 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode Generation with AlphaCodium: From Prompt Engineering to Flow Engineering
Jan 16, 2024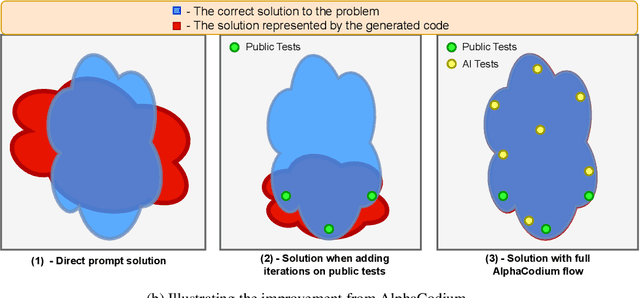
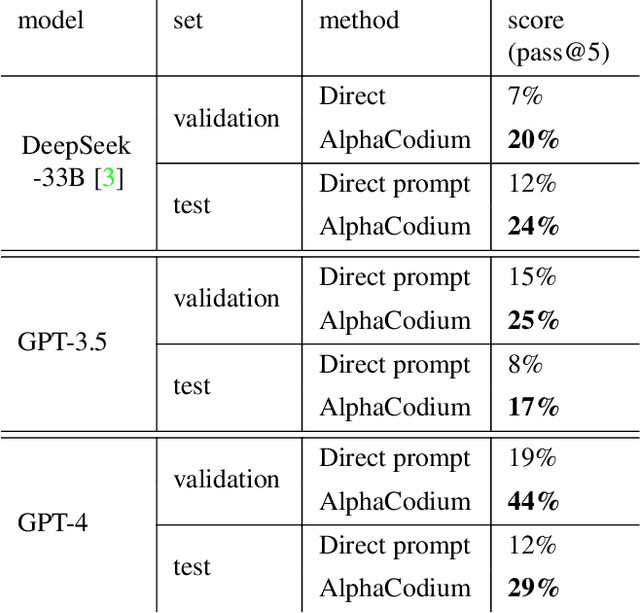

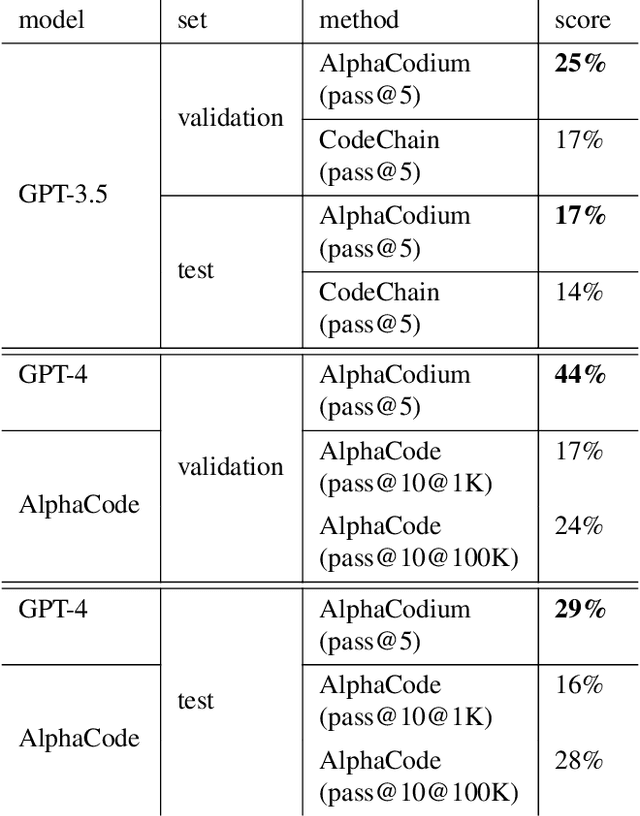
Code generation problems differ from common natural language problems - they require matching the exact syntax of the target language, identifying happy paths and edge cases, paying attention to numerous small details in the problem spec, and addressing other code-specific issues and requirements. Hence, many of the optimizations and tricks that have been successful in natural language generation may not be effective for code tasks. In this work, we propose a new approach to code generation by LLMs, which we call AlphaCodium - a test-based, multi-stage, code-oriented iterative flow, that improves the performances of LLMs on code problems. We tested AlphaCodium on a challenging code generation dataset called CodeContests, which includes competitive programming problems from platforms such as Codeforces. The proposed flow consistently and significantly improves results. On the validation set, for example, GPT-4 accuracy (pass@5) increased from 19% with a single well-designed direct prompt to 44% with the AlphaCodium flow. Many of the principles and best practices acquired in this work, we believe, are broadly applicable to general code generation tasks. Full implementation is available at: https://github.com/Codium-ai/AlphaCodium
End-to-End Audio Strikes Back: Boosting Augmentations Towards An Efficient Audio Classification Network
Apr 29, 2022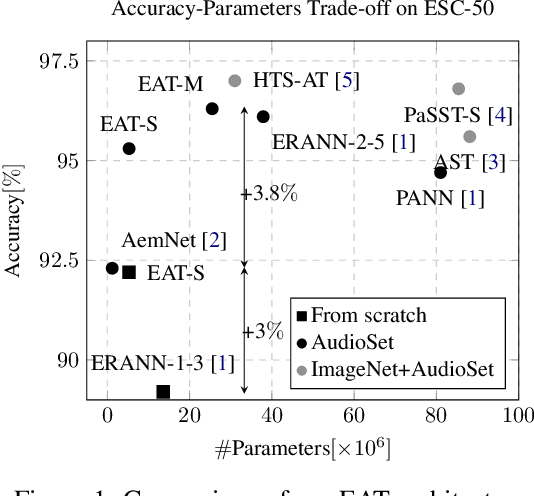

