 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure First Detail Next: Image Inpainting with Pyramid Generator
Jun 16, 2021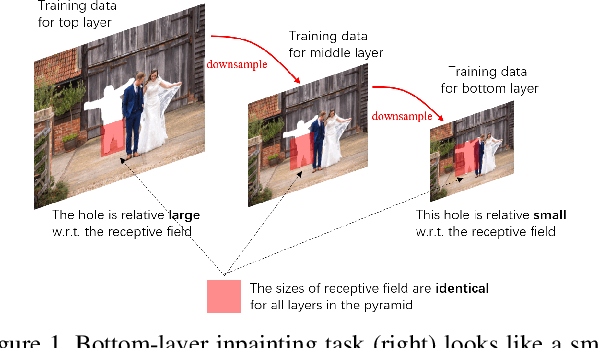

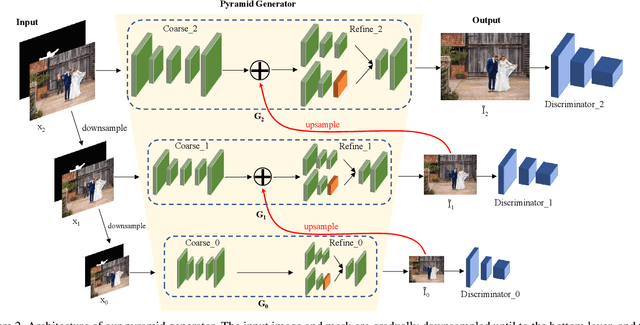
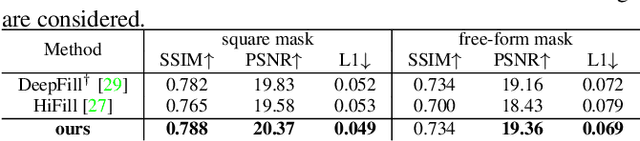
Recent deep generative models have achieved promising performance in image inpainting. However, it is still very challenging for a neural network to generate realistic image details and textures, due to its inherent spectral bias. By our understanding of how artists work, we suggest to adopt a `structure first detail next' workflow for image inpainting. To this end, we propose to build a Pyramid Generator by stacking several sub-generators, where lower-layer sub-generators focus on restoring image structures while the higher-layer sub-generators emphasize image details. Given an input image, it will be gradually restored by going through the entire pyramid in a bottom-up fashion. Particularly, our approach has a learning scheme of progressively increasing hole size, which allows it to restore large-hole images. In addition, our method could fully exploit the benefits of learning with high-resolution images, and hence is suitable for high-resolution image inpainting. Extensive experimental results on benchmark datasets have validated the effectiveness of our approach compared with state-of-the-art methods.
Asymmetric Loss For Multi-Label Classification
Sep 29, 2020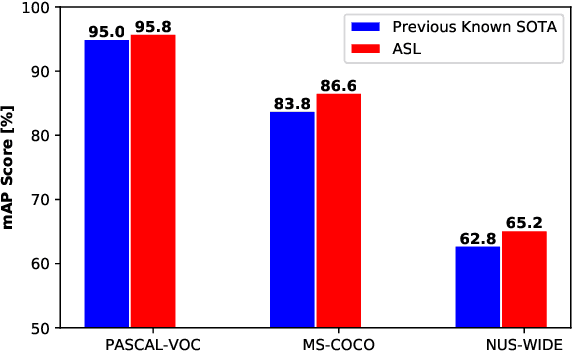
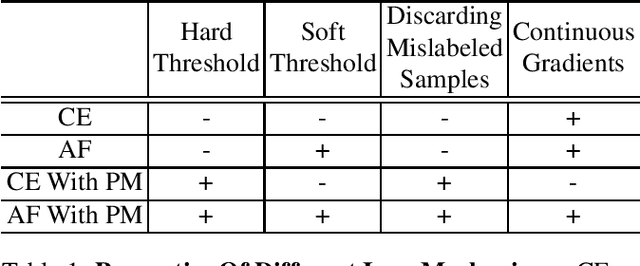
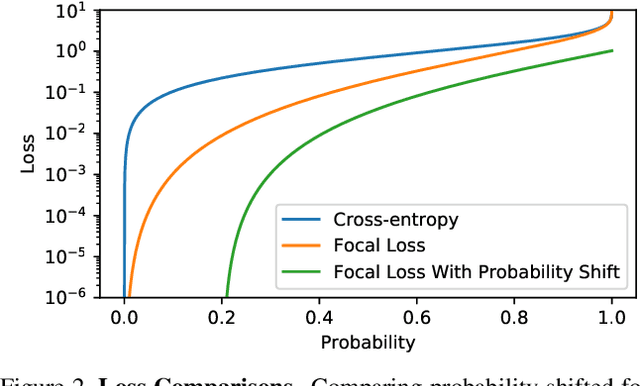
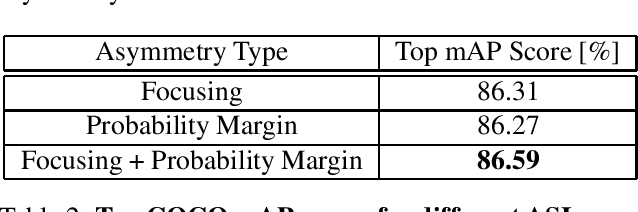
Pictures of everyday life are inherently multi-label in nature. Hence, multi-label classification is commonly used to analyze their content. In typical multi-label datasets, each picture contains only a few positive labels, and many negative ones. This positive-negative imbalance can result in under-emphasizing gradients from positive labels during training, leading to poor accuracy. In this paper, we introduce a novel asymmetric loss ("ASL"), that operates differently on positive and negative samples. The loss dynamically down-weights the importance of easy negative samples, causing the optimization process to focus more on the positive samples, and also enables to discard mislabeled negative samples. We demonstrate how ASL leads to a more "balanced" network, with increased average probabilities for positive samples, and show how this balanced network is translated to better mAP scores, compared to commonly used losses. Furthermore, we offer a method that can dynamically adjust the level of asymmetry throughout the training. With ASL, we reach new state-of-the-art results on three common multi-label datasets, including achieving 86.6% on MS-COCO. We also demonstrate ASL applicability for other tasks such as fine-grain single-label classification and object detection. ASL is effective, easy to implement, and does not increase the training time or complexity. Implementation is available at: https://github.com/Alibaba-MIIL/ASL.
Attention Network Robustification for Person ReID
Oct 29, 2019
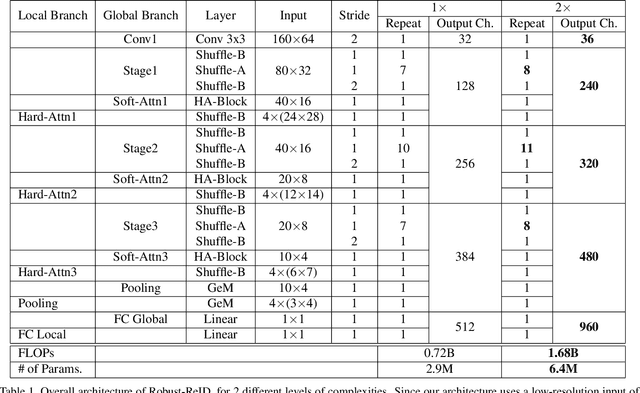
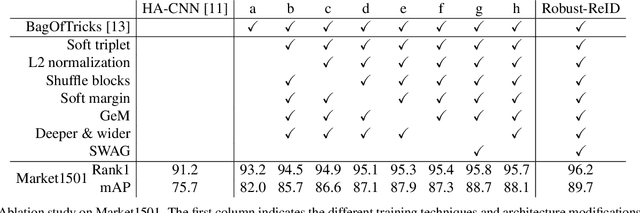
The task of person re-identification (ReID) has attracted growing attention in recent years with improving performance but lack of focus on real-world applications. Most state of the art methods use large pre-trained models, e.g., ResNet50 (~25M parameters), as their backbone, which makes it tedious to explore different architecture modifications. In this study, we focus on small-sized randomly initialized models which enable us to easily introduce network and training modifications suitable for person ReID public datasets and real-world setups. We show the robustness of our network and training improvements by outperforming state of the art results in terms of rank-1 accuracy and mAP on Market1501 (96.2, 89.7) and DukeMTMC (89.8, 80.3) with only 6.4M parameters and without using re-ranking. Finally, we show the applicability of the proposed ReID network for multi-object tracking.
