 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Audio Strikes Back: Boosting Augmentations Towards An Efficient Audio Classification Network
Apr 29, 2022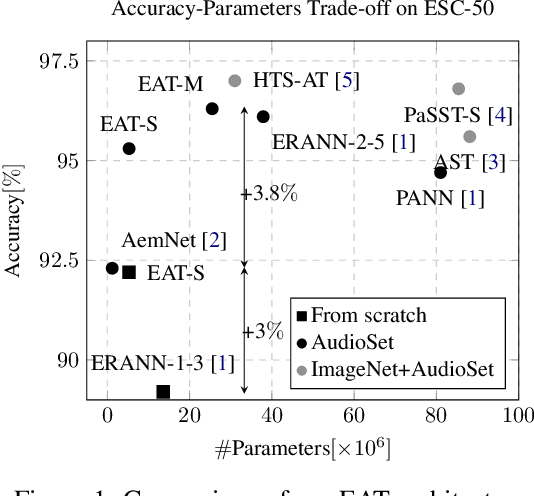

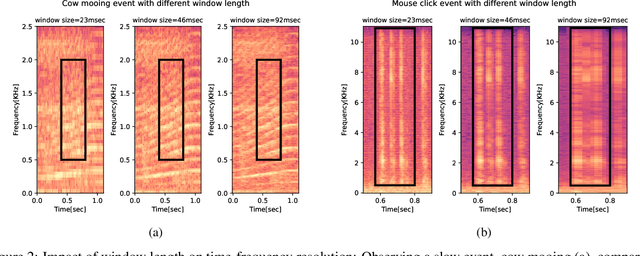
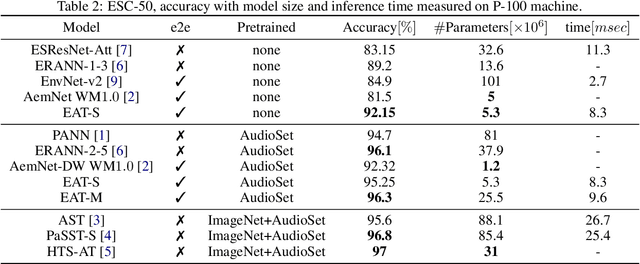
While efficient architectures and a plethora of augmentations for end-to-end image classification tasks have been suggested and heavily investigated, state-of-the-art techniques for audio classifications still rely on numerous representations of the audio signal together with large architectures, fine-tuned from large datasets. By utilizing the inherited lightweight nature of audio and novel audio augmentations, we were able to present an efficient end-to-end network with strong generalization ability. Experiments on a variety of sound classification sets demonstrate the effectiveness and robustness of our approach, by achieving state-of-the-art results in various settings. Public code will be available.
ML-Decoder: Scalable and Versatile Classification Head
Nov 25, 2021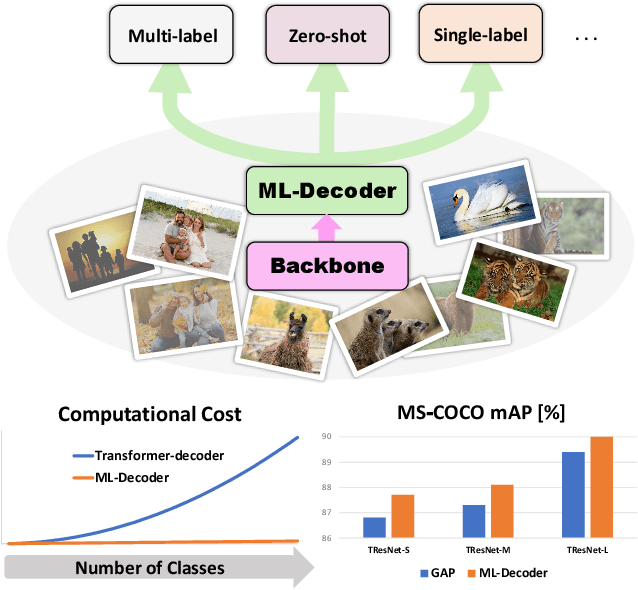
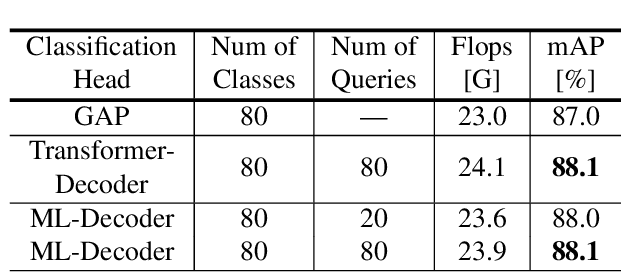
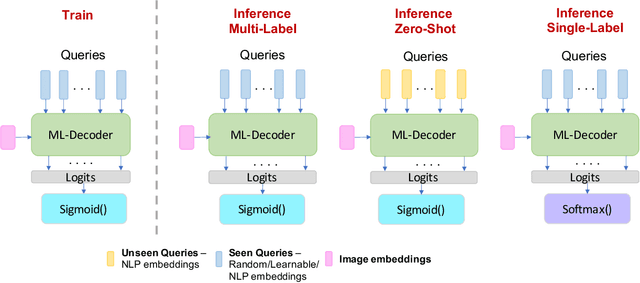
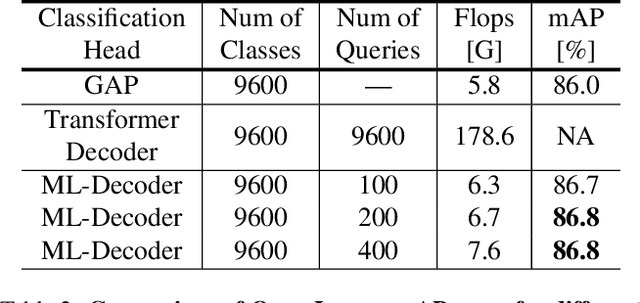
In this paper, we introduce ML-Decoder, a new attention-based classification head. ML-Decoder predicts the existence of class labels via queries, and enables better utilization of spatial data compared to global average pooling. By redesigning the decoder architecture, and using a novel group-decoding scheme, ML-Decoder is highly efficient, and can scale well to thousands of classes. Compared to using a larger backbone, ML-Decoder consistently provides a better speed-accuracy trade-off. ML-Decoder is also versatile - it can be used as a drop-in replacement for various classification heads, and generalize to unseen classes when operated with word queries. Novel query augmentations further improve its generalization ability. Using ML-Decoder, we achieve