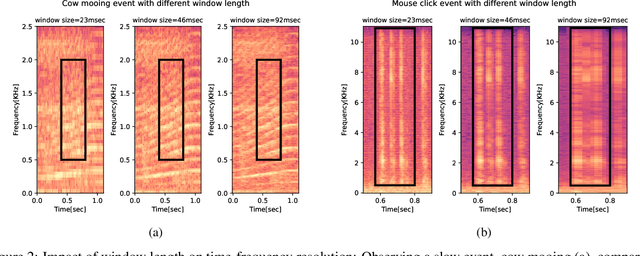
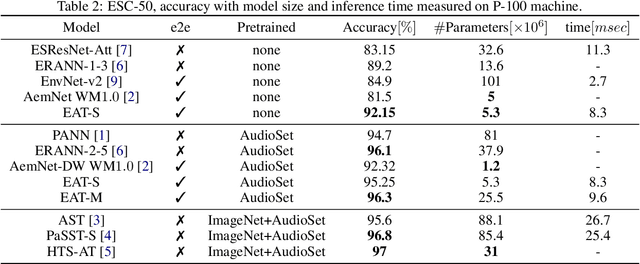
While efficient architectures and a plethora of augmentations for end-to-end image classification tasks have been suggested and heavily investigated, state-of-the-art techniques for audio classifications still rely on numerous representations of the audio signal together with large architectures, fine-tuned from large datasets. By utilizing the inherited lightweight nature of audio and novel audio augmentations, we were able to present an efficient end-to-end network with strong generalization ability. Experiments on a variety of sound classification sets demonstrate the effectiveness and robustness of our approach, by achieving state-of-the-art results in various settings. Public code will be available.
Solving ImageNet: a Unified Scheme for Training any Backbone to Top Results
Apr 07, 2022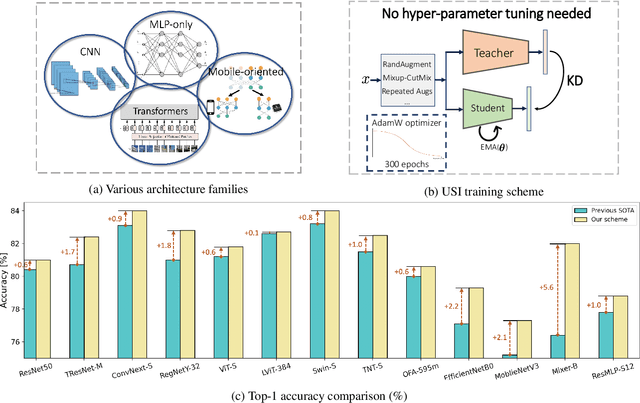
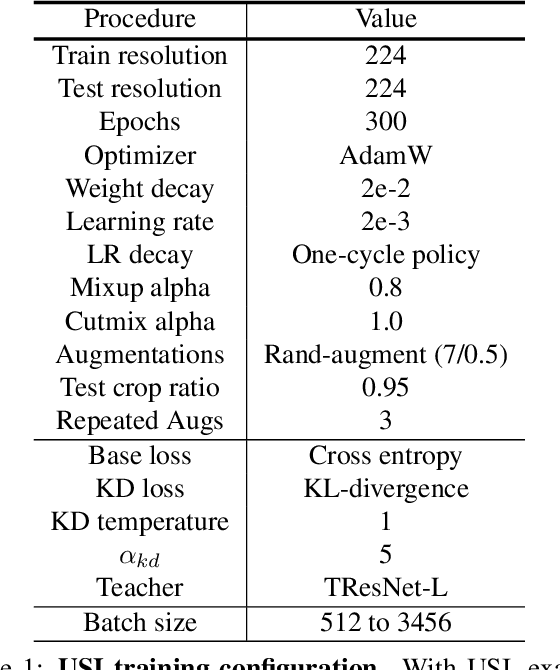
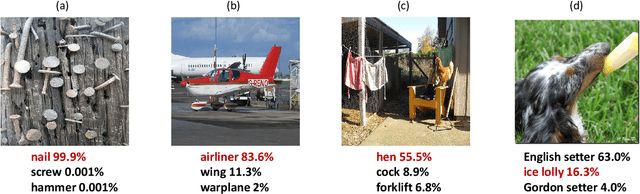
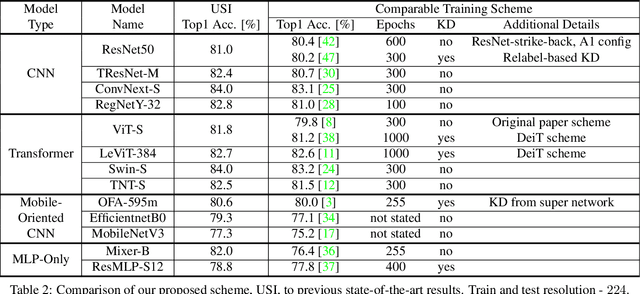
ImageNet serves as the primary dataset for evaluating the quality of computer-vision models. The common practice today is training each architecture with a tailor-made scheme, designed and tuned by an expert. In this paper, we present a unified scheme for training any backbone on ImageNet. The scheme, named USI (Unified Scheme for ImageNet), is based on knowledge distillation and modern tricks. It requires no adjustments or hyper-parameters tuning between different models, and is efficient in terms of training times. We test USI on a wide variety of architectures, including