 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Erasure in Text-to-Image Diffusion-based Foundation Models
Mar 25, 2025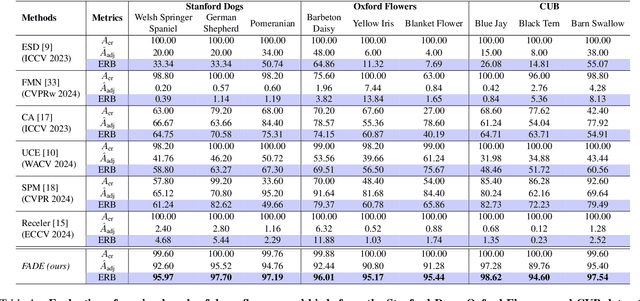
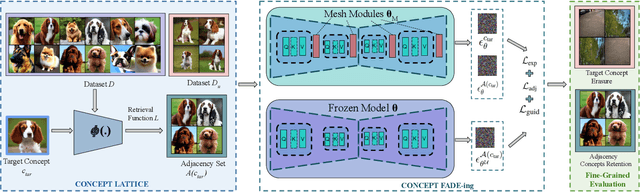
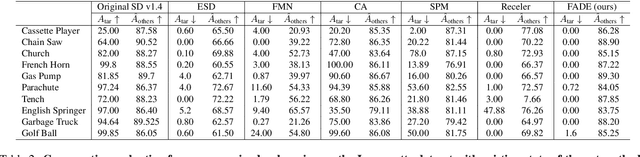
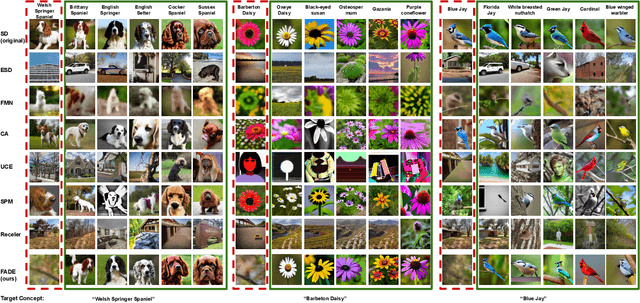
Existing unlearning algorithms in text-to-image generative models often fail to preserve the knowledge of semantically related concepts when removing specific target concepts: a challenge known as adjacency. To address this, we propose FADE (Fine grained Attenuation for Diffusion Erasure), introducing adjacency aware unlearning in diffusion models. FADE comprises two components: (1) the Concept Neighborhood, which identifies an adjacency set of related concepts, and (2) Mesh Modules, employing a structured combination of Expungement, Adjacency, and Guidance loss components. These enable precise erasure of target concepts while preserving fidelity across related and unrelated concepts. Evaluated on datasets like Stanford Dogs, Oxford Flowers, CUB, I2P, Imagenette, and ImageNet1k, FADE effectively removes target concepts with minimal impact on correlated concepts, achieving atleast a 12% improvement in retention performance over state-of-the-art methods.
Continual Unlearning for Foundational Text-to-Image Models without Generalization Erosion
Mar 17, 2025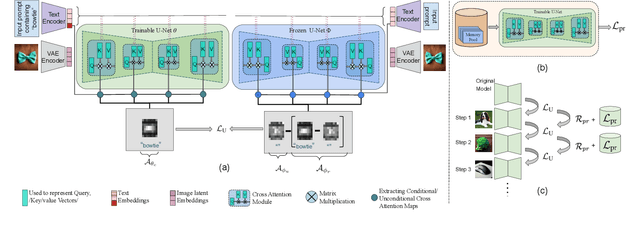

