 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImageNet-21K Pretraining for the Masses
Paper and Code
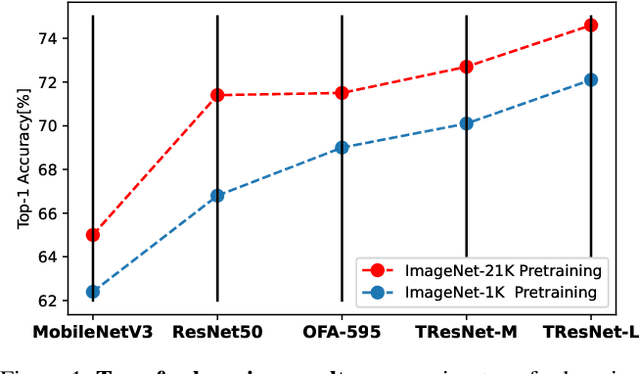

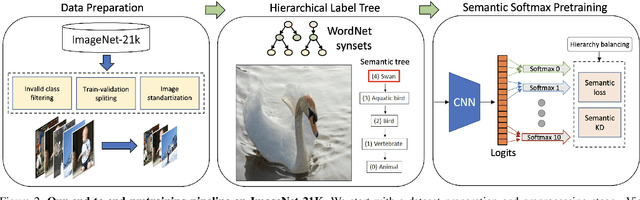
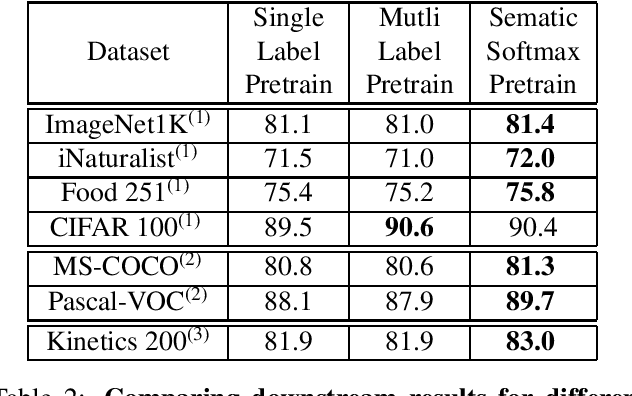
ImageNet-1K serves as the primary dataset for pretraining deep learning models for computer vision tasks. ImageNet-21K dataset, which contains more pictures and classes, is used less frequently for pretraining, mainly due to its complexity, and underestimation of its added value compared to standard ImageNet-1K pretraining. This paper aims to close this gap, and make high-quality efficient pretraining on ImageNet-21K available for everyone. Via a dedicated preprocessing stage, utilizing WordNet hierarchies, and a novel training scheme called semantic softmax, we show that various models, including small mobile-oriented models, significantly benefit from ImageNet-21K pretraining on numerous datasets and tasks. We also show that we outperform previous ImageNet-21K pretraining schemes for prominent new models like ViT. Our proposed pretraining pipeline is efficient, accessible, and leads to SoTA reproducible results, from a publicly available dataset. The training code and pretrained models are available at: https://github.com/Alibaba-MIIL/ImageNet21K