CNNs, Transformers, Mobile-oriented and MLP-only. On all models tested, USI outperforms previous state-of-the-art results. Hence, we are able to transform training on ImageNet from an expert-oriented task to an automatic seamless routine. Since USI accepts any backbone and trains it to top results, it also enables to perform methodical comparisons, and identify the most efficient backbones along the speed-accuracy Pareto curve. Implementation is available at:https://github.com/Alibaba-MIIL/Solving_ImageNet
ML-Decoder: Scalable and Versatile Classification Head
Nov 25, 2021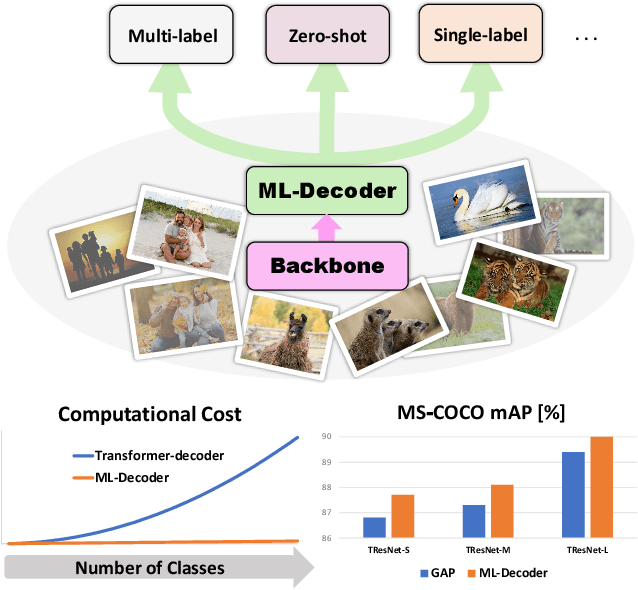
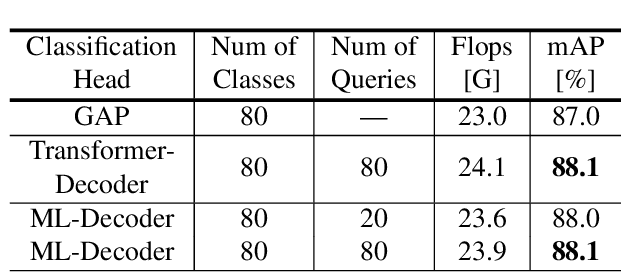
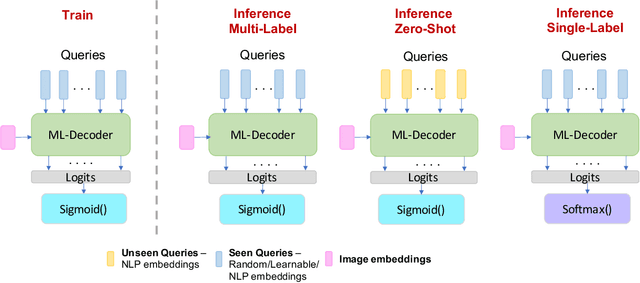
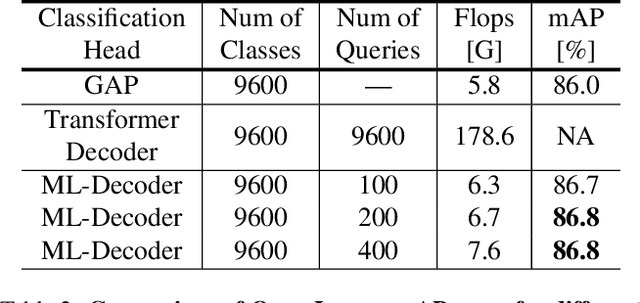
In this paper, we introduce ML-Decoder, a new attention-based classification head. ML-Decoder predicts the existence of class labels via queries, and enables better utilization of spatial data compared to global average pooling. By redesigning the decoder architecture, and using a novel group-decoding scheme, ML-Decoder is highly efficient, and can scale well to thousands of classes. Compared to using a larger backbone, ML-Decoder consistently provides a better speed-accuracy trade-off. ML-Decoder is also versatile - it can be used as a drop-in replacement for various classification heads, and generalize to unseen classes when operated with word queries. Novel query augmentations further improve its generalization ability. Using ML-Decoder, we achieve state-of-the-art results on several classification tasks: on MS-COCO multi-label, we reach 91.4% mAP; on NUS-WIDE zero-shot, we reach 31.1% ZSL mAP; and on ImageNet single-label, we reach with vanilla ResNet50 backbone a new top score of 80.7%, without extra data or distillation. Public code is available at: https://github.com/Alibaba-MIIL/ML_Decoder