On MMSE and MAP Denoising Under Sparse Representation Modeling Over a Unitary Dictionary
Mar 21, 2010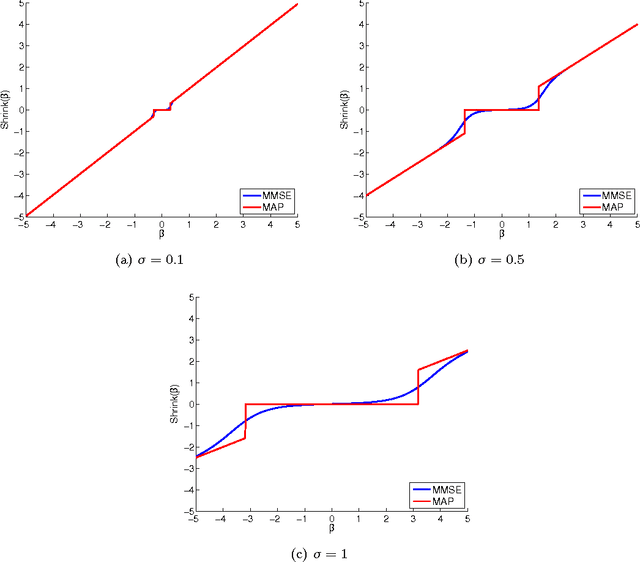
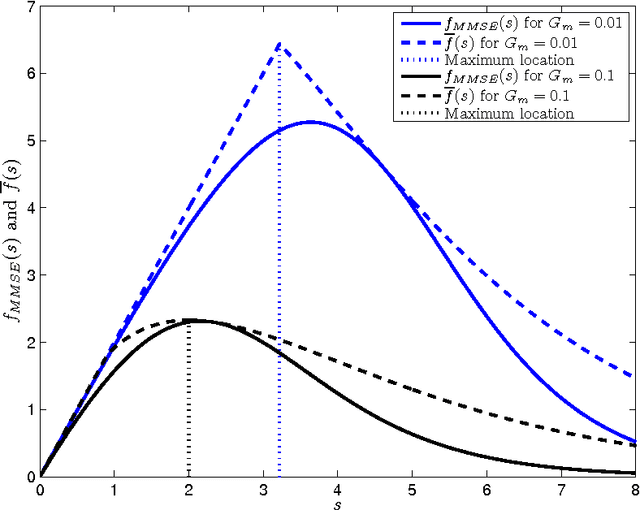
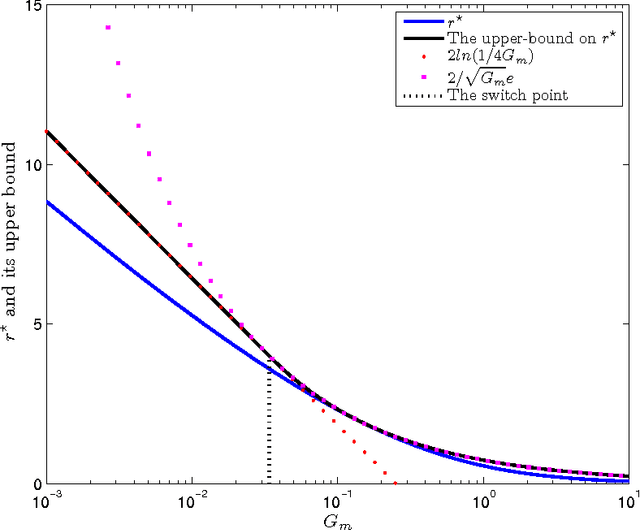
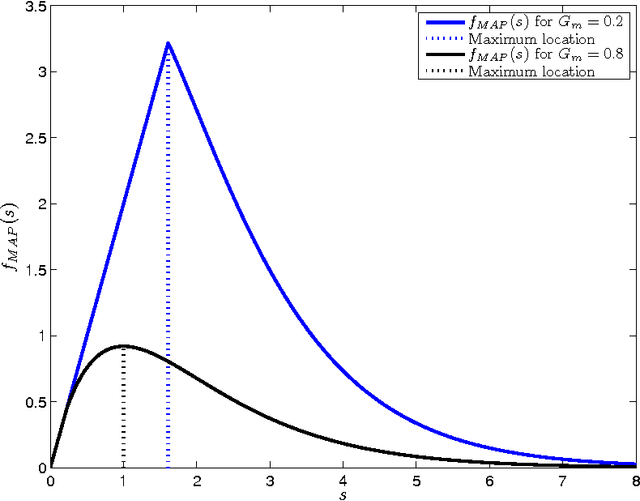
Among the many ways to model signals, a recent approach that draws considerable attention is sparse representation modeling. In this model, the signal is assumed to be generated as a random linear combination of a few atoms from a pre-specified dictionary. In this work we analyze two Bayesian denoising algorithms -- the Maximum-Aposteriori Probability (MAP) and the Minimum-Mean-Squared-Error (MMSE) estimators, under the assumption that the dictionary is unitary. It is well known that both these estimators lead to a scalar shrinkage on the transformed coefficients, albeit with a different response curve. In this work we start by deriving closed-form expressions for these shrinkage curves and then analyze their performance. Upper bounds on the MAP and the MMSE estimation errors are derived. We tie these to the error obtained by a so-called oracle estimator, where the support is given, establishing a worst-case gain-factor between the MAP/MMSE estimation errors and the oracle's performance. These denoising algorithms are demonstrated on synthetic signals and on true data (images).