state-of-the-art results on several classification tasks: on MS-COCO multi-label, we reach 91.4% mAP; on NUS-WIDE zero-shot, we reach 31.1% ZSL mAP; and on ImageNet single-label, we reach with vanilla ResNet50 backbone a new top score of 80.7%, without extra data or distillation. Public code is available at: https://github.com/Alibaba-MIIL/ML_Decoder
PETA: Photo Albums Event Recognition using Transformers Attention
Sep 26, 2021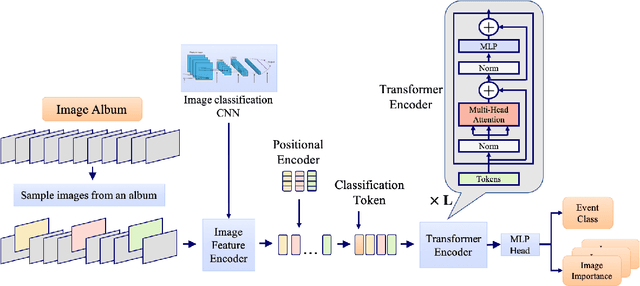
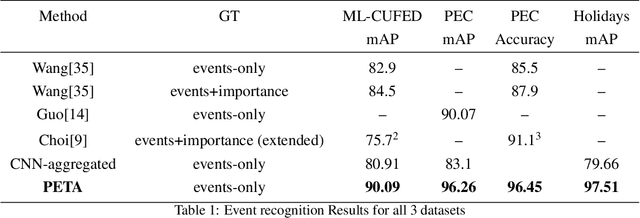

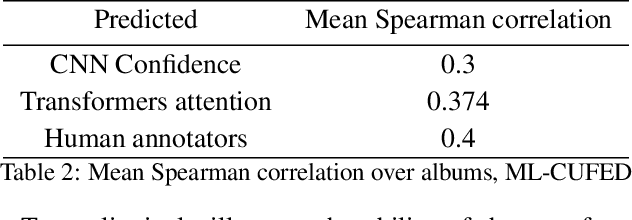
In recent years the amounts of personal photos captured increased significantly, giving rise to new challenges in multi-image understanding and high-level image understanding. Event recognition in personal photo albums presents one challenging scenario where life events are recognized from a disordered collection of images, including both relevant and irrelevant images. Event recognition in images also presents the challenge of high-level image understanding, as opposed to low-level image object classification. In absence of methods to analyze multiple inputs, previous methods adopted temporal mechanisms, including various forms of recurrent neural networks. However, their effective temporal window is local. In addition, they are not a natural choice given the disordered characteristic of photo albums. We address this gap with a tailor-made solution, combining the power of CNNs for image representation and transformers for album representation to perform global reasoning on image collection, offering a practical and efficient solution for photo albums event recognition. Our solution reaches state-of-the-art results on 3 prominent benchmarks, achieving above 90\% mAP on all datasets. We further explore the related image-importance task in event recognition, demonstrating how the learned attentions correlate with the human-annotated importance for this subjective task, thus opening the door for new applications.