Multi-label Classification with Partial Annotations using Class-aware Selective Loss
Oct 21, 2021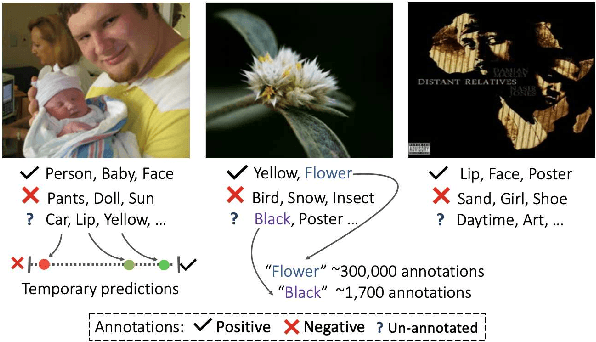
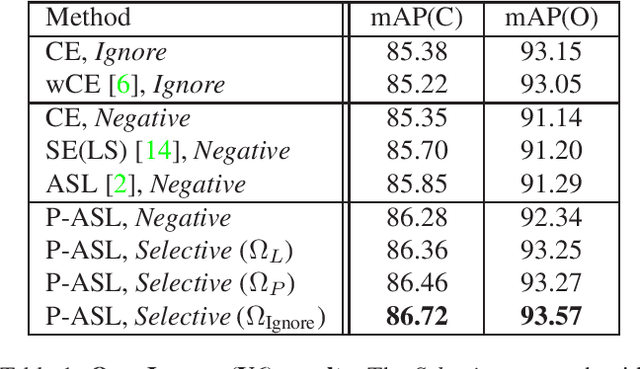
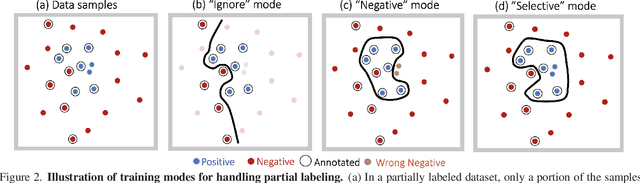

Large-scale multi-label classification datasets are commonly, and perhaps inevitably, partially annotated. That is, only a small subset of labels are annotated per sample. Different methods for handling the missing labels induce different properties on the model and impact its accuracy. In this work, we analyze the partial labeling problem, then propose a solution based on two key ideas. First, un-annotated labels should be treated selectively according to two probability quantities: the class distribution in the overall dataset and the specific label likelihood for a given data sample. We propose to estimate the class distribution using a dedicated temporary model, and we show its improved efficiency over a naive estimation computed using the dataset's partial annotations. Second, during the training of the target model, we emphasize the contribution of annotated labels over originally un-annotated labels by using a dedicated asymmetric loss. With our novel approach, we achieve state-of-the-art results on OpenImages dataset (e.g. reaching 87.3 mAP on V6). In addition, experiments conducted on LVIS and simulated-COCO demonstrate the effectiveness of our approach. Code is available at https://github.com/Alibaba-MIIL/PartialLabelingCSL.