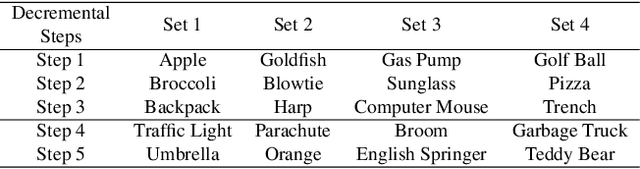

How can we effectively unlearn selected concepts from pre-trained generative foundation models without resorting to extensive retraining? This research introduces `continual unlearning', a novel paradigm that enables the targeted removal of multiple specific concepts from foundational generative models, incrementally. We propose Decremental Unlearning without Generalization Erosion (DUGE) algorithm which selectively unlearns the generation of undesired concepts while preserving the generation of related, non-targeted concepts and alleviating generalization erosion. For this, DUGE targets three losses: a cross-attention loss that steers the focus towards images devoid of the target concept; a prior-preservation loss that safeguards knowledge related to non-target concepts; and a regularization loss that prevents the model from suffering from generalization erosion. Experimental results demonstrate the ability of the proposed approach to exclude certain concepts without compromising the overall integrity and performance of the model. This offers a pragmatic solution for refining generative models, adeptly handling the intricacies of model training and concept management lowering the risks of copyright infringement, personal or licensed material misuse, and replication of distinctive artistic styles. Importantly, it maintains the non-targeted concepts, thereby safeguarding the model's core capabilities and effectiveness.
Navigating Text-to-Image Generative Bias across Indic Languages
Aug 01, 2024


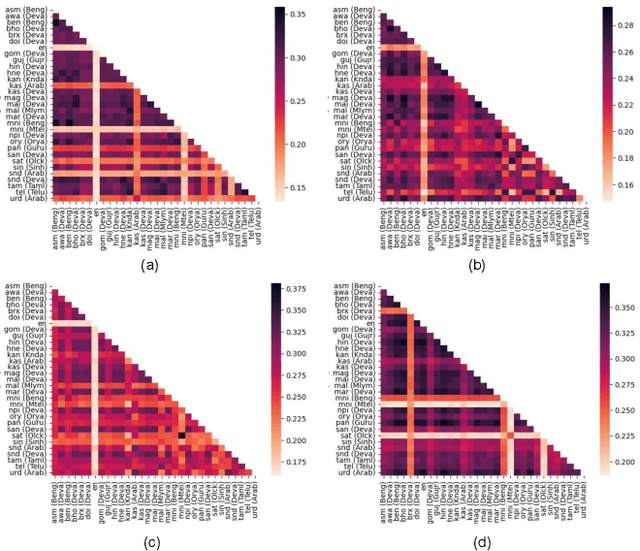
This research investigates biases in text-to-image (TTI) models for the Indic languages widely spoken across India. It evaluates and compares the generative performance and cultural relevance of leading TTI models in these languages against their performance in English. Using the proposed IndicTTI benchmark, we comprehensively assess the performance of 30 Indic languages with two open-source diffusion models and two commercial generation APIs. The primary objective of this benchmark is to evaluate the support for Indic languages in these models and identify areas needing improvement. Given the linguistic diversity of 30 languages spoken by over 1.4 billion people, this benchmark aims to provide a detailed and insightful analysis of TTI models' effectiveness within the Indic linguistic landscape. The data and code for the IndicTTI benchmark can be accessed at https://iab-rubric.org/resources/other-databases/indictti.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
On Responsible Machine Learning Datasets with Fairness, Privacy, and Regulatory Norms
Oct 31, 2023
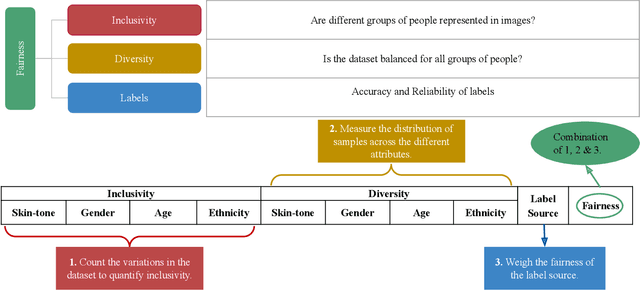


