these tasks.
Enhancing the LexVec Distributed Word Representation Model Using Positional Contexts and External Memory
Jun 03, 2016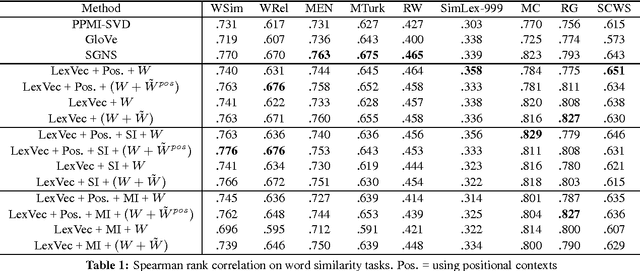
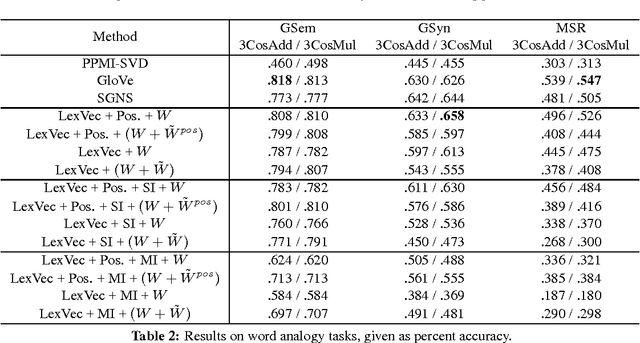
In this paper we take a state-of-the-art model for distributed word representation that explicitly factorizes the positive pointwise mutual information (PPMI) matrix using window sampling and negative sampling and address two of its shortcomings. We improve syntactic performance by using positional contexts, and solve the need to store the PPMI matrix in memory by working on aggregate data in external memory. The effectiveness of both modifications is shown using word similarity and analogy tasks.