 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsymmetric Loss For Multi-Label Classification
Paper and Code
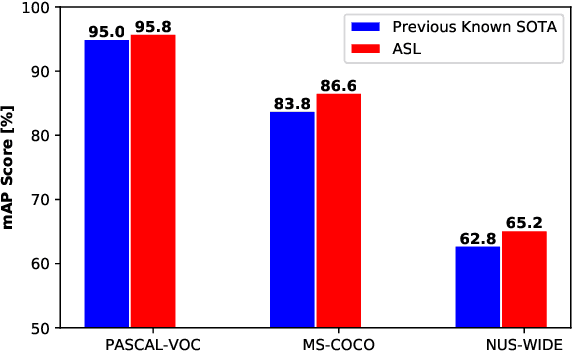
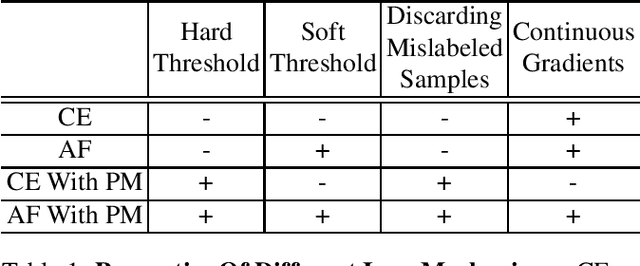
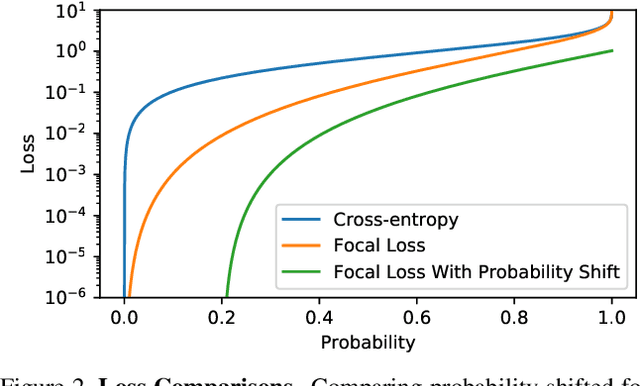
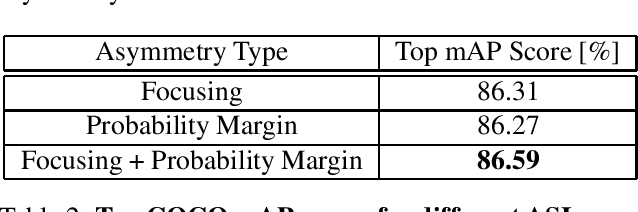
Pictures of everyday life are inherently multi-label in nature. Hence, multi-label classification is commonly used to analyze their content. In typical multi-label datasets, each picture contains only a few positive labels, and many negative ones. This positive-negative imbalance can result in under-emphasizing gradients from positive labels during training, leading to poor accuracy. In this paper, we introduce a novel asymmetric loss ("ASL"), that operates differently on positive and negative samples. The loss dynamically down-weights the importance of easy negative samples, causing the optimization process to focus more on the positive samples, and also enables to discard mislabeled negative samples. We demonstrate how ASL leads to a more "balanced" network, with increased average probabilities for positive samples, and show how this balanced network is translated to better mAP scores, compared to commonly used losses. Furthermore, we offer a method that can dynamically adjust the level of asymmetry throughout the training. With ASL, we reach new state-of-the-art results on three common multi-label datasets, including achieving 86.6% on MS-COCO. We also demonstrate ASL applicability for other tasks such as fine-grain single-label classification and object detection. ASL is effective, easy to implement, and does not increase the training time or complexity. Implementation is available at: https://github.com/Alibaba-MIIL/ASL.