ImageNet-21K Pretraining for the Masses
May 04, 2021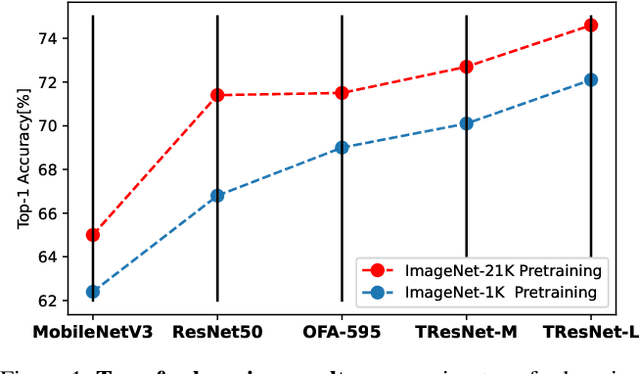

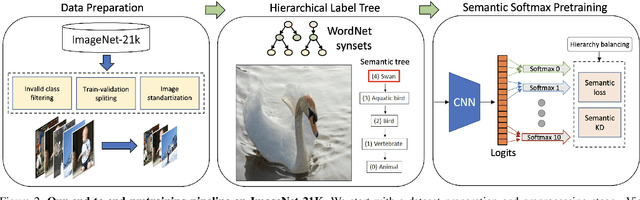
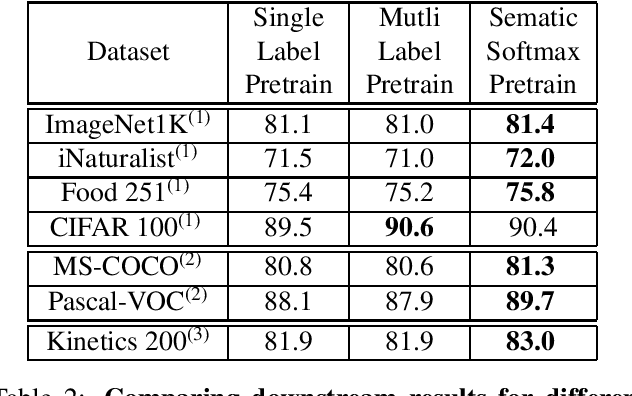
ImageNet-1K serves as the primary dataset for pretraining deep learning models for computer vision tasks. ImageNet-21K dataset, which contains more pictures and classes, is used less frequently for pretraining, mainly due to its complexity, and underestimation of its added value compared to standard ImageNet-1K pretraining. This paper aims to close this gap, and make high-quality efficient pretraining on ImageNet-21K available for everyone. Via a dedicated preprocessing stage, utilizing WordNet hierarchies, and a novel training scheme called semantic softmax, we show that various models, including small mobile-oriented models, significantly benefit from ImageNet-21K pretraining on numerous datasets and tasks. We also show that we outperform previous ImageNet-21K pretraining schemes for prominent new models like ViT. Our proposed pretraining pipeline is efficient, accessible, and leads to SoTA reproducible results, from a publicly available dataset. The training code and pretrained models are available at: https://github.com/Alibaba-MIIL/ImageNet21K
Asymmetric Loss For Multi-Label Classification
Sep 29, 2020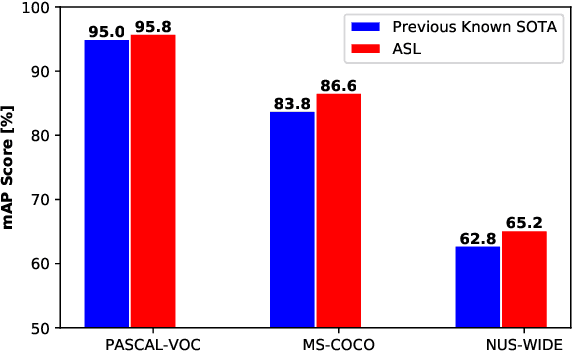
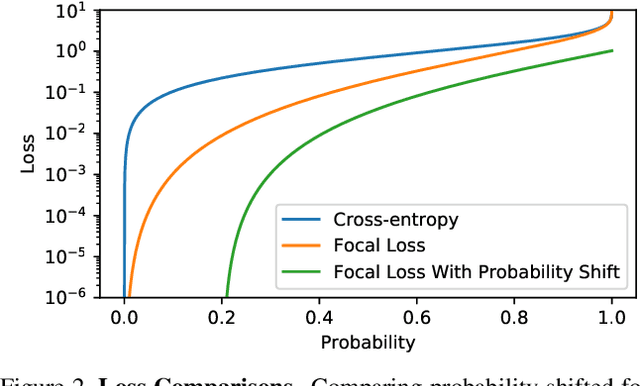
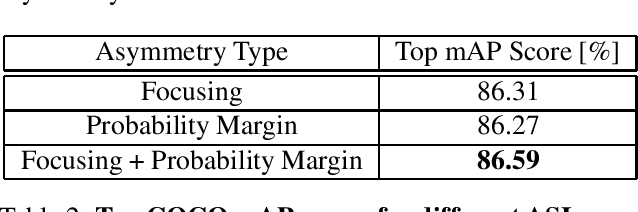
Pictures of everyday life are inherently multi-label in nature. Hence, multi-label classification is commonly used to analyze their content. In typical multi-label datasets, each picture contains only a few positive labels, and many negative ones. This positive-negative imbalance can result in under-emphasizing gradients from positive labels during training, leading to poor accuracy. In this paper, we