Artificial Intelligence (AI) has made its way into various scientific fields, providing astonishing improvements over existing algorithms for a wide variety of tasks. In recent years, there have been severe concerns over the trustworthiness of AI technologies. The scientific community has focused on the development of trustworthy AI algorithms. However, machine and deep learning algorithms, popular in the AI community today, depend heavily on the data used during their development. These learning algorithms identify patterns in the data, learning the behavioral objective. Any flaws in the data have the potential to translate directly into algorithms. In this study, we discuss the importance of Responsible Machine Learning Datasets and propose a framework to evaluate the datasets through a responsible rubric. While existing work focuses on the post-hoc evaluation of algorithms for their trustworthiness, we provide a framework that considers the data component separately to understand its role in the algorithm. We discuss responsible datasets through the lens of fairness, privacy, and regulatory compliance and provide recommendations for constructing future datasets. After surveying over 100 datasets, we use 60 datasets for analysis and demonstrate that none of these datasets is immune to issues of fairness, privacy preservation, and regulatory compliance. We provide modifications to the ``datasheets for datasets" with important additions for improved dataset documentation. With governments around the world regularizing data protection laws, the method for the creation of datasets in the scientific community requires revision. We believe this study is timely and relevant in today's era of AI.
You Only Need a Good Embeddings Extractor to Fix Spurious Correlations
Dec 12, 2022Spurious correlations in training data often lead to robustness issues since models learn to use them as shortcuts. For example, when predicting whether an object is a cow, a model might learn to rely on its green background, so it would do poorly on a cow on a sandy background. A standard dataset for measuring state-of-the-art on methods mitigating this problem is Waterbirds. The best method (Group Distributionally Robust Optimization - GroupDRO) currently achieves 89\% worst group accuracy and standard training from scratch on raw images only gets 72\%. GroupDRO requires training a model in an end-to-end manner with subgroup labels. In this paper, we show that we can achieve up to 90\% accuracy without using any sub-group information in the training set by simply using embeddings from a large pre-trained vision model extractor and training a linear classifier on top of it. With experiments on a wide range of pre-trained models and pre-training datasets, we show that the capacity of the pre-training model and the size of the pre-training dataset matters. Our experiments reveal that high capacity vision transformers perform better compared to high capacity convolutional neural networks, and larger pre-training dataset leads to better worst-group accuracy on the spurious correlation dataset.
PETA: Photo Albums Event Recognition using Transformers Attention
Sep 26, 2021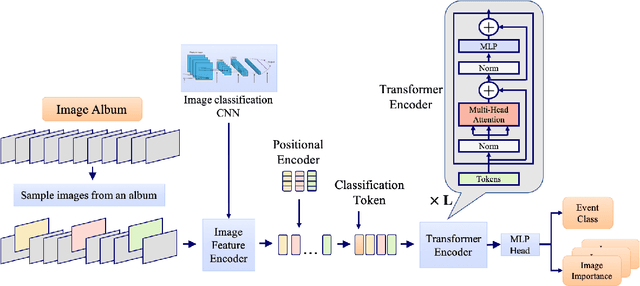
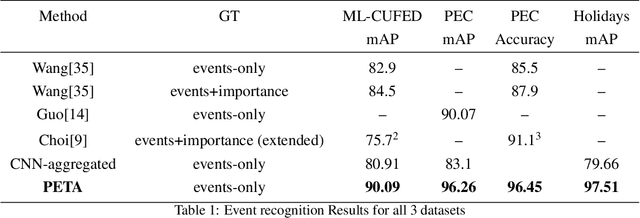

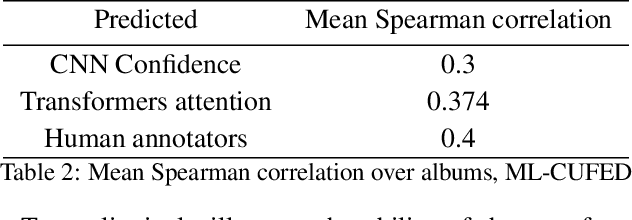
In recent years the amounts of personal photos captured increased significantly, giving rise to new challenges in multi-image understanding and high-level image understanding. Event recognition in personal photo albums presents one challenging scenario where life events are recognized from a disordered collection of images, including both relevant and irrelevant images. Event recognition in images also presents the challenge of high-level image understanding, as opposed to low-level image object classification. In absence of methods to analyze multiple inputs, previous methods adopted temporal mechanisms, including various forms of recurrent neural networks. However, their effective temporal window is local. In addition, they are not a natural choice given the disordered characteristic of photo albums. We address this gap with a tailor-made solution, combining the power of CNNs for image representation and transformers for album representation to perform global reasoning on image collection, offering a practical and efficient solution for photo albums event recognition. Our solution reaches state-of-the-art results on 3 prominent benchmarks, achieving above 90\% mAP on all datasets. We further explore the related image-importance task in event recognition, demonstrating how the learned attentions correlate with the human-annotated importance for this subjective task, thus opening the door for new applications.