 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Audio Strikes Back: Boosting Augmentations Towards An Efficient Audio Classification Network
Apr 29, 2022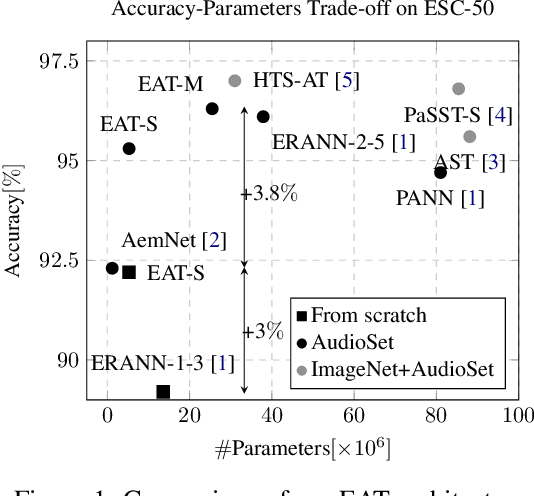

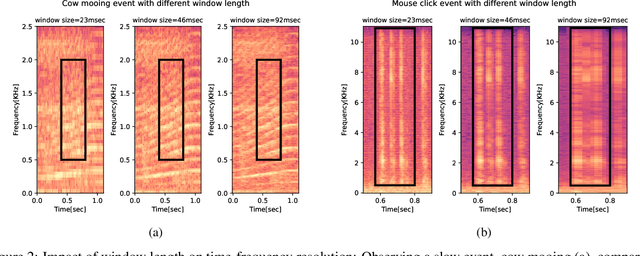
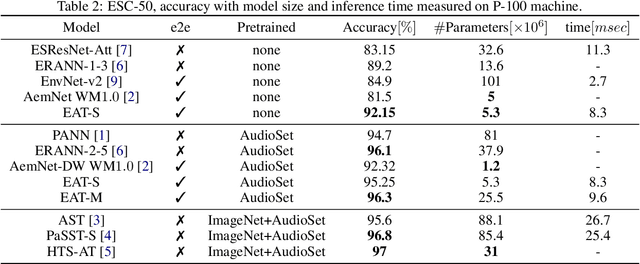
While efficient architectures and a plethora of augmentations for end-to-end image classification tasks have been suggested and heavily investigated, state-of-the-art techniques for audio classifications still rely on numerous representations of the audio signal together with large architectures, fine-tuned from large datasets. By utilizing the inherited lightweight nature of audio and novel audio augmentations, we were able to present an efficient end-to-end network with strong generalization ability. Experiments on a variety of sound classification sets demonstrate the effectiveness and robustness of our approach, by achieving state-of-the-art results in various settings. Public code will be available.
Structure First Detail Next: Image Inpainting with Pyramid Generator
Jun 16, 2021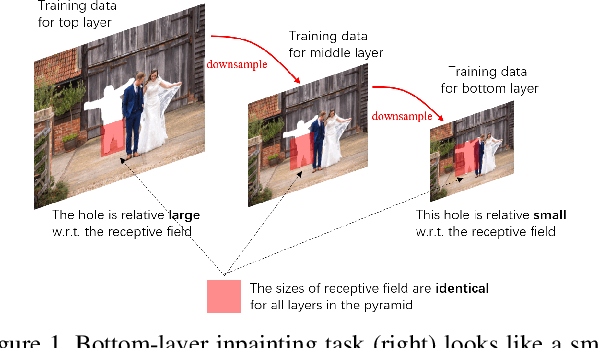

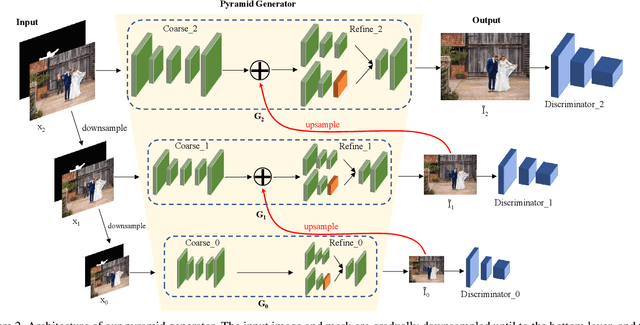
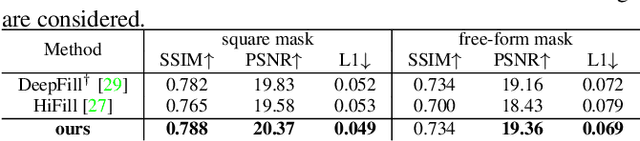
Recent deep generative models have achieved promising performance in image inpainting. However, it is still very challenging for a neural network to generate realistic image details and textures, due to its inherent spectral bias. By our understanding of how artists work, we suggest to adopt a `structure first detail next' workflow for image inpainting. To this end, we propose to build a Pyramid Generator by stacking several sub-generators, where lower-layer sub-generators focus on restoring image structures while the higher-layer sub-generators emphasize image details. Given an input image, it will be gradually restored by going through the entire pyramid in a bottom-up fashion. Particularly, our approach has a learning scheme of progressively increasing hole size, which allows it to restore large-hole images. In addition, our method could fully exploit the benefits of learning with high-resolution images, and hence is suitable for high-resolution image inpainting. Extensive experimental results on benchmark datasets have validated the effectiveness of our approach compared with state-of-the-art methods.