An Image is Worth 16x16 Words, What is a Video Worth?
Mar 25, 2021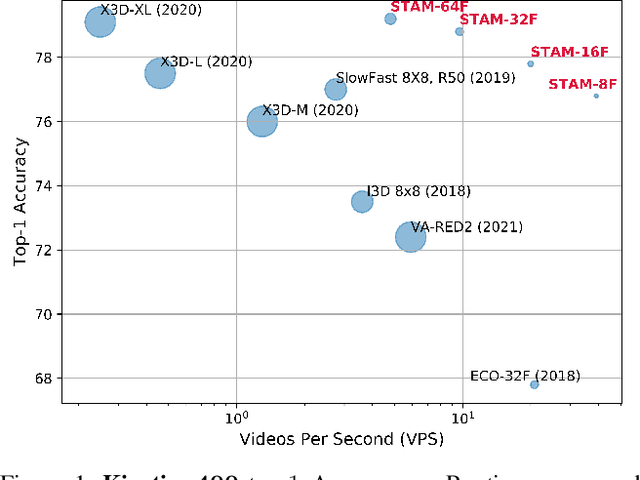
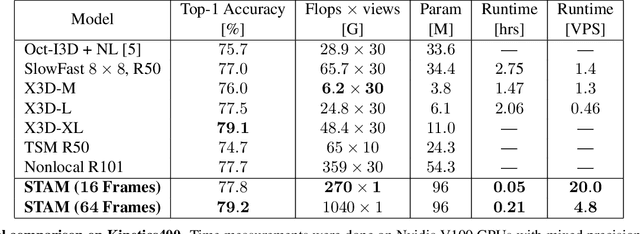

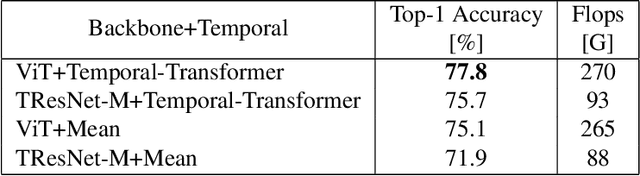
Leading methods in the domain of action recognition try to distill information from both the spatial and temporal dimensions of an input video. Methods that reach State of the Art (SotA) accuracy, usually make use of 3D convolution layers as a way to abstract the temporal information from video frames. The use of such convolutions requires sampling short clips from the input video, where each clip is a collection of closely sampled frames. Since each short clip covers a small fraction of an input video, multiple clips are sampled at inference in order to cover the whole temporal length of the video. This leads to increased computational load and is impractical for real-world applications. We address the computational bottleneck by significantly reducing the number of frames required for inference. Our approach relies on a temporal transformer that applies global attention over video frames, and thus better exploits the salient information in each frame. Therefore our approach is very input efficient, and can achieve SotA results (on Kinetics dataset) with a fraction of the data (frames per video), computation and latency. Specifically on Kinetics-400, we reach 78.8 top-1 accuracy with $\times 30$ less frames per video, and $\times 40$ faster inference than the current leading method. Code is available at: https://github.com/Alibaba-MIIL/STAM
Graph Embedded Pose Clustering for Anomaly Detection
Dec 26, 2019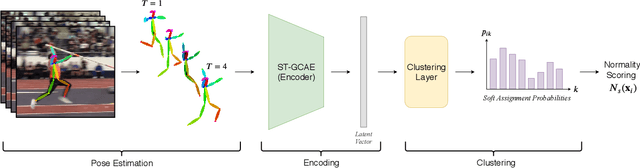
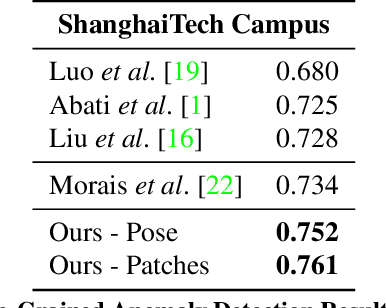

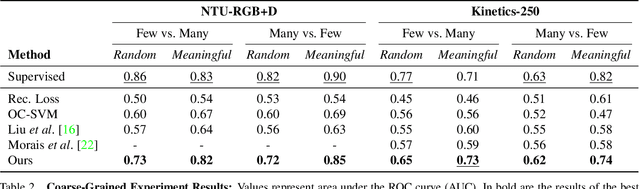
We propose a new method for anomaly detection of human actions. Our method works directly on human pose graphs that can be computed from an input video sequence. This makes the analysis independent of nuisance parameters such as viewpoint or illumination. We map these graphs to a latent space and cluster them. Each action is then represented by its soft-assignment to each of the clusters. This gives a kind of "bag of words" representation to the data, where every action is represented by its similarity to a group of base action-words. Then, we use a Dirichlet process based mixture, that is useful for handling proportional data such as our soft-assignment vectors, to determine if an action is normal or not. We evaluate our method on two types of data sets. The first is a fine-grained anomaly detection data set (e.g. ShanghaiTech) where we wish to detect unusual variations of some action. The second is a coarse-grained anomaly detection data set (e.g.,\ a Kinetics-based data set) where few actions are considered normal, and every other action should be considered abnormal. Extensive experiments on the benchmarks show that our method performs considerably better than other state of the art methods.
Video Object Segmentation using Tracked Object Proposals
Jul 20, 2017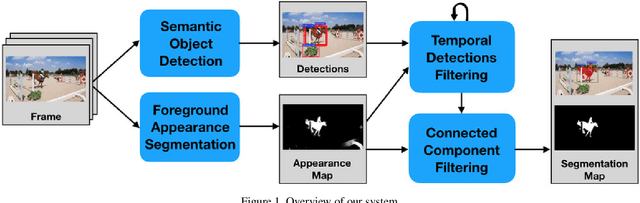
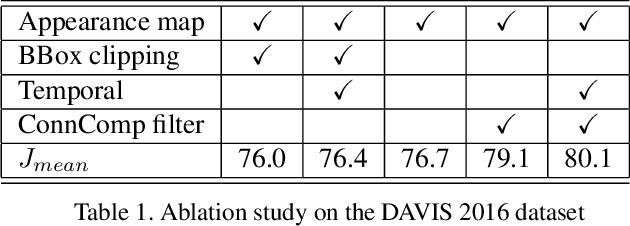

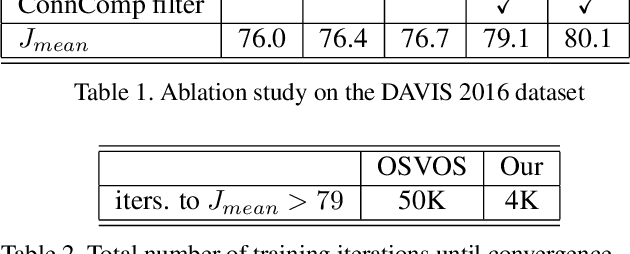
We present an approach to semi-supervised video object segmentation, in the context of the DAVIS 2017 challenge. Our approach combines category-based object detection, category-independent object appearance segmentation and temporal object tracking. We are motivated by the fact that the objects semantic category tends not to change throughout the video while its appearance and location can vary considerably. In order to capture the specific object appearance independent of its category, for each video we train a fully convolutional network using augmentations of the given annotated frame. We refine the appearance segmentation mask with the bounding boxes provided either by a semantic object detection network, when applicable, or by a previous frame prediction. By introducing a temporal continuity constraint on the detected boxes, we are able to improve the object segmentation mask of the appearance network and achieve competitive results on the DAVIS datasets.