 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy So Down? The Role of Negative Pointwise Mutual Information in Distributional Semantics
Paper and Code

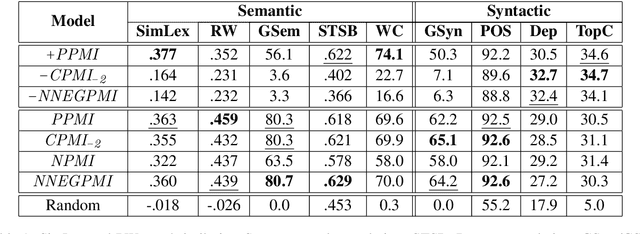
In distributional semantics, the pointwise mutual information ($\mathit{PMI}$) weighting of the cooccurrence matrix performs far better than raw counts. There is, however, an issue with unobserved pair cooccurrences as $\mathit{PMI}$ goes to negative infinity. This problem is aggravated by unreliable statistics from finite corpora which lead to a large number of such pairs. A common practice is to clip negative $\mathit{PMI}$ ($\mathit{\texttt{-} PMI}$) at $0$, also known as Positive $\mathit{PMI}$ ($\mathit{PPMI}$). In this paper, we investigate alternative ways of dealing with $\mathit{\texttt{-} PMI}$ and, more importantly, study the role that negative information plays in the performance of a low-rank, weighted factorization of different $\mathit{PMI}$ matrices. Using various semantic and syntactic tasks as probes into models which use either negative or positive $\mathit{PMI}$ (or both), we find that most of the encoded semantics and syntax come from positive $\mathit{PMI}$, in contrast to $\mathit{\texttt{-} PMI}$ which contributes almost exclusively syntactic information. Our findings deepen our understanding of distributional semantics, while also introducing novel $PMI$ variants and grounding the popular $PPMI$ measure.