introduce a novel asymmetric loss ("ASL"), that operates differently on positive and negative samples. The loss dynamically down-weights the importance of easy negative samples, causing the optimization process to focus more on the positive samples, and also enables to discard mislabeled negative samples. We demonstrate how ASL leads to a more "balanced" network, with increased average probabilities for positive samples, and show how this balanced network is translated to better mAP scores, compared to commonly used losses. Furthermore, we offer a method that can dynamically adjust the level of asymmetry throughout the training. With ASL, we reach new state-of-the-art results on three common multi-label datasets, including achieving 86.6% on MS-COCO. We also demonstrate ASL applicability for other tasks such as fine-grain single-label classification and object detection. ASL is effective, easy to implement, and does not increase the training time or complexity. Implementation is available at: https://github.com/Alibaba-MIIL/ASL.
TResNet: High Performance GPU-Dedicated Architecture
Mar 30, 2020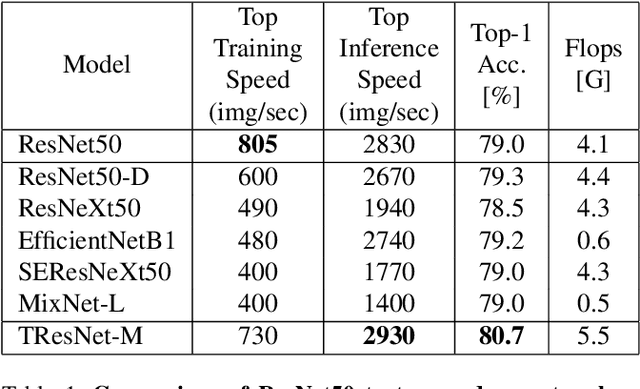
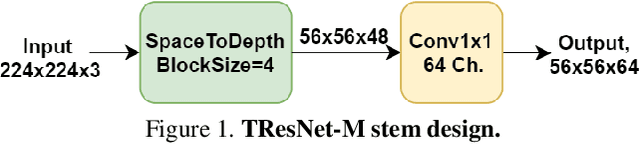
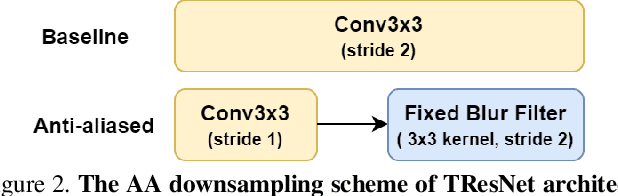
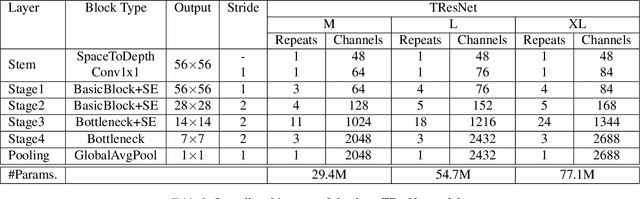
Many deep learning models, developed in recent years, reach higher ImageNet accuracy than ResNet50, with fewer or comparable FLOPS count. While FLOPs are often seen as a proxy for network efficiency, when measuring actual GPU training and inference throughput, vanilla ResNet50 is usually significantly faster than its recent competitors, offering better throughput-accuracy trade-off. In this work, we introduce a series of architecture modifications that aim to boost neural networks' accuracy, while retaining their GPU training and inference efficiency. We first demonstrate and discuss the bottlenecks induced by FLOPs-optimizations. We then suggest alternative designs that better utilize GPU structure and assets. Finally, we introduce a new family of GPU-dedicated models, called TResNet, which achieve better accuracy and efficiency than previous ConvNets. Using a TResNet model, with similar GPU throughput to ResNet50, we reach 80.7% top-1 accuracy on ImageNet. Our TResNet models also transfer well and achieve state-of-the-art accuracy on competitive datasets such as Stanford cars (96.0%), CIFAR-10 (99.0%), CIFAR-100 (91.5%) and Oxford-Flowers (99.1%). Implementation is available at: https://github.com/mrT23/TResNet
XNAS: Neural Architecture Search with Expert Advice
Jun 19, 2019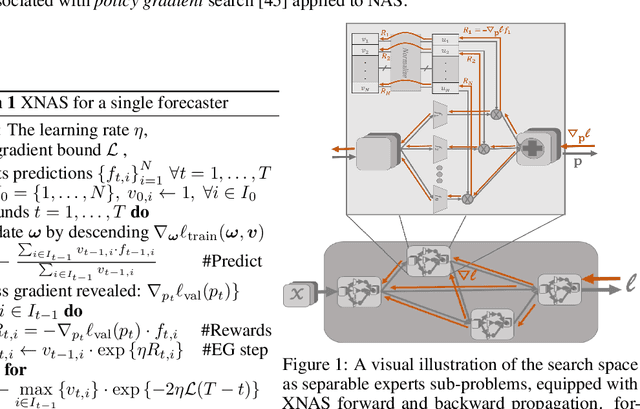
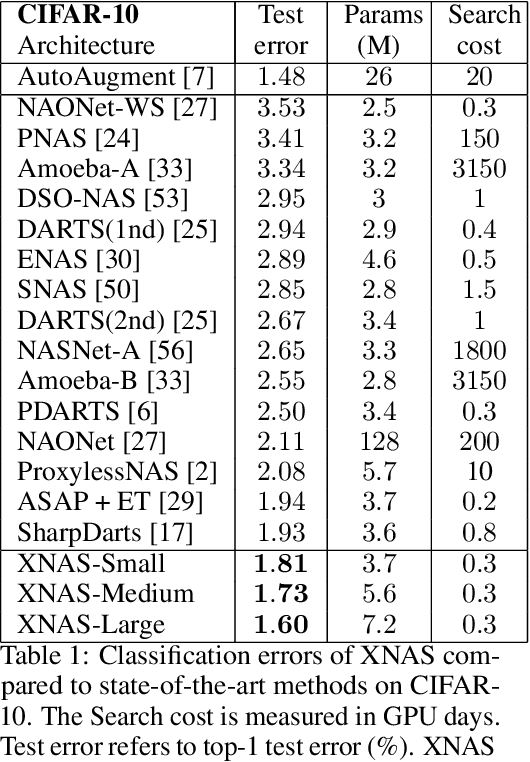
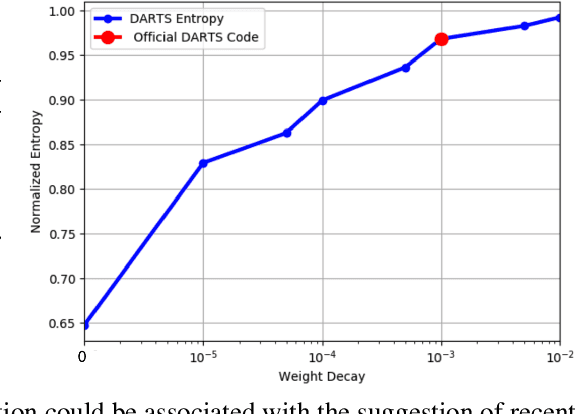
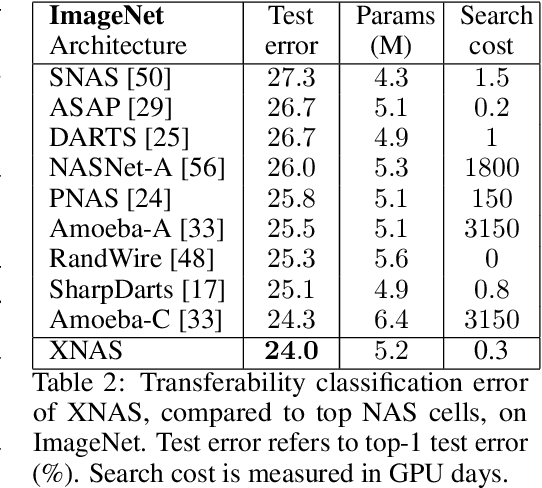
This paper introduces a novel optimization method for differential neural architecture search, based on the theory of prediction with expert advice. Its optimization criterion is well fitted for an architecture-selection, i.e., it minimizes the regret incurred by a sub-optimal selection of operations. Unlike previous search relaxations, that require hard pruning of architectures, our method is designed to dynamically wipe out inferior architectures and enhance superior ones. It achieves an optimal worst-case regret bound and suggests the use of multiple learning-rates, based on the amount of information carried by the backward gradients. Experiments show that our algorithm achieves a strong performance over several image classification datasets. Specifically, it obtains an error rate of 1.6% for CIFAR-10, 24% for ImageNet under mobile settings, and achieves state-of-the-art results on three additional datasets.
ASAP: Architecture Search, Anneal and Prune
Apr 08, 2019
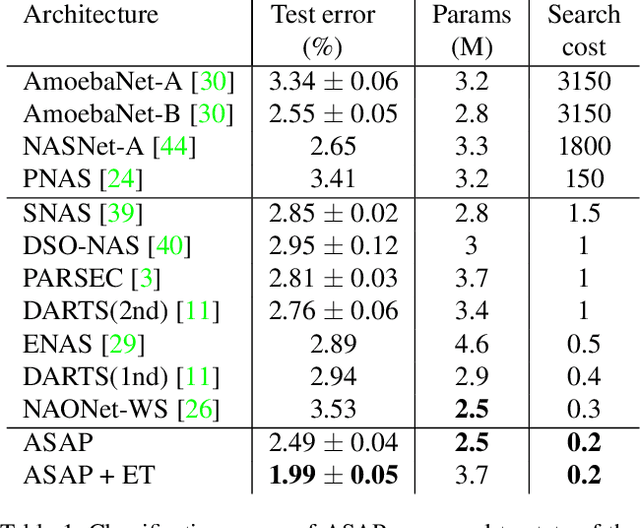
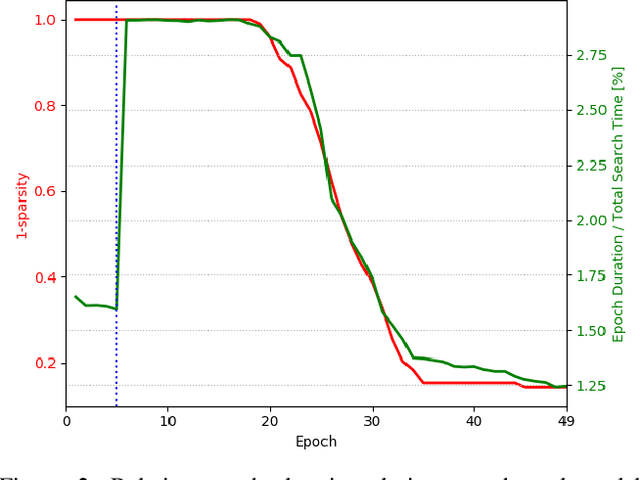
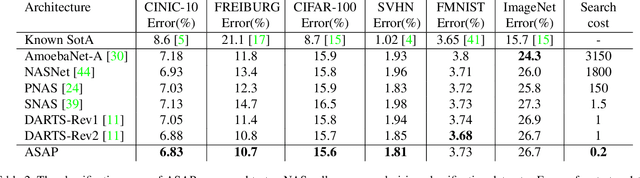
Automatic methods for Neural Architecture Search (NAS) have been shown to produce state-of-the-art network models, yet, their main drawback is the computational complexity of the search process. As some primal methods optimized over a discrete search space, thousands of days of GPU were required for convergence. A recent approach is based on constructing a differentiable search space that enables gradient-based optimization, thus reducing the search time to a few days. While successful, such methods still include some incontinuous steps, e.g., the pruning of many weak connections at once. In this paper, we propose a differentiable search space that allows the annealing of architecture weights, while gradually pruning inferior operations, thus the search converges to a single output network in a continuous manner. Experiments on several vision datasets demonstrate the effectiveness of our method with respect to the search cost, accuracy and the memory footprint